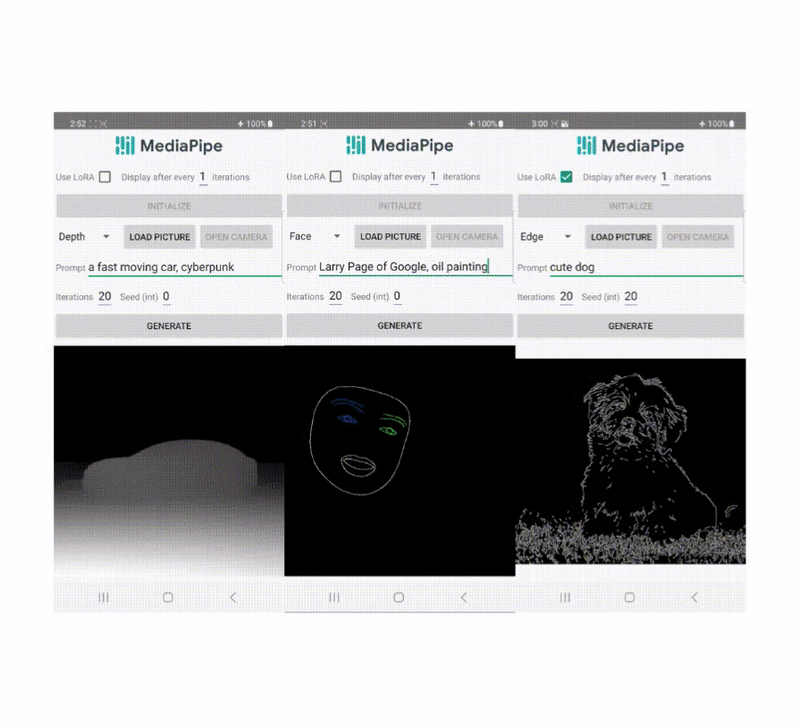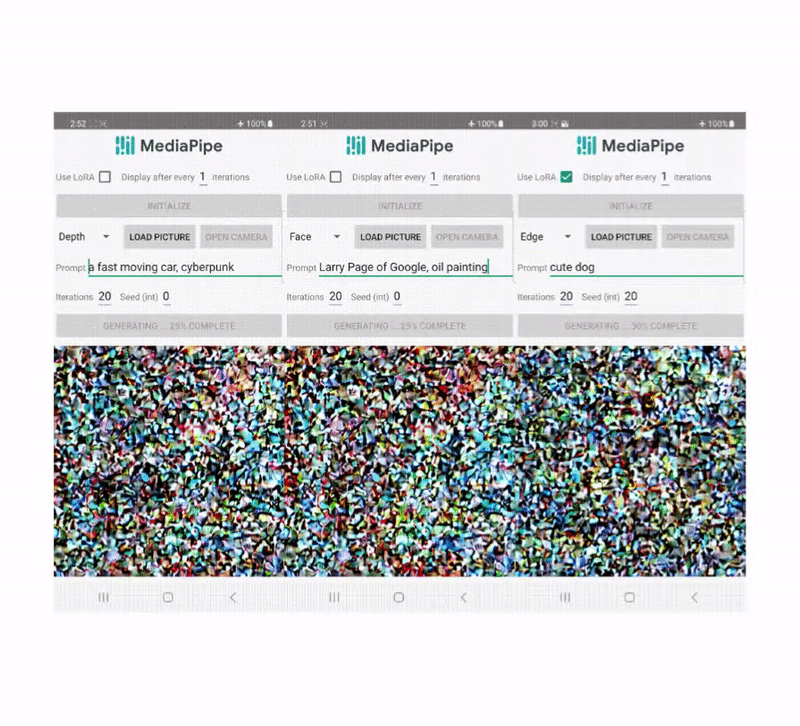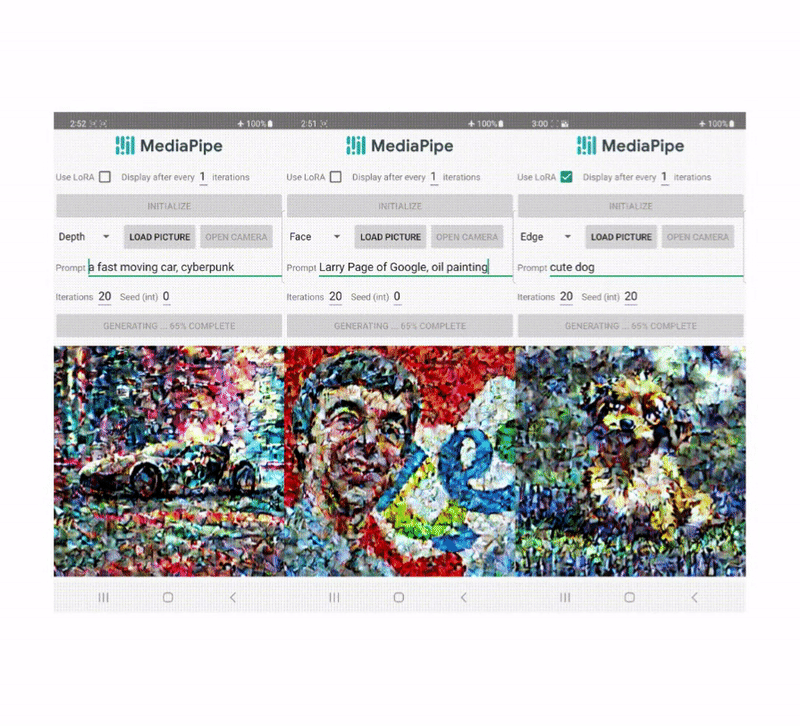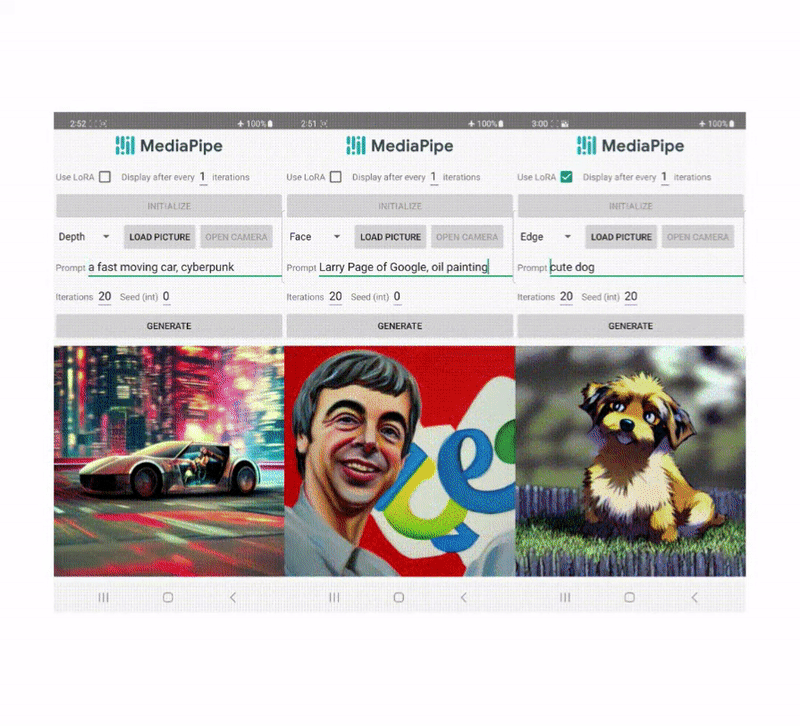
در سالهای اخیر، مدلهای انتشار موفقیت زیادی در تولید متن به تصویر، دستیابی به کیفیت تصویر بالا، بهبود عملکرد استنتاج و گسترش الهامات خلاقانه ما نشان دادهاند. با این وجود، کنترل کارآمد نسل هنوز چالش برانگیز است، به خصوص با شرایطی که توصیف آن با متن دشوار است.
امروز، افزونههای انتشار MediaPipe را معرفی میکنیم که تولید متن به تصویر قابل کنترل را قادر میسازد روی دستگاه اجرا شود. با گسترش کار قبلی خود در مورد استنتاج GPU برای مدلهای تولیدی بزرگ روی دستگاه، راهحلهای کمهزینه جدیدی را برای تولید متن به تصویر قابل کنترل معرفی میکنیم که میتوانند به مدلهای انتشار موجود و انواع تطبیق با رتبه پایین (LoRA) متصل شوند.
