
در عصر دیجیتال امروزی، گوشی های هوشمند و مرورگرهای وب دسکتاپ به عنوان ابزار اصلی برای دسترسی به اخبار و اطلاعات عمل می کنند. با این حال، گسترش بی نظمی وب سایت – شامل طرح بندی های پیچیده، عناصر ناوبری و پیوندهای خارجی – به طور قابل توجهی هم تجربه خواندن و هم ناوبری مقاله را مختل می کند. این موضوع به ویژه برای افرادی که شرایط دسترسی دارند بسیار حاد است.
برای بهبود تجربه کاربر و دسترسی بیشتر به خواندن، کاربران Android و Chrome ممکن است از ویژگی Reading Mode استفاده کنند، که با پردازش صفحات وب، دسترسی را افزایش میدهد تا کنتراست قابل تنظیم، اندازه متن قابل تنظیم، فونتهای خواناتر و فعال کردن ابزارهای تبدیل متن به گفتار را فراهم کند. . علاوه بر این، حالت خواندن اندروید برای استخراج محتوا از برنامه ها مجهز شده است. گسترش حالت خواندن برای در بر گرفتن طیف وسیعی از محتوا و بهبود عملکرد آن، در حالی که هنوز به صورت محلی بر روی دستگاه کاربر بدون انتقال دادههای خارجی کار میکند، چالشی منحصربهفرد ایجاد میکند.
برای گسترش قابلیتهای Reading Mode بدون به خطر انداختن حریم خصوصی، یک مدل جدید تقطیر محتوای روی دستگاه ایجاد کردهایم. برخلاف تلاشهای اولیه با استفاده از DOM Distiller – یک رویکرد اکتشافی محدود به مقالات خبری – مدل ما هم از نظر کیفیت و هم از نظر تنوع در انواع مختلف محتوا برتر است. ما اطمینان می دهیم که محتوای مقاله از محدوده محیط محلی خارج نمی شود. مدل تقطیر محتوای روی دستگاه ما به آرامی محتوای طولانی را به یک طرح ساده و قابل تنظیم برای سفر خواندن دلپذیرتر تبدیل میکند و در عین حال از رویکردهای جایگزین پیشرو نیز بهتر عمل میکند. در اینجا ما جزئیات این تحقیق را بررسی می کنیم که رویکرد، روش شناسی و نتایج خود را برجسته می کند.
گراف شبکه های عصبی
به جای تکیه بر اکتشافیهای پیچیده که نگهداری و مقیاسبندی آنها به انواع طرحبندی مقاله دشوار است، به این کار به عنوان یک مشکل یادگیری کاملاً نظارت شده نزدیک میشویم. این رویکرد مبتنی بر داده به مدل اجازه میدهد تا در طرحبندیهای مختلف، بدون محدودیت و شکنندگی اکتشافی، بهتر تعمیم یابد. کارهای قبلی برای بهینهسازی تجربه خواندن متکی به HTML یا تجزیه، فیلتر کردن و مدلسازی یک مدل شی سند (DOM)، یک رابط برنامهنویسی است که به طور خودکار توسط مرورگر وب کاربر از HTML سایت تولید میشود که ساختار یک سند را نشان میدهد و به آن اجازه میدهد دستکاری شود.
مدل جدید Reading Mode بر درختهای دسترسپذیری تکیه دارد که نمایش سادهتر و در دسترستری از DOM ارائه میدهد. درختان دسترسپذیری بهطور خودکار از درخت DOM تولید میشوند و توسط فناوریهای کمکی استفاده میشوند تا افراد دارای معلولیت بتوانند با محتوای وب تعامل داشته باشند. اینها در مرورگر وب Chrome و در Android از طریق اشیاء AccessibilityNodeInfo در دسترس هستند که هم برای WebView و هم برای محتوای برنامه اصلی ارائه شدهاند.
ما با جمع آوری دستی و حاشیه نویسی درختان دسترسی شروع کردیم. مجموعه داده Android مورد استفاده برای این پروژه به ترتیب 10 هزار نمونه برچسب گذاری شده را شامل می شود، در حالی که مجموعه داده Chrome شامل تقریباً 100 هزار نمونه برچسب گذاری شده است. ما ابزار جدیدی را توسعه دادیم که از شبکههای عصبی گراف (GNN) برای استخراج محتوای ضروری از درختان دسترسی با استفاده از یک رویکرد یادگیری نظارت شده چند طبقه استفاده میکند. مجموعه داده ها شامل مقالات طولانی است که از وب نمونه برداری شده و با کلاس هایی مانند عنوان، پاراگراف، تصاویر، تاریخ انتشار و غیره برچسب گذاری شده اند.
