پیشرفت زیادی در جهت تطبیق مدلهای زبان بزرگ (LLMs) برای تطبیق ورودیهای چندوجهی برای کارهایی از جمله شرح تصاویر، پاسخگویی به سؤالات بصری (VQA) و تشخیص واژگان باز صورت گرفته است. با وجود چنین دستاوردهایی، مدلهای زبان بصری پیشرفته (VLM) در مجموعه دادههای جستجوی اطلاعات بصری، مانند Infoseek و OK-VQA، که در آن دانش خارجی برای پاسخ به سؤالات مورد نیاز است، عملکرد ناکافی دارند.
 |
| نمونه هایی از پرس و جوهای جستجوی اطلاعات بصری که در آن دانش خارجی برای پاسخ به سؤال مورد نیاز است. تصاویر از مجموعه داده OK-VQA گرفته شده است. |
در «AVIS: جستجوی مستقل اطلاعات بصری با مدلهای زبان بزرگ»، روش جدیدی را معرفی میکنیم که به نتایج پیشرفتهای در کارهای جستجوی اطلاعات بصری دست مییابد. روش ما LLM ها را با سه نوع ابزار ادغام می کند: (1) ابزارهای بینایی رایانه ای برای استخراج اطلاعات بصری از تصاویر، (2) یک ابزار جستجوی وب برای بازیابی دانش و حقایق جهان باز، و (iii) یک ابزار جستجوی تصویر برای جمع آوری اطلاعات مرتبط. از ابرداده مرتبط با تصاویر بصری مشابه. AVIS از یک برنامه ریز مبتنی بر LLM برای انتخاب ابزارها و پرس و جوها در هر مرحله استفاده می کند. همچنین برای تجزیه و تحلیل خروجیهای ابزار و استخراج اطلاعات کلیدی از یک استدلالگر مبتنی بر LLM استفاده میکند. یک جزء حافظه کاری اطلاعات را در طول فرآیند حفظ می کند.
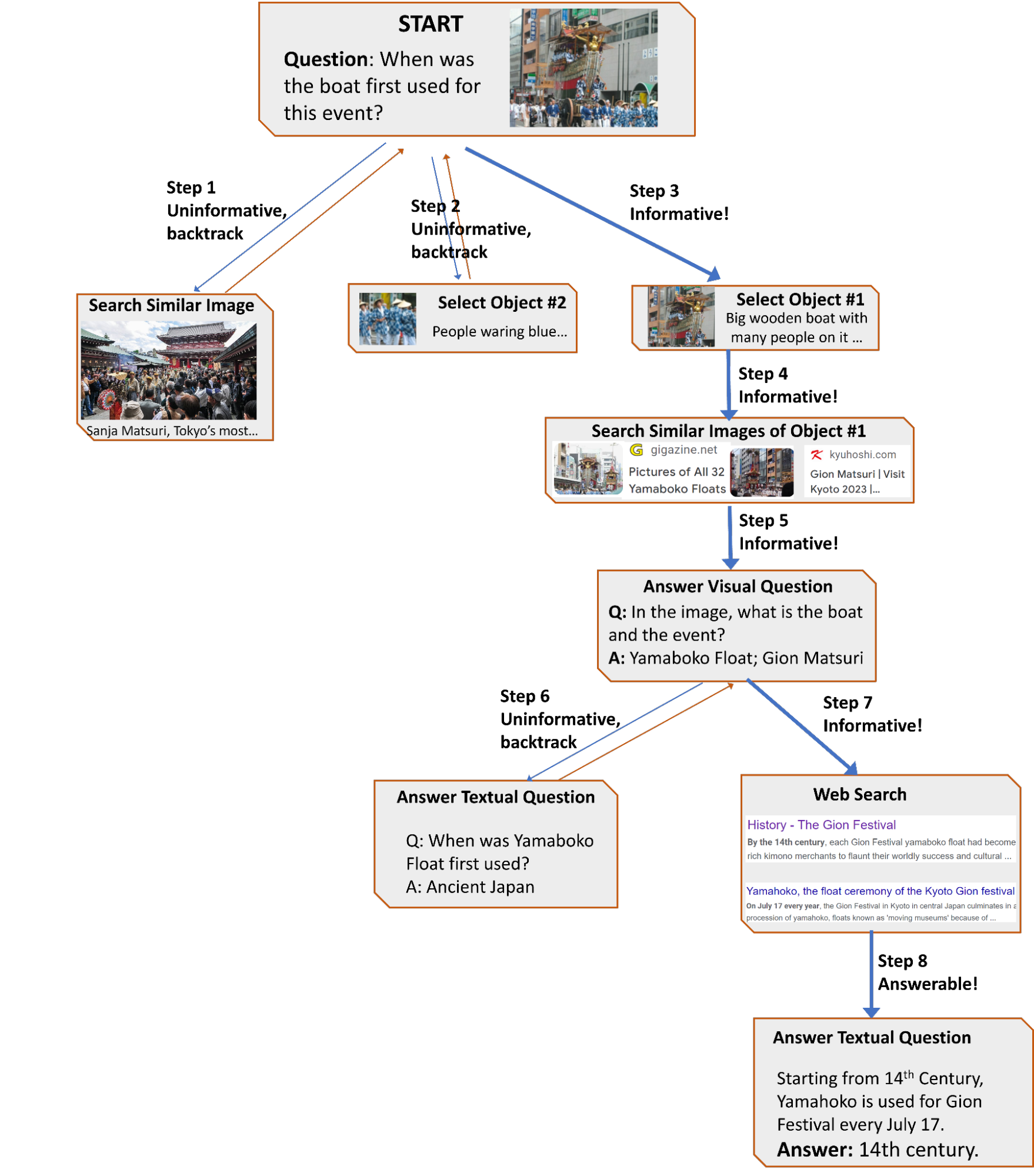 |
| نمونه ای از گردش کار تولید شده AVIS برای پاسخ به یک سوال چالش برانگیز جستجوی اطلاعات بصری. تصویر ورودی از مجموعه داده Infoseek گرفته شده است. |
مقایسه با کارهای قبلی
