توانمندسازی کاربران نهایی برای آموزش تعاملی به روبات ها برای انجام وظایف جدید، یک قابلیت حیاتی برای ادغام موفقیت آمیز آنها در برنامه های کاربردی دنیای واقعی است. به عنوان مثال، یک کاربر ممکن است بخواهد به یک سگ ربات آموزش دهد تا یک ترفند جدید را انجام دهد، یا به یک ربات دستکاری آموزش دهد که چگونه یک جعبه ناهار را بر اساس ترجیحات کاربر سازماندهی کند. پیشرفتهای اخیر در مدلهای زبان بزرگ (LLM) که از قبل بر روی دادههای گسترده اینترنتی آموزش داده شدهاند، مسیر امیدوارکنندهای را برای دستیابی به این هدف نشان دادهاند. در واقع، محققان راههای مختلفی را برای استفاده از LLM برای روباتیک، از برنامهریزی گام به گام و گفتگوی هدفمحور گرفته تا عوامل کدنویسی ربات، مورد بررسی قرار دادهاند.
در حالی که این روشها حالتهای جدیدی از تعمیم ترکیبی را ارائه میدهند، آنها بر روی استفاده از زبان برای پیوند دادن رفتارهای جدید از یک کتابخانه موجود کنترل اولیه تمرکز میکنند که یا به صورت دستی مهندسی شده یا آموخته شدهاند. اولین. علیرغم داشتن دانش داخلی در مورد حرکات ربات، LLMها به دلیل در دسترس بودن محدود داده های آموزشی مربوطه، در تلاش برای خروج مستقیم دستورات ربات سطح پایین هستند. در نتیجه، بیان این روشها به دلیل وسعت روشهای اولیه موجود، که طراحی آنها اغلب به دانش تخصصی گسترده یا جمعآوری دادههای عظیم نیاز دارد، با تنگنا مواجه میشود.
در “زبان به پاداش برای ترکیب مهارت های رباتیک”، ما رویکردی را پیشنهاد می کنیم تا کاربران را قادر می سازد تا اقدامات جدید را از طریق ورودی زبان طبیعی به روبات ها آموزش دهند. برای انجام این کار، از عملکردهای پاداش به عنوان رابطی استفاده می کنیم که شکاف بین زبان و اقدامات ربات سطح پایین را پر می کند. ما فرض می کنیم که توابع پاداش با توجه به غنای معنایی، مدولار بودن و تفسیرپذیری، یک رابط ایده آل برای چنین وظایفی ارائه می دهند. آنها همچنین از طریق بهینه سازی جعبه سیاه یا یادگیری تقویتی (RL) با خط مشی های سطح پایین ارتباط مستقیم برقرار می کنند. ما یک سیستم زبان به پاداش ایجاد کردیم که از LLM ها برای ترجمه دستورالعمل های کاربر زبان طبیعی به کدهای تعیین کننده پاداش استفاده می کند و سپس MuJoCo MPC را برای یافتن اقدامات بهینه ربات سطح پایین که عملکرد پاداش تولید شده را به حداکثر می رساند، اعمال می کند. ما سیستم زبان به پاداش خود را در انواع وظایف کنترل رباتیک در شبیه سازی با استفاده از یک ربات چهارپا و یک ربات دستکاری ماهر نشان می دهیم. ما روش خود را در یک دستکاری کننده ربات فیزیکی بیشتر تأیید می کنیم.
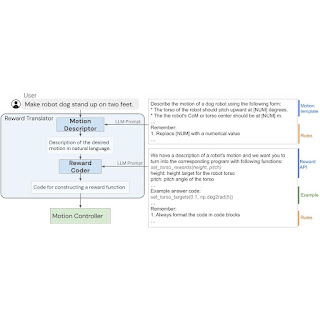
سیستم زبان به پاداش از دو جزء اصلی تشکیل شده است: (1) یک مترجم پاداش و (2) یک کنترل کننده حرکت.. را Reward Translator دستورالعملهای زبان طبیعی را از کاربران به توابع پاداش که بهعنوان کد پایتون نشان داده میشوند، ترسیم میکند. Motion Controller تابع پاداش داده شده را با استفاده از بهینه سازی افق عقب نشینی بهینه می کند تا اقدامات بهینه ربات در سطح پایین را پیدا کند، مانند مقدار گشتاوری که باید به هر موتور ربات اعمال شود.
