مدلهای زبان بصری پیشآموزشی (VL) بر روی مجموعهدادههای زیرنویس تصویر در مقیاس وب اخیراً بهعنوان یک جایگزین قدرتمند برای پیشآموزش سنتی در دادههای طبقهبندی تصویر ظاهر شده است. مجموعه دادههای تصویر-کپشن بیشتر «دامنه باز» در نظر گرفته میشوند، زیرا حاوی انواع صحنهها و لغات گستردهتر هستند، که منجر به مدلهایی با عملکرد قوی در وظایف تشخیص عکسهای کم و صفر میشود. با این حال، تصاویر با توصیف کلاسهای ریز میتوانند نادر باشند، و توزیع کلاس میتواند نامتعادل باشد، زیرا مجموعه دادههای تصویر-کپشن از طریق تنظیم دستی انجام نمیشوند. در مقابل، مجموعه دادههای طبقهبندی در مقیاس بزرگ، مانند ImageNet، اغلب تنظیم شدهاند و بنابراین میتوانند دستههای ریز دانه را با توزیع برچسب متعادل ارائه دهند. اگرچه ممکن است امیدوارکننده به نظر برسد، اما ترکیب مستقیم مجموعه دادههای زیرنویس و طبقهبندی برای پیشآموزش اغلب ناموفق است، زیرا میتواند منجر به نمایشهای مغرضانهای شود که به خوبی به وظایف مختلف پایین دست تعمیم نمییابند.
در «پیوند شرطیسازی، نظارت بر زبان و برچسب را یکسان میکند»، که در CVPR 2023 ارائه شد، یک استراتژی پیشآموزشی را نشان میدهیم که از مجموعه دادههای طبقهبندی و شرح برای ارائه مزایای تکمیلی استفاده میکند. اول، ما نشان میدهیم که یکسان سازی ساده مجموعه دادهها منجر به عملکرد زیر بهینه در وظایف تشخیص صفر شات پایین دستی میشود، زیرا مدل تحت تأثیر سوگیری مجموعه دادهها قرار میگیرد: پوشش حوزههای تصویر و کلمات واژگان در هر مجموعه داده متفاوت است. ما این مشکل را در طول آموزش از طریق حل می کنیم شرطی سازی پیشوند، یک روش ساده و مؤثر جدید است که از نشانه های پیشوند برای جدا کردن سوگیری های مجموعه داده از مفاهیم بصری استفاده می کند. این رویکرد به رمزگذار زبان اجازه می دهد تا از هر دو مجموعه داده یاد بگیرد و در عین حال استخراج ویژگی را برای هر مجموعه داده تنظیم کند. شرطیسازی پیشوندی یک روش عمومی است که میتواند به راحتی با اهداف پیشآموزشی VL موجود، مانند پیشآموزش زبان-تصویر متضاد (CLIP) یا یادگیری متضاد یکپارچه (UniCL) ادغام شود.
ایده سطح بالا
توجه میکنیم که مجموعه دادههای طبقهبندی حداقل به دو صورت تمایل دارند: (1) تصاویر عمدتاً حاوی اشیاء منفرد از حوزههای محدود هستند و (2) واژگان محدود است و فاقد انعطافپذیری زبانی مورد نیاز برای یادگیری صفر شات است. به عنوان مثال، تعبیه کلاس “عکس یک سگ” بهینه شده برای ImageNet معمولاً منجر به عکس یک سگ در مرکز تصویر می شود که از مجموعه داده ImageNet کشیده می شود، که به خوبی به مجموعه داده های دیگر حاوی تصاویر چندین سگ تعمیم نمی یابد. در مکان های مختلف فضایی یا سگ با موضوعات دیگر.
در مقابل، مجموعه دادههای شرح شامل انواع وسیعتری از انواع صحنه و واژگان است. همانطور که در زیر نشان داده شده است، اگر یک مدل به سادگی از دو مجموعه داده یاد بگیرد، تعبیه زبان می تواند بایاس از طبقه بندی تصویر و مجموعه داده عنوان را درهم ببندد، که می تواند تعمیم در طبقه بندی عکس صفر را کاهش دهد. اگر بتوانیم تعصب را از دو مجموعه داده جدا کنیم، میتوانیم از جاسازیهای زبانی استفاده کنیم که برای مجموعه داده شرح طراحی شده است تا تعمیمسازی را بهبود بخشد.