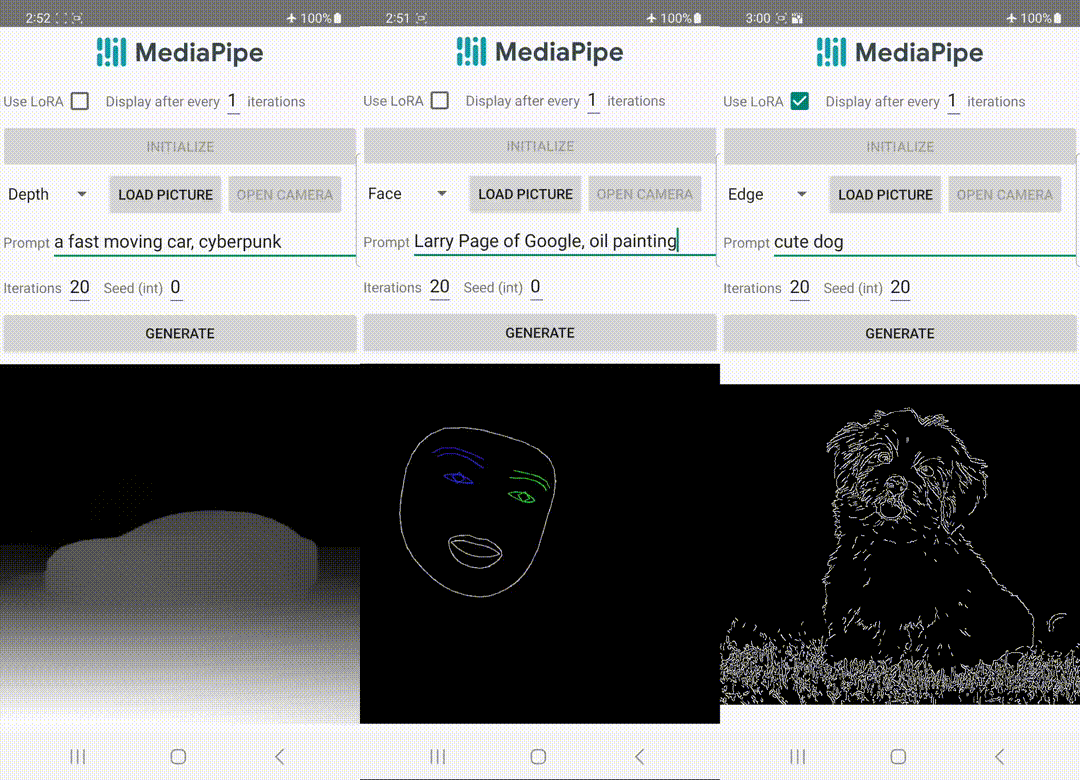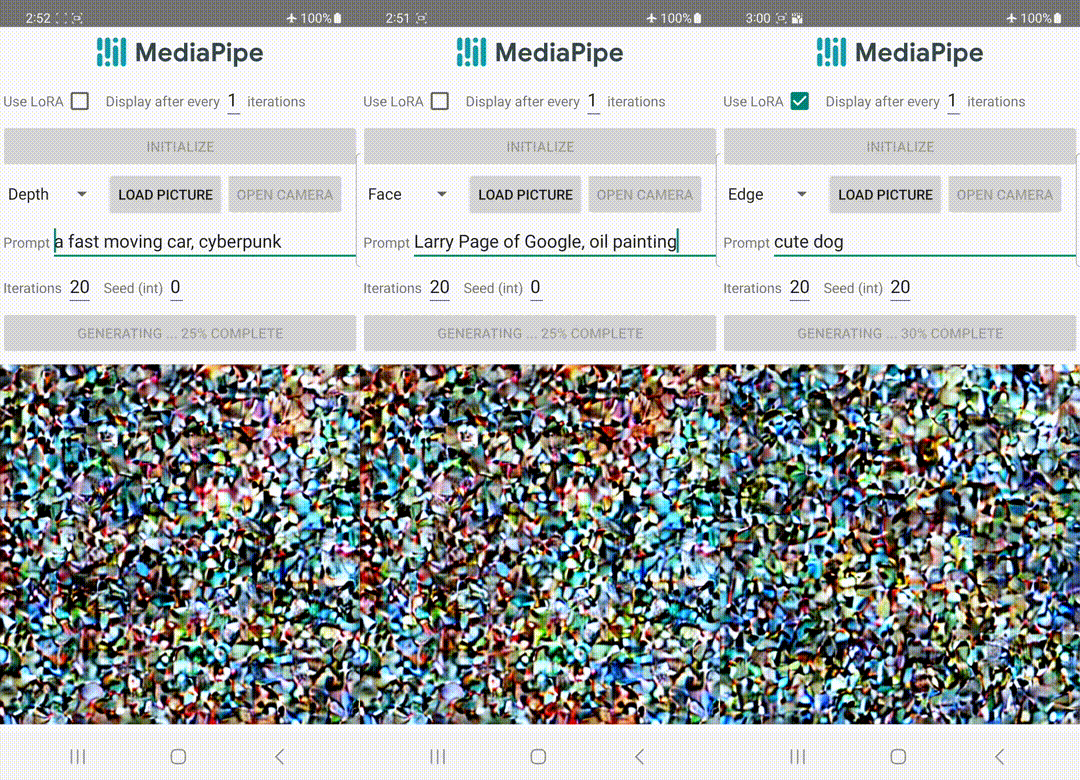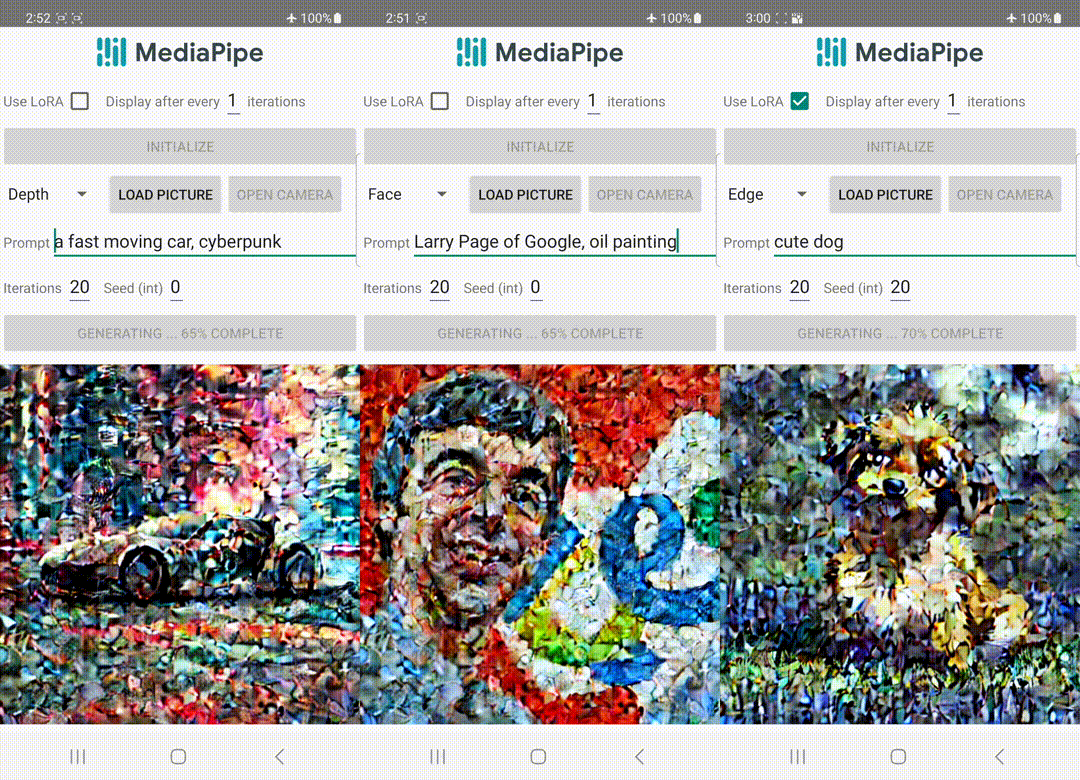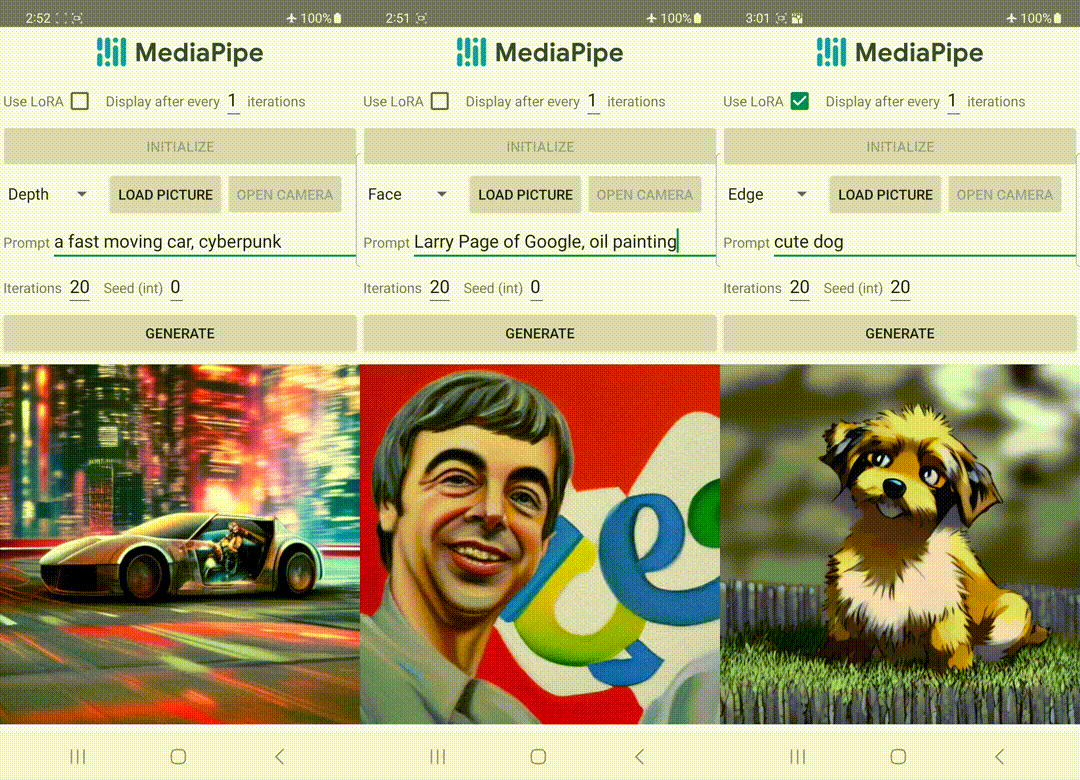 |
| تولید متن به تصویر با پلاگین های کنترلی که روی دستگاه اجرا می شوند. |
زمینه
با مدلهای انتشار، تولید تصویر به عنوان یک فرآیند حذف نویز تکراری مدلسازی میشود. با شروع از یک تصویر نویز، در هر مرحله، مدل انتشار به تدریج تصویر را حذف می کند تا تصویری از مفهوم هدف را نشان دهد. تحقیقات نشان میدهد که درک زبان از طریق پیامهای متنی میتواند تولید تصویر را تا حد زیادی بهبود بخشد. برای تولید متن به تصویر، جاسازی متن از طریق لایه های متقاطع به مدل متصل می شود. با این حال، توصیف برخی از اطلاعات با دستورات متنی دشوار است، به عنوان مثال، موقعیت و وضعیت یک شی. برای رفع این مشکل، محققان مدلهای دیگری را به دیفیوژن اضافه میکنند تا اطلاعات کنترلی را از تصویر وضعیت تزریق کنند.