 |
| LLM ها به دلیل کمبود داده در مجموعه داده های قبل از آموزش نمی توانند مستقیماً اقدامات رباتیک سطح پایین ایجاد کنند. ما پیشنهاد می کنیم از توابع پاداش برای پر کردن شکاف بین زبان و اقدامات ربات سطح پایین استفاده کنیم و حرکات پیچیده ربات جدید را از دستورالعمل های زبان طبیعی فعال کنیم. |
Reward Translator: ترجمه دستورالعمل های کاربر به توابع پاداش
ماژول Reward Translator با هدف نگاشت دستورالعمل های کاربر زبان طبیعی برای توابع پاداش ساخته شده است. تنظیم پاداش بسیار خاص دامنه است و به دانش تخصصی نیاز دارد، بنابراین برای ما تعجب آور نبود وقتی متوجه شدیم که LLM های آموزش دیده بر روی مجموعه داده های زبان عمومی قادر به تولید مستقیم تابع پاداش برای یک سخت افزار خاص نیستند. برای پرداختن به این موضوع، از توانایی یادگیری درون زمینه ای LLM استفاده می کنیم. علاوه بر این، مترجم پاداش را به دو ماژول فرعی تقسیم کردیم: توصیفگر حرکت و کدگذار پاداش.
توصیفگر حرکت
ابتدا، ما یک توصیفگر حرکت طراحی میکنیم که ورودی کاربر را تفسیر میکند و آن را به شرح زبان طبیعی حرکت ربات مورد نظر به دنبال یک الگوی از پیش تعریفشده گسترش میدهد. این Motion Descriptor دستورالعملهای کاربر مبهم یا مبهم را به حرکات ربات خاصتر و توصیفیتر تبدیل میکند و کار کدگذاری پاداش را پایدارتر میکند. علاوه بر این، کاربران از طریق فیلد توضیحات حرکت با سیستم تعامل دارند، بنابراین در مقایسه با نمایش مستقیم تابع پاداش، رابط قابل تفسیرتری برای کاربران فراهم میکند.
برای ایجاد توصیفگر حرکت، از یک LLM برای ترجمه ورودی کاربر به شرح مفصل حرکت ربات مورد نظر استفاده می کنیم. ما اعلانهایی طراحی میکنیم که LLMها را راهنمایی میکند تا توضیحات حرکت را با جزئیات و فرمت مناسب خروجی بگیرند. با ترجمه یک دستورالعمل کاربر مبهم به توضیحات دقیق تر، می توانیم عملکرد پاداش را با اطمینان بیشتری با سیستم خود تولید کنیم. این ایده همچنین میتواند به طور بالقوه فراتر از وظایف رباتیک به کار گرفته شود و به مونولوگ درونی و تحریک زنجیرهای از فکر مرتبط است.
کدگذار پاداش
در مرحله دوم، ما از همان LLM از Motion Descriptor برای Reward Coder استفاده می کنیم که توضیحات حرکت تولید شده را به تابع پاداش ترجمه می کند. توابع پاداش با استفاده از کد پایتون برای بهره مندی از دانش LLM ها در مورد پاداش، کدگذاری و ساختار کد نمایش داده می شوند.