GNN ها یک انتخاب طبیعی برای برخورد با ساختارهای داده درخت مانند هستند، زیرا بر خلاف مدل های سنتی که اغلب ویژگی های دقیق و دست ساز را برای درک چیدمان و پیوندهای درون چنین درختانی می طلبند، GNN ها این ارتباطات را به طور طبیعی یاد می گیرند. برای نشان دادن این موضوع، قیاس یک شجره نامه را در نظر بگیرید. در چنین درختی، هر گره نشان دهنده یک عضو خانواده است و ارتباطات نشان دهنده روابط خانوادگی است. اگر بخواهیم صفات خاصی را با استفاده از مدلهای مرسوم پیشبینی کنیم، ممکن است به ویژگیهایی مانند «تعداد اعضای خانواده با یک ویژگی» نیاز باشد. با این حال، با GNN ها، چنین ساخت ویژگی های دستی اضافی می شود. با تغذیه مستقیم ساختار درختی به مدل، GNN ها از مکانیزم عبور پیام استفاده می کنند که در آن هر گره با همسایگان خود ارتباط برقرار می کند. با گذشت زمان، اطلاعات در سراسر شبکه به اشتراک گذاشته می شود و انباشته می شود و مدل را قادر می سازد تا به طور طبیعی روابط پیچیده را تشخیص دهد.
با بازگشت به زمینه درختان دسترسی، این بدان معناست که GNN ها می توانند به طور موثر محتوا را با درک و استفاده از ساختار ذاتی و روابط درون درخت تقطیر کنند. این قابلیت به آنها اجازه میدهد تا بخشهای غیر ضروری را بر اساس جریان اطلاعات درون درخت شناسایی کرده و احتمالاً حذف کنند و از تقطیر محتوای دقیقتر اطمینان حاصل کنند.
معماری ما به شدت از پارادایم رمزگشایی-فرآیند-رمزگشایی با استفاده از یک شبکه عصبی پیام رسان برای طبقه بندی گره های متن پیروی می کند. طرح کلی در شکل زیر نشان داده شده است. نمایش درختی مقاله ورودی مدل است. ما ویژگی های سبک وزن را بر اساس اطلاعات جعبه محدود، اطلاعات متنی و نقش های دسترسی محاسبه می کنیم. سپس GNN نمایش نهفته هر گره را در لبه های درخت با استفاده از یک شبکه عصبی ارسال پیام منتشر می کند. این فرآیند انتشار به گرهها، کانتینرها و عناصر متنی نزدیک اجازه میدهد تا اطلاعات متنی را با یکدیگر به اشتراک بگذارند و درک مدل از ساختار و محتوای صفحه را افزایش دهند. سپس هر گره وضعیت فعلی خود را بر اساس پیام دریافتی به روز می کند و مبنای آگاهانه تری برای طبقه بندی گره ها فراهم می کند. پس از تعداد ثابتی از مراحل ارسال پیام، بازنماییهای نهفته گرهها به کلاسهای ضروری یا غیر ضروری رمزگشایی میشوند. این رویکرد مدل را قادر میسازد تا هم از روابط ذاتی در درخت و هم از ویژگیهای دستساز که هر گره را نشان میدهند، استفاده کند و در نتیجه طبقهبندی نهایی را غنیتر کند.
 |
| نمایش تصویری از الگوریتم در عمل، پردازش یک مقاله در یک دستگاه تلفن همراه. یک شبکه عصبی گراف (GNN) برای استخراج محتوای ضروری از یک مقاله استفاده می شود. 1. یک نمایش درختی از مقاله از برنامه استخراج می شود. 2. ویژگی های سبک وزن برای هر گره محاسبه می شود که به صورت بردار نمایش داده می شود. 3. یک شبکه عصبی پیام رسان اطلاعات را از طریق لبه های درخت منتشر می کند و هر نمایش گره را به روز می کند. 4. گره های برگ حاوی محتوای متنی به عنوان محتوای ضروری یا غیر ضروری طبقه بندی می شوند. 5. یک نسخه بی نظم از برنامه بر اساس خروجی GNN ساخته شده است. |
ما عمداً مجموعه ویژگیهای مورد استفاده مدل را محدود میکنیم تا تعمیم گسترده آن را در بین زبانها افزایش دهیم و تأخیر استنتاج را در دستگاههای کاربر تسریع کنیم. این یک چالش منحصر به فرد بود، زیرا ما نیاز به ایجاد یک مدل سبک وزن روی دستگاه داشتیم که بتواند حریم خصوصی را حفظ کند.