روشهای رایج برای تولید متن به تصویر کنترلشده عبارتند از Plug-and-Play، ControlNet و T2I Adapter. Plug-and-Play یک رویکرد وارونگی مدل انتشار ضمنی نویز زدایی (DDIM) را اعمال میکند که فرآیند تولید را که از یک تصویر ورودی شروع میشود تا یک ورودی نویز اولیه به دست میآورد، معکوس میکند و سپس یک کپی از مدل انتشار (پارامترهای 860M برای Stable Diffusion) را به کار میگیرد. 1.5) برای رمزگذاری شرایط از یک تصویر ورودی. Plug-and-Play ویژگی های فضایی را با توجه به خود از انتشار کپی شده استخراج می کند و آنها را به انتشار متن به تصویر تزریق می کند. ControlNet یک کپی قابل آموزش از رمزگذار یک مدل انتشار ایجاد می کند، که از طریق یک لایه پیچشی با پارامترهای صفر اولیه برای رمزگذاری اطلاعات شرطی که به لایه های رمزگشا منتقل می شود، متصل می شود. با این حال، در نتیجه، اندازه بزرگ است، نیمی از اندازه مدل انتشار (430M پارامتر برای Stable Diffusion 1.5). آداپتور T2I یک شبکه کوچکتر (پارامترهای 77M) است و اثرات مشابهی را در تولید قابل کنترل به دست می آورد. آداپتور T2I فقط تصویر شرایط را به عنوان ورودی می گیرد و خروجی آن در تمام تکرارهای انتشار به اشتراک گذاشته می شود. با این حال، مدل آداپتور برای دستگاه های قابل حمل طراحی نشده است.
پلاگین های انتشار MediaPipe
برای اینکه تولید شرطی کارآمد، قابل تنظیم و مقیاس پذیر باشد، ما افزونه انتشار MediaPipe را به عنوان یک شبکه جداگانه طراحی می کنیم که عبارتند از:
- قابل اتصال: به راحتی به مدل پایه از پیش آموزش دیده متصل می شود.
- از ابتدا آموزش دیده است: از وزنه های از پیش تمرین شده مدل پایه استفاده نمی کند.