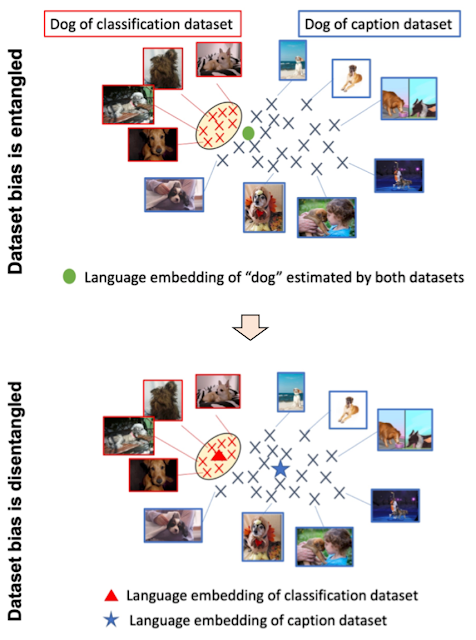 |
| بالا: تعبیه زبانی که سوگیری از طبقهبندی تصویر و مجموعه داده شرح را درگیر میکند. پایین: تعبیههای زبان، تعصب را از دو مجموعه داده جدا میکند. |
شرطی سازی پیشوند
شرطیسازی پیشوند تا حدی از تنظیم سریع الهام گرفته شده است، که توکنهای قابل یادگیری را به دنبالههای توکن ورودی اضافه میکند تا به یک ستون فقرات مدل از پیش آموزشدیده دستور دهد تا دانش خاص کار را یاد بگیرد که میتواند برای حل وظایف پاییندستی استفاده شود. رویکرد شرطیسازی پیشوند از دو جهت با تنظیم سریع متفاوت است: (1) برای یکپارچهسازی مجموعههای دادههای دستهبندی و شرح تصویر با جدا کردن سوگیری مجموعه دادهها طراحی شده است، و (2) برای پیشآموزش VL در حالی که تنظیم سریع استاندارد استاندارد است، اعمال میشود. برای تنظیم دقیق مدل ها استفاده می شود. شرطیسازی پیشوند روشی صریح برای هدایت رفتار ستونهای مدل بر اساس نوع مجموعه دادههای ارائهشده توسط کاربران است. این به ویژه در تولید زمانی مفید است که تعداد انواع مختلف مجموعه داده ها از قبل مشخص باشد.
در طول آموزش، شرطیسازی پیشوند یک نشانه متنی (نشانه پیشوند) را برای هر نوع مجموعه داده میآموزد، که سوگیری مجموعه داده را جذب میکند و به نشانههای متن باقیمانده اجازه میدهد تا بر یادگیری مفاهیم بصری تمرکز کنند. به طور خاص، نشانههای پیشوندی را برای هر نوع مجموعه داده به نشانههای ورودی اضافه میکند که زبان و رمزگذار تصویری را از نوع داده ورودی (مثلاً طبقهبندی در مقابل عنوان) مطلع میکند. نشانههای پیشوندی برای یادگیری تعصب خاص نوع مجموعه داده آموزش دیدهاند، که ما را قادر میسازد این سوگیری را در بازنمایی زبان از هم جدا کنیم و از تعبیههای آموختهشده در مجموعه داده تصویر-تصویر در طول زمان تست، حتی بدون عنوان ورودی، استفاده کنیم.
ما از شرطی سازی پیشوند برای CLIP با استفاده از زبان و رمزگذار بصری استفاده می کنیم. در طول زمان آزمایش، ما از پیشوند مورد استفاده برای مجموعه داده تصویر-کپشن استفاده میکنیم، زیرا قرار است مجموعه دادهها انواع صحنههای گستردهتر و کلمات واژگان را پوشش دهد، که منجر به عملکرد بهتر در تشخیص عکس صفر میشود.
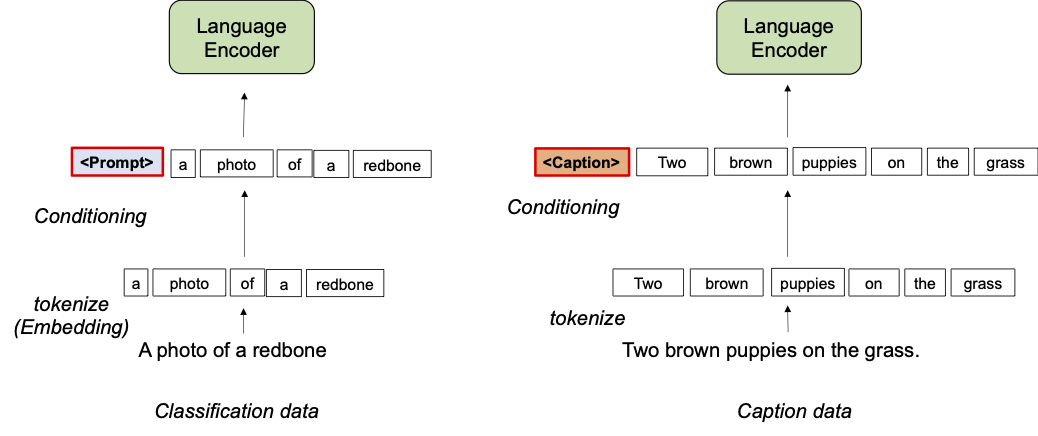 |
| تصویر تهویه پیشوند. |
نتایج تجربی
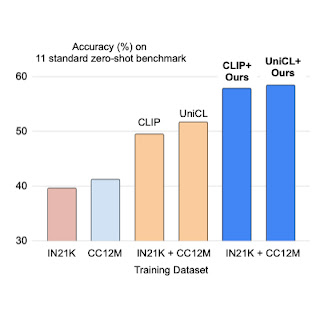
ما شرطیسازی پیشوند را برای دو نوع از دست دادن کنتراست، CLIP و UniCL اعمال میکنیم و عملکرد آنها را در وظایف تشخیص شات صفر در مقایسه با مدلهای آموزشدیده شده با ImageNet21K (IN21K) و مفهومی 12M (CC12M) ارزیابی میکنیم. مدلهای CLIP و UniCL که با دو مجموعه داده با استفاده از شرطیسازی پیشوندی آموزش داده شدهاند، پیشرفتهای زیادی در دقت طبقهبندی شات صفر نشان میدهند.