آخرین مدل اندروید سبک ما دارای پارامترهای 64k و اندازه آن 334 کیلوبایت با تأخیر متوسط 800 میلیثانیه است، در حالی که مدل کروم دارای 241 هزار پارامتر، اندازه 928 کیلوبایت و تأخیر متوسط 378 میلیثانیه است. با استفاده از چنین پردازشهایی روی دستگاه، اطمینان حاصل میکنیم که دادههای کاربر هرگز از دستگاه خارج نمیشوند و رویکرد مسئولانه و تعهد ما به حفظ حریم خصوصی کاربر را تقویت میکنیم. ویژگی های مورد استفاده در مدل را می توان به ویژگی های گره میانی، ویژگی های متن برگ-گره و ویژگی های موقعیت عنصر گروه بندی کرد. ما مهندسی ویژگی و انتخاب ویژگی را برای بهینه سازی مجموعه ویژگی ها برای عملکرد مدل و اندازه مدل انجام دادیم. مدل نهایی به قالب TensorFlow Lite تبدیل شد تا به عنوان یک مدل روی دستگاه در Android یا Chrome استقرار یابد.
نتایج
ما GNN را برای حدود 50 دوره در یک GPU آموزش دادیم. عملکرد مدل اندروید در صفحات وب و مجموعه های تست برنامه های بومی در زیر ارائه شده است:
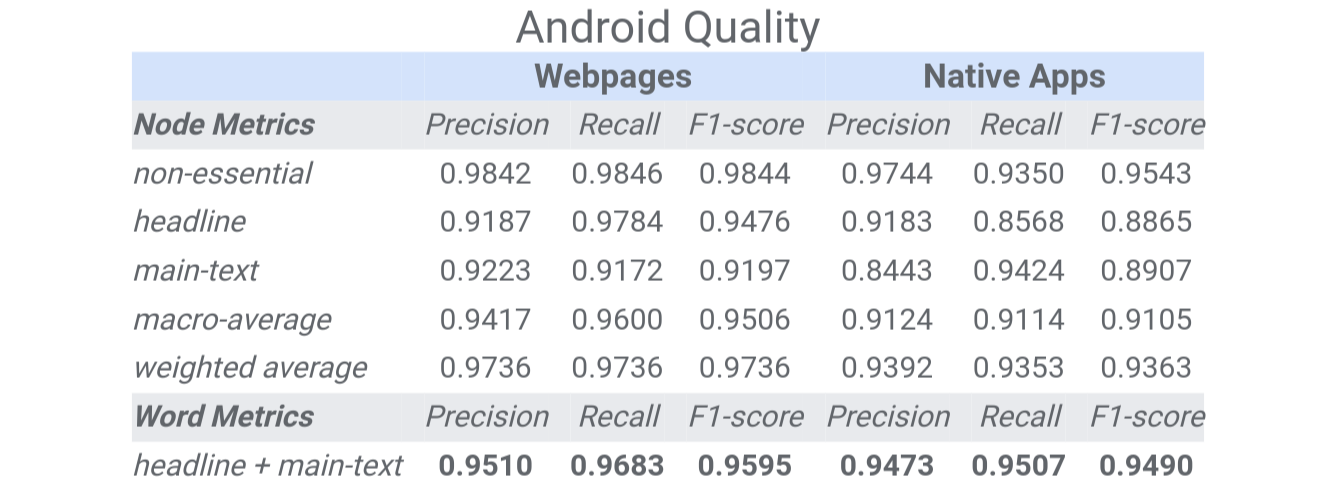 |
| جدول معیارهای تقطیر محتوا در اندروید را برای صفحات وب و برنامه های بومی ارائه می دهد. ما دقت، یادآوری و امتیاز F1 را برای سه کلاس گزارش میکنیم: محتوای غیر ضروری، عنوان، و متن اصلی، از جمله میانگین کلان و میانگین وزنی بر اساس تعداد نمونهها در هر کلاس. معیارهای گره عملکرد طبقه بندی را در دانه بندی گره درخت دسترسی، که مشابه سطح پاراگراف است، ارزیابی می کند. در مقابل، معیارهای کلمه طبقهبندی را در سطح واژهای جداگانه ارزیابی میکنند، به این معنی که هر کلمه در یک گره طبقهبندی یکسانی را دریافت میکند. |
در ارزیابی کیفیت نتایج در مقالات صفحات وب معمولاً بازدید شده، امتیاز F1 بیش از 0.9 برای متن اصلی (در اصل پاراگراف ها) مربوط به پردازش 88٪ از این مقالات بدون از دست دادن هیچ پاراگراف است. علاوه بر این، در بیش از 95٪ موارد، تقطیر برای خوانندگان ارزشمند است. به بیان ساده، اکثریت قریب به اتفاق خوانندگان محتوای مقطر را هم مناسب و هم دقیق درک میکنند و خطاها یا حذفیات یک اتفاق نادر است.
مقایسه تقطیر محتوای کروم با سایر مدلها مانند DOM Distiller یا Mozilla Readability در مجموعهای از صفحات انگلیسی زبان در جدول زیر ارائه شده است. ما از معیارهای ترجمه ماشینی برای مقایسه کیفیت این مدلها دوباره استفاده میکنیم. متن مرجع از محتوای اصلی حقیقت و متن از مدل ها به عنوان متن فرضیه است. نتایج عملکرد عالی مدل های ما را در مقایسه با سایر رویکردهای مبتنی بر DOM نشان می دهد.