- قابل حمل: در دستگاه های تلفن همراه خارج از مدل پایه اجرا می شود، با هزینه ناچیز در مقایسه با استنتاج مدل پایه.
| روش | اندازه پارامتر | قابل اتصال | از ابتدا | قابل حمل | ||||
| Plug-and-Play | 860M* | ✔️ | ❌ | ❌ | ||||
| ControlNet | 430M* | ✔️ | ❌ | ❌ | ||||
| آداپتور T2I | 77 متر | ✔️ | ✔️ | ❌ | ||||
| پلاگین MediaPipe | 6M | ✔️ | ✔️ | ✔️ |
| مقایسه Plug-and-Play، ControlNet، آداپتور T2I و پلاگین انتشار MediaPipe. * تعداد بسته به مشخصات مدل انتشار متفاوت است. |
پلاگین انتشار MediaPipe یک مدل قابل حمل روی دستگاه برای تولید متن به تصویر است. این ویژگیهای چند مقیاسی را از یک تصویر شرطی استخراج میکند، که به رمزگذار یک مدل انتشار در سطوح مربوطه اضافه میشود. هنگام اتصال به یک مدل انتشار متن به تصویر، مدل پلاگین می تواند سیگنال شرطی اضافی را به تولید تصویر ارائه دهد. ما شبکه پلاگین را به گونه ای طراحی می کنیم که یک مدل سبک وزن با تنها 6 میلیون پارامتر باشد. از پیچیدگی های عمیق و تنگناهای معکوس MobileNetv2 برای استنتاج سریع در دستگاه های تلفن همراه استفاده می کند.
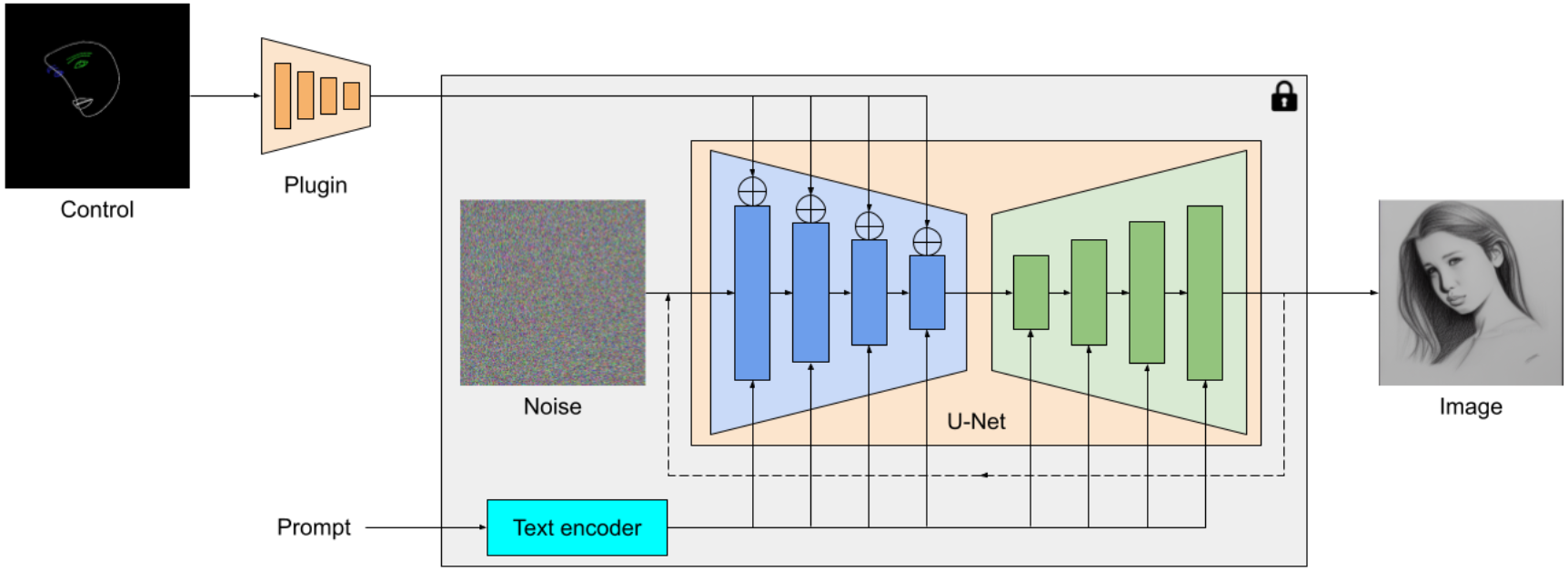 |
| مروری بر پلاگین مدل انتشار MediaPipe. این افزونه یک شبکه جداگانه است که خروجی آن را می توان به یک مدل تولید متن به تصویر از پیش آموزش دیده متصل کرد. ویژگیهای استخراجشده توسط افزونه به لایه پاییننمونهسازی مرتبط مدل انتشار (آبی) اعمال میشود. |
برخلاف ControlNet، ما ویژگیهای کنترلی یکسانی را در همه تکرارهای انتشار تزریق میکنیم. یعنی فقط یک بار افزونه را برای یک تولید تصویر اجرا می کنیم که باعث صرفه جویی در محاسبات می شود. ما برخی از نتایج میانی یک فرآیند انتشار را در زیر نشان میدهیم. کنترل در هر مرحله انتشار موثر است و تولید کنترل شده را حتی در مراحل اولیه امکان پذیر می کند. تکرارهای بیشتر تراز تصویر را با دستور متن بهبود می بخشد و جزئیات بیشتری را ایجاد می کند.