 |
| دقت طبقهبندی شات صفر مدلهایی که فقط با IN21K یا CC12M آموزش داده شدهاند در مقایسه با مدلهای CLIP و UniCL که با هر دو مجموعه داده با استفاده از شرطیسازی پیشوند (“ما”) آموزش دیدهاند. |
مطالعه بر روی پیشوند زمان آزمون
جدول زیر تغییر عملکرد با پیشوند مورد استفاده در زمان تست را توضیح می دهد. ما نشان میدهیم که با استفاده از همان پیشوند مورد استفاده برای مجموعه داده طبقهبندی (“Prompt”)، عملکرد مجموعه داده طبقهبندی (IN-1K) بهبود مییابد. هنگام استفاده از پیشوند یکسانی که برای مجموعه داده تصویر-کپشن (“Caption”) استفاده می شود، عملکرد در مجموعه داده های دیگر (Zero-shot AVG) بهبود می یابد. این تجزیه و تحلیل نشان میدهد که اگر پیشوند برای مجموعه داده تصویر-کپشن تنظیم شود، به تعمیم بهتر انواع صحنه و کلمات واژگان دست مییابد.
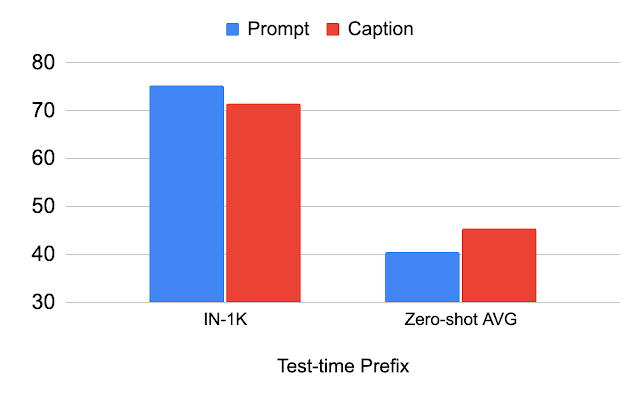 |
| تجزیه و تحلیل پیشوند مورد استفاده برای آزمون زمان. |
مطالعه روی استحکام به تغییر توزیع تصویر
ما تغییر در توزیع تصویر را با استفاده از انواع ImageNet مطالعه می کنیم. می بینیم که پیشوند “Caption” در ImageNet-R (IN-R) و ImageNet-Sketch (IN-S) بهتر از “Prompt” عمل می کند، اما در ImageNet-V2 (IN-V2) عملکرد کمتری دارد. این نشان می دهد که پیشوند “Caption” در دامنه های دور از مجموعه داده طبقه بندی تعمیم می یابد. بنابراین، پیشوند بهینه احتمالاً با فاصله دامنه آزمایشی از مجموعه داده طبقه بندی متفاوت است.
 |
| تجزیه و تحلیل در مورد استحکام به تغییر توزیع در سطح تصویر. IN: ImageNet، IN-V2: ImageNet-V2، IN-R: Art، ImageNet سبک کارتونی، IN-S: ImageNet Sketch. |
نتیجه گیری و کار آینده
ما شرطیسازی پیشوند را معرفی میکنیم، تکنیکی برای یکپارچهسازی مجموعههای دادههای زیرنویس و طبقهبندی تصویر برای طبقهبندی بهتر عکس صفر. ما نشان میدهیم که این رویکرد به دقت طبقهبندی صفر شات بهتر منجر میشود و این پیشوند میتواند تعصب در تعبیه زبان را کنترل کند. یک محدودیت این است که پیشوند آموخته شده در مجموعه داده عنوان لزوما برای طبقه بندی صفر شات بهینه نیست. شناسایی پیشوند بهینه برای هر مجموعه داده آزمایشی یک جهت جالب برای کار آینده است.
سپاسگزاریها
این تحقیق توسط Kuniaki Saito، Kihyuk Sohn، Xiang Zhang، Chun-Liang Li، Chen-Yu Lee، Kate Saenko و Tomas Pfister انجام شد. با تشکر از Zizhao Zhang و Sergey Ioffe برای بازخورد ارزشمندشان.