در حالت ایدهآل، ما میخواهیم از یک LLM برای تولید مستقیم تابع پاداش استفاده کنیم آر (س، تی) که وضعیت ربات را ترسیم می کند س و زمان تی به یک ارزش پاداش اسکالر. با این حال، ایجاد تابع پاداش صحیح از ابتدا هنوز یک مشکل چالش برانگیز برای LLM ها است و اصلاح خطاها نیازمند درک کد تولید شده توسط کاربر برای ارائه بازخورد مناسب است. به این ترتیب، مجموعهای از اصطلاحات پاداش را از پیش تعریف میکنیم که معمولاً برای ربات مورد علاقه استفاده میشوند و به LLMها اجازه میدهیم تا اصطلاحات پاداش متفاوتی را برای فرمولبندی تابع پاداش نهایی ترکیب کنند. برای رسیدن به این هدف، ما یک اعلان طراحی میکنیم که شرایط پاداش را مشخص میکند و LLM را راهنمایی میکند تا تابع پاداش صحیح را برای کار ایجاد کند.
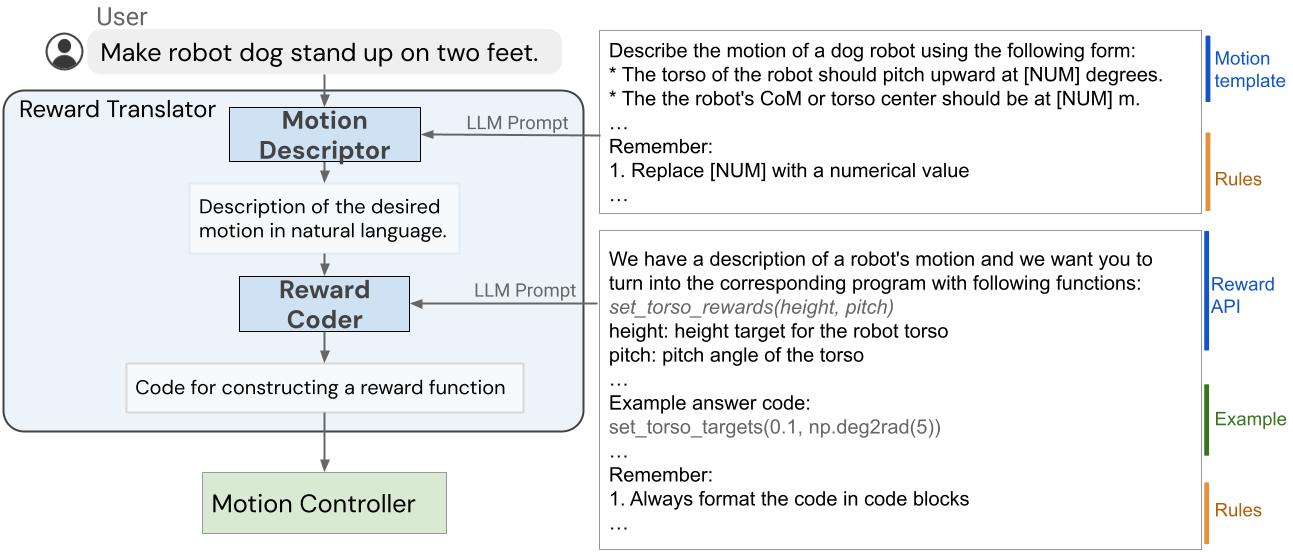 |
| ساختار داخلی Reward Translator که وظیفه دارد ورودی های کاربر را برای توابع پاداش ترسیم کند. |
کنترل کننده حرکت: توابع پاداش را به اقدامات ربات ترجمه می کند
Motion Controller تابع پاداش تولید شده توسط Reward Translator را می گیرد و کنترل کننده ای را ترکیب می کند که مشاهدات ربات را به اقدامات ربات در سطح پایین ترسیم می کند. برای انجام این کار، ما مسئله سنتز کنترلر را به عنوان یک فرآیند تصمیم گیری مارکوف (MDP) فرموله می کنیم، که می تواند با استفاده از استراتژی های مختلف، از جمله RL، بهینه سازی مسیر آفلاین، یا کنترل پیش بینی مدل (MPC) حل شود. به طور خاص، ما از یک پیاده سازی منبع باز مبتنی بر MuJoCo MPC (MJPC) استفاده می کنیم.