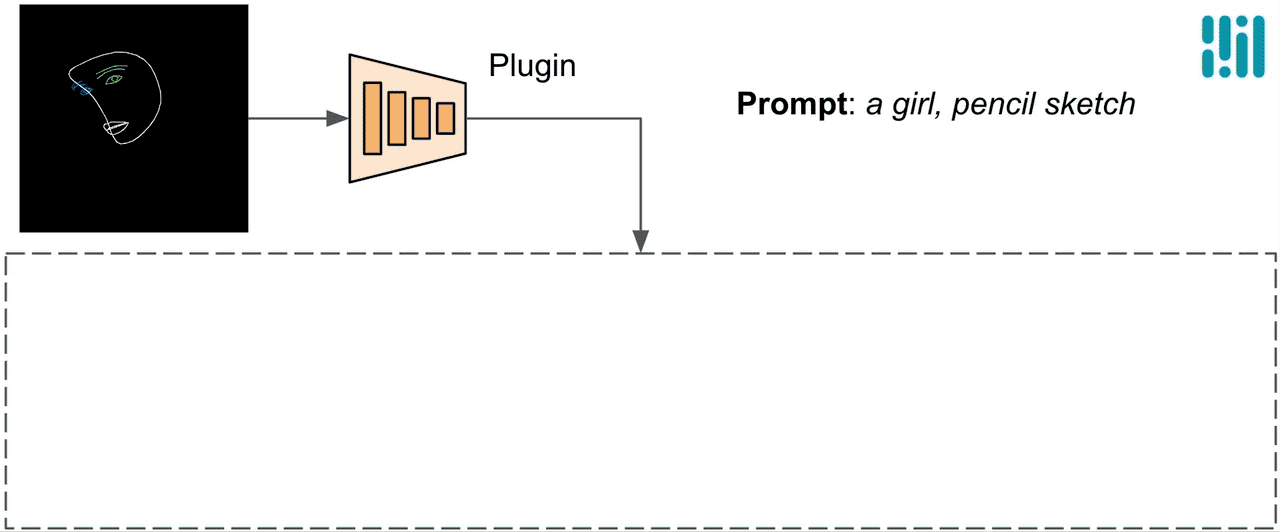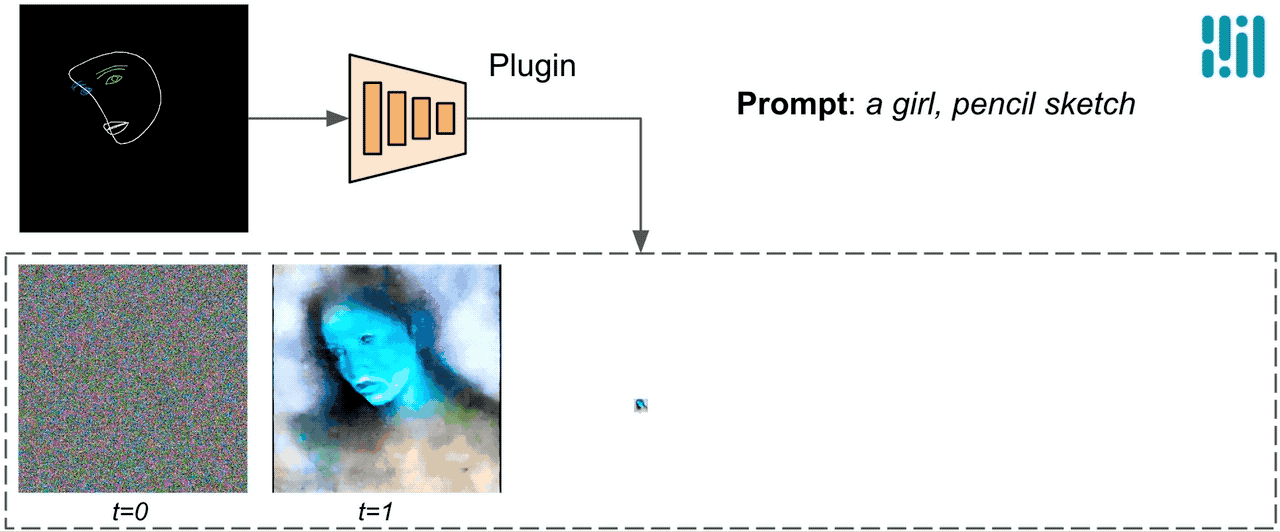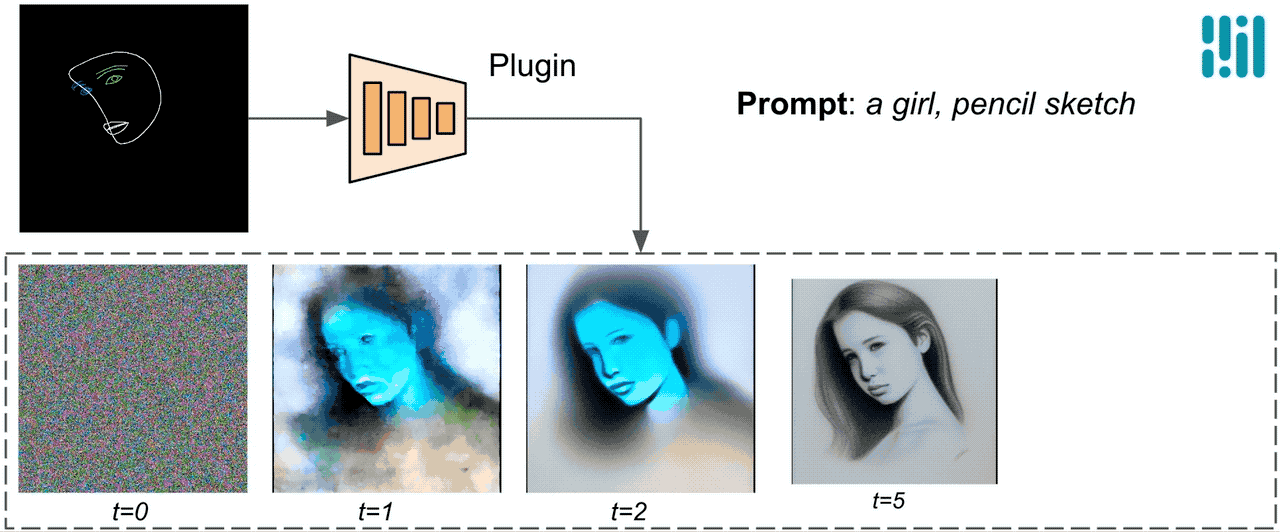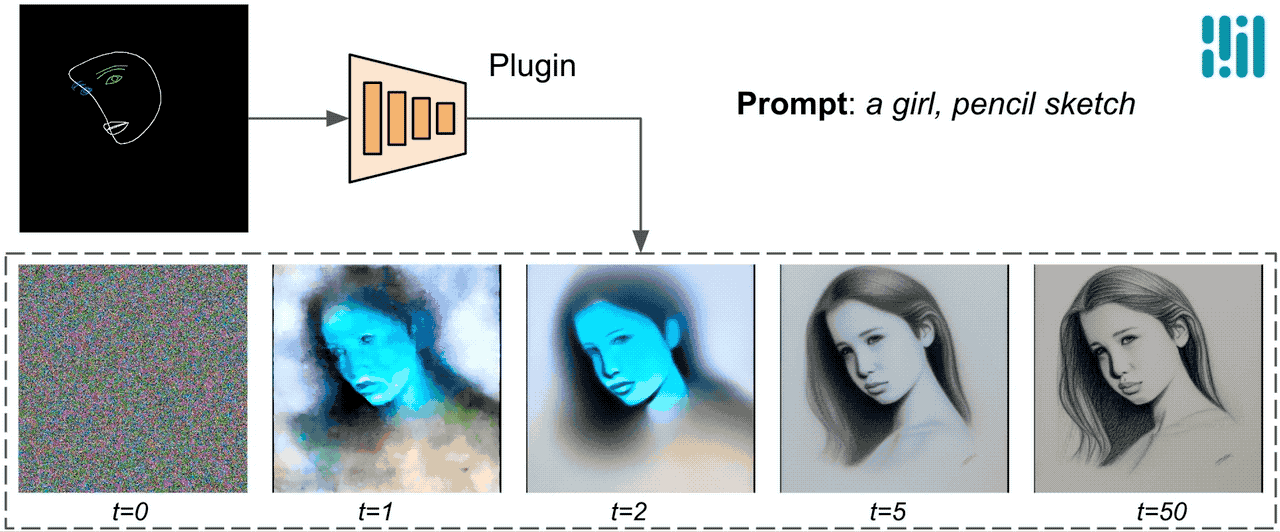 |
| تصویری از فرآیند تولید با استفاده از پلاگین انتشار MediaPipe. |
مثال ها
در این کار، ما افزونههایی را برای مدل تولید متن به تصویر مبتنی بر انتشار با MediaPipe Face Landmark، MediaPipe Holistic Landmark، نقشههای عمق و Canny edge توسعه دادیم. برای هر کار، ما حدود 100 هزار تصویر را از مجموعه داده های تصویر-متن در مقیاس وب انتخاب می کنیم و سیگنال های کنترلی را با استفاده از راه حل های MediaPipe مربوطه محاسبه می کنیم. برای آموزش افزونه ها از زیرنویس های پالایش شده PaLI استفاده می کنیم.
چهره شاخص