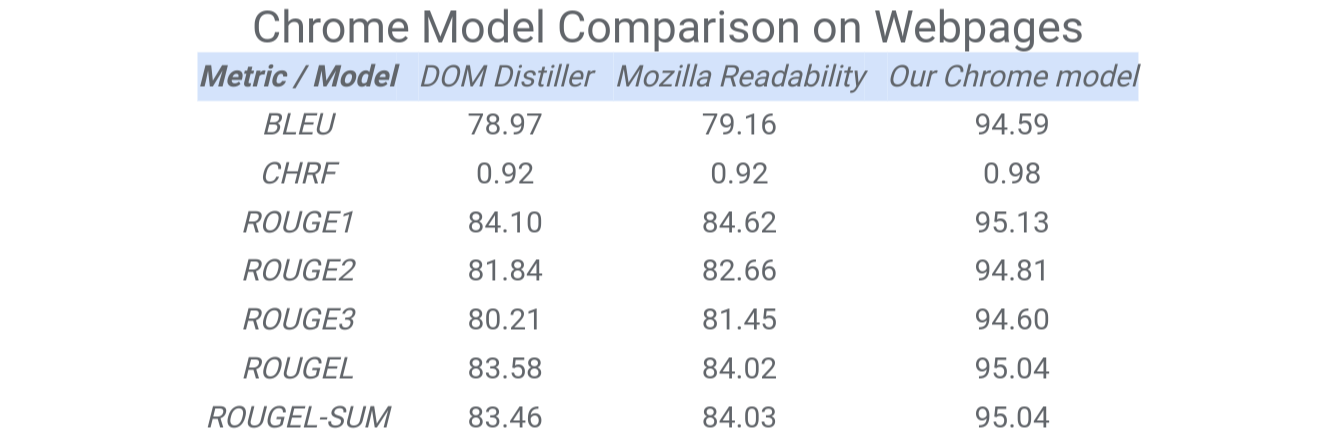 |
| جدول مقایسه بین DOM-Distiller، Mozilla Readability و مدل جدید کروم را نشان می دهد. ما معیارهای مبتنی بر متن، مانند BLUE، CHRF و ROUGE را با مقایسه متن اصلی تقطیر شده از هر مدل با یک متن واقعی که بهصورت دستی توسط ارزیابان با استفاده از خطمشی حاشیهنویسی ما برچسبگذاری شده است، گزارش میکنیم. |
امتیاز F1 مدل تقطیر محتوای Chrome برای محتوای سرفصل و متن اصلی در مجموعههای آزمایشی زبانهای رایج مختلف نشان میدهد که مدل Chrome، بهویژه، قادر به پشتیبانی از طیف وسیعی از زبانها است.
 |
| جدول به ازای هر زبان امتیازهای F1 مدل کروم را برای کلاسهای سرفصل و متن اصلی نشان میدهد. کدهای زبان با زبان های زیر مطابقت دارند: آلمانی، انگلیسی، اسپانیایی، فرانسوی، ایتالیایی، فارسی، ژاپنی، کره ای، پرتغالی، ویتنامی، چینی ساده شده و چینی سنتی. |
نتیجه
عصر دیجیتال هم ارائه محتوای ساده و هم تعهد تزلزل ناپذیر به حریم خصوصی کاربر را می طلبد. تحقیقات ما بر اثربخشی حالت خواندن در پلتفرمهایی مانند Android و Chrome تأکید میکند و رویکردی مبتکرانه و مبتنی بر داده برای تجزیه محتوا از طریق شبکههای عصبی نمودار ارائه میدهد. بسیار مهم، مدل سبک وزن ما در دستگاه تضمین میکند که تقطیر محتوا بدون به خطر انداختن دادههای کاربر، با همه فرآیندها به صورت محلی انجام میشود. این نه تنها تجربه خواندن را افزایش می دهد، بلکه تعهد ما به حریم خصوصی کاربر را نیز تقویت می کند. همانطور که ما در چشم انداز در حال تکامل مصرف محتوای دیجیتال حرکت می کنیم، یافته های ما بر اهمیت اولویت بندی کاربر در تجربه و امنیت تاکید می کند.
سپاسگزاریها
این پروژه حاصل کار مشترک مانوئل تراگوت، میهای پوپا، آبدونرینوا توکی، آبهانشو شارما، مت شریفی، دیوید پترو و بلیز آگوئرا و آرکاس است. ما صمیمانه از همکارانمان گانگ لی و یانگ لی تشکر می کنیم. ما از تام اسمال برای کمک به ما در تهیه پست بسیار سپاسگزاریم.