MJPC ایجاد تعاملی رفتارهای متنوعی مانند حرکت با پا، گرفتن و راه رفتن با انگشت را نشان داده است، در حالی که از الگوریتمهای برنامهریزی متعدد، مانند نمونهگیری خطی-مربع-گاوسی تکراری (iLQG) و پیشبینی پشتیبانی میکند. مهمتر از آن، برنامهریزی مجدد مکرر در MJPC، استحکام آن را در برابر عدم قطعیتهای سیستم تقویت میکند و یک سیستم سنتز و تصحیح حرکت تعاملی را هنگامی که با LLM ترکیب میشود، ممکن میسازد.
مثال ها
سگ ربات
در مثال اول، سیستم زبان به پاداش را بر روی یک ربات چهارپا شبیه سازی شده اعمال می کنیم و انجام مهارت های مختلف را به آن آموزش می دهیم. برای هر مهارت، کاربر یک دستورالعمل مختصر به سیستم ارائه می دهد که سپس با استفاده از توابع پاداش به عنوان یک رابط میانی، حرکت ربات را ترکیب می کند.
دستکاری ماهر
سپس سیستم زبان به پاداش را برای یک ربات دستکاری ماهر اعمال می کنیم تا انواع مختلفی از وظایف دستکاری را انجام دهد. دستکاری ماهر دارای 27 درجه آزادی است که کنترل آن بسیار چالش برانگیز است. بسیاری از این وظایف به مهارت های دستکاری فراتر از درک نیاز دارند، که کار را برای کارهای اولیه از پیش طراحی شده دشوار می کند. ما همچنین مثالی را اضافه می کنیم که در آن کاربر می تواند به طور تعاملی به ربات دستور دهد تا یک سیب را در داخل کشو قرار دهد.
اعتبار سنجی روی ربات های واقعی
ما همچنین روش زبان به پاداش را با استفاده از یک ربات دستکاری در دنیای واقعی برای انجام کارهایی مانند برداشتن اشیاء و باز کردن کشو تأیید میکنیم. برای انجام بهینهسازی در Motion Controller، ما از AprilTag، یک سیستم نشانگر واقعی، و F-VLM، یک ابزار تشخیص اشیا با واژگان باز، برای شناسایی موقعیت جدول و اشیاء دستکاری شده استفاده میکنیم.
نتیجه
در این کار، ما یک پارادایم جدید برای ارتباط یک LLM با یک ربات از طریق توابع پاداش، که توسط یک ابزار کنترل پیشبینی مدل سطح پایین، MuJoCo MPC ارائه میشود، توصیف میکنیم. استفاده از توابع پاداش به عنوان رابط، LLM ها را قادر می سازد در فضایی غنی از معنایی کار کنند که با نقاط قوت LLM ها مطابقت دارد، در حالی که بیانگر بودن کنترل کننده حاصل را تضمین می کند. برای بهبود بیشتر عملکرد سیستم، پیشنهاد می کنیم از یک الگوی توصیف حرکت ساختاریافته برای استخراج بهتر دانش داخلی در مورد حرکات ربات از LLMها استفاده کنیم. ما سیستم پیشنهادی خود را بر روی دو سکوی ربات شبیه سازی شده و یک ربات واقعی برای هر دو کار حرکت و دستکاری نشان می دهیم.
سپاسگزاریها
مایلیم از نویسندگان همکارمان نمرود گیلیادی، چویان فو، شان کرمانی، کوانگ-هوی لی، مونتسه گونزالس آرناس، هائو تین لوئیس چیانگ، تام ارز، لئونارد هاسنکلور، برایان ایچتر، تد شیائو، پنگ زو، اندی زنگ تشکر کنیم. ، Tingnan Zhang، Nicolas Heess، Dorsa Sadigh، Jie Tan و Yuval Tassa برای کمک و حمایت آنها در جنبه های مختلف پروژه. ما همچنین میخواهیم از Ken Caluwaerts، Kristian Hartikainen، Steven Bohez، Carolina Parada، Marc Toussaint و تیمهای Google DeepMind برای بازخورد و مشارکتشان قدردانی کنیم.