وظیفه MediaPipe Face Landmarker 478 نقطه عطف (با توجه) یک چهره انسان را محاسبه می کند. ما از ابزارهای طراحی در MediaPipe برای رندر کردن صورت، از جمله کانتور صورت، دهان، چشم ها، ابروها و عنبیه با رنگ های مختلف استفاده می کنیم. جدول زیر نمونههای تولید شده بهطور تصادفی را با شرطیسازی روی فیس مش و درخواستها نشان میدهد. به عنوان مقایسه، هر دو ControlNet و Plugin می توانند تولید متن به تصویر را با شرایط داده شده کنترل کنند.
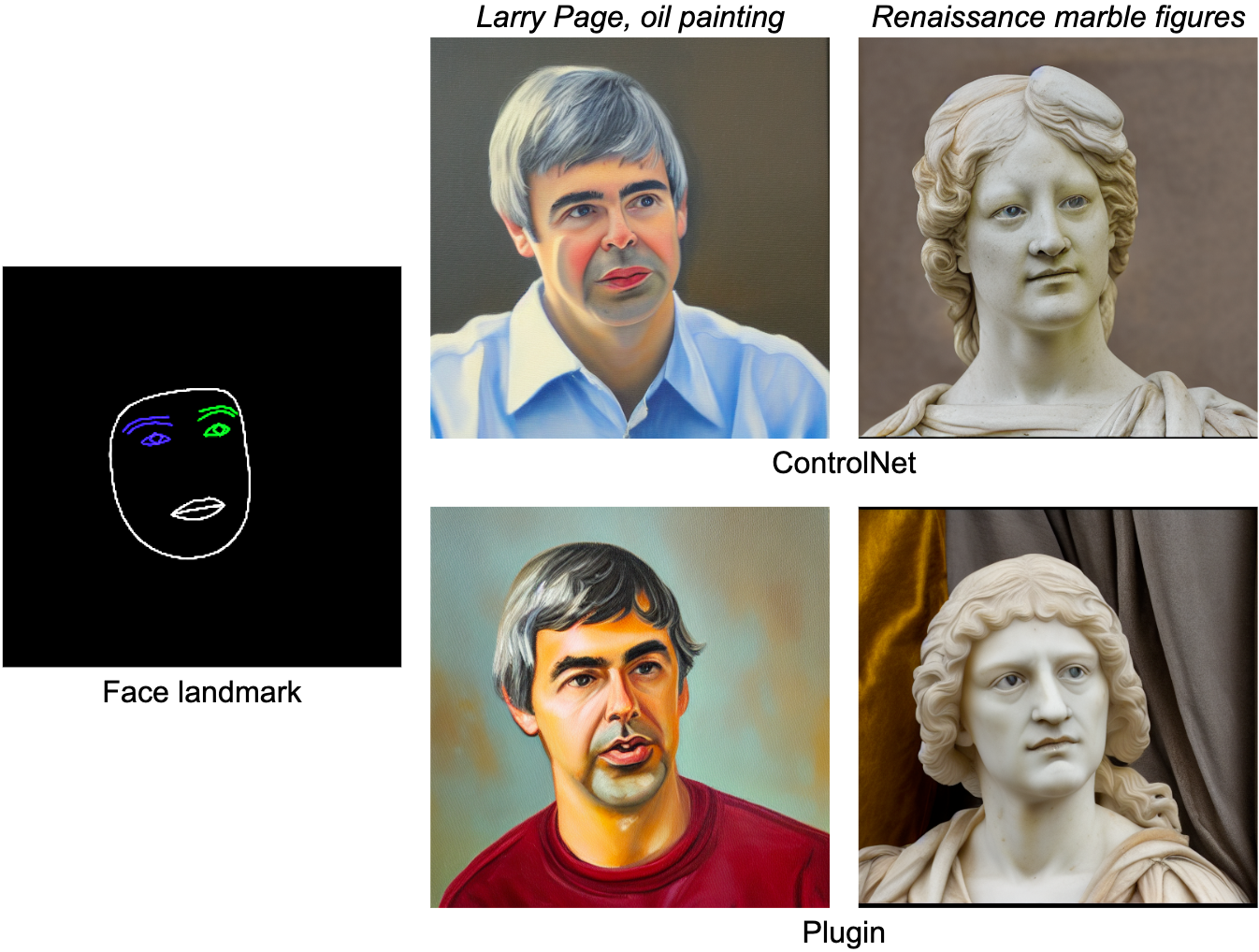 |
| پلاگین چهره برجسته برای تولید متن به تصویر، در مقایسه با ControlNet. |
نقطه عطف کل نگر
وظیفه MediaPipe Holistic Landmarker شامل نشانههای وضعیت بدن، دستها و مش صورت است. در زیر، با شرطی کردن ویژگیهای کل نگر، تصاویر سبکسازی شده مختلفی تولید میکنیم.
 |
| پلاگین کل نگر برای تولید متن به تصویر. |
عمق
 |
| پلاگین عمق برای تولید متن به تصویر. |
Canny Edge
 |
| پلاگین Canny-edge برای تولید متن به تصویر. |
ارزیابی
ما یک مطالعه کمی از نقطه عطف چهره افزونه ای برای نشان دادن عملکرد مدل. مجموعه داده ارزیابی شامل 5K تصاویر انسانی است. ما کیفیت تولید را با معیارهای پرکاربرد، فاصله اولیه فریشت (FID) و امتیازات CLIP مقایسه میکنیم. مدل پایه یک مدل انتشار متن به تصویر از پیش آموزش دیده است. ما در اینجا از Stable Diffusion v1.5 استفاده می کنیم.
همانطور که در جدول زیر نشان داده شده است، هر دو افزونه ControlNet و MediaPipe diffusion کیفیت نمونه بسیار بهتری نسبت به مدل پایه از نظر امتیازات FID و CLIP تولید می کنند. برخلاف ControlNet که باید در هر مرحله انتشار اجرا شود، افزونه MediaPipe فقط یک بار برای هر تصویر تولید شده اجرا می شود. ما عملکرد سه مدل را روی یک ماشین سرور (با پردازنده گرافیکی Nvidia V100) و یک تلفن همراه (Galaxy S23) اندازهگیری کردیم. در سرور، هر سه مدل را با 50 مرحله انتشار اجرا می کنیم و در موبایل، 20 مرحله انتشار را با استفاده از برنامه تولید تصویر MediaPipe اجرا می کنیم. در مقایسه با ControlNet، افزونه MediaPipe مزیت آشکاری در کارایی استنتاج و حفظ کیفیت نمونه نشان میدهد.
| مدل | FID↓ | CLIP↑ | زمان استنتاج | |||||
| Nvidia V100 | گلکسی اس 23 | |||||||
| پایه | 10.32 | 0.26 | 5.0 | 11.5 | ||||
| Base + ControlNet | 6.51 | 0.31 | 7.4 (+48%) | 18.2 (+58.3%) | ||||
| پلاگین Base + MediaPipe | 6.50 | 0.30 | 5.0 (+0.2%) | 11.8 (+2.6%) | ||||
| مقایسه کمی در FID، CLIP، و زمان استنتاج. |
ما عملکرد افزونه را بر روی طیف گسترده ای از دستگاه های تلفن همراه از سطح متوسط تا سطح بالا آزمایش می کنیم. ما نتایج را در برخی از دستگاههای نماینده در جدول زیر فهرست میکنیم که هم اندروید و هم iOS را پوشش میدهند.
| دستگاه | اندروید | iOS | ||||||||||
| پیکسل 4 | پیکسل 6 | پیکسل 7 | گلکسی اس 23 | آیفون 12 پرو | آیفون 13 پرو | |||||||
| زمان (اماس) | 128 | 68 | 50 | 48 | 73 | 63 | ||||||
| زمان استنتاج (میلیثانیه) افزونه در دستگاههای تلفن همراه مختلف. |
نتیجه
در این کار، MediaPipe، یک پلاگین قابل حمل برای تولید متن به تصویر شرطی شده را ارائه می دهیم. ویژگی های استخراج شده از یک تصویر شرایط را به یک مدل انتشار تزریق می کند و در نتیجه تولید تصویر را کنترل می کند. پلاگین های قابل حمل را می توان به مدل های انتشار از پیش آموزش دیده ای که روی سرورها یا دستگاه ها اجرا می شوند متصل کرد. با اجرای تولید متن به تصویر و افزونه ها به طور کامل روی دستگاه، ما برنامه های کاربردی انعطاف پذیرتری از هوش مصنوعی مولد را فعال می کنیم.
قدردانی
مایلیم از همه اعضای تیم که در این کار مشارکت داشتند تشکر کنیم: رامان ساروکین و جوهیون لی برای راه حل استنتاج GPU. خان لویت، چو لینگ چانگ، آندری کولیک و ماتیاس گروندمن برای رهبری. تشکر ویژه از Jiuqiang Tang، جو زو و لو وانگ، که این فناوری و تمام دموها را روی دستگاه اجرا کرده است.