مطالعات اخیر (به عنوان مثال، آفتاب پرست، ViperGPT و MM-ReAct) افزودن ابزارهایی به LLM ها برای ورودی های چندوجهی را بررسی کردند. این سیستم ها یک فرآیند دو مرحله ای را دنبال می کنند: برنامه ریزی (تجزیه سوالات به برنامه ها یا دستورالعمل های ساختاریافته) و اجرا (استفاده از ابزار برای جمع آوری اطلاعات). علیرغم موفقیت در کارهای اساسی، این رویکرد اغلب در سناریوهای پیچیده دنیای واقعی شکست میخورد.
همچنین علاقه زیادی به استفاده از LLMها به عنوان عوامل مستقل (مانند WebGPT و ReAct) وجود دارد. این عوامل با محیط خود تعامل دارند، بر اساس بازخوردهای لحظه ای سازگار می شوند و به اهداف می رسند. با این حال، این روشها ابزارهایی را که میتوان در هر مرحله از آنها فراخوانی کرد، محدود نمیکند و به فضای جستجوی عظیمی منجر میشود. در نتیجه، حتی پیشرفتهترین LLMهای امروزی میتوانند در حلقههای بینهایت قرار بگیرند یا خطاها را منتشر کنند. AVIS با استفاده از LLM هدایتشده، تحت تأثیر تصمیمهای انسانی از مطالعه کاربر، با این مشکل مقابله میکند.
اطلاع رسانی تصمیم گیری LLM با مطالعه کاربر
بسیاری از سوالات بصری در مجموعه دادهها مانند Infoseek و OK-VQA حتی برای انسانها نیز چالشهایی را ایجاد میکنند که اغلب به کمک ابزارها و APIهای مختلف نیاز دارند. یک نمونه سوال از مجموعه داده OK-VQA در زیر نشان داده شده است. ما یک مطالعه کاربری برای درک تصمیم گیری انسانی در هنگام استفاده از ابزارهای خارجی انجام دادیم.
 |
| ما یک مطالعه کاربری برای درک تصمیم گیری انسانی در هنگام استفاده از ابزارهای خارجی انجام دادیم. تصویر از مجموعه داده OK-VQA گرفته شده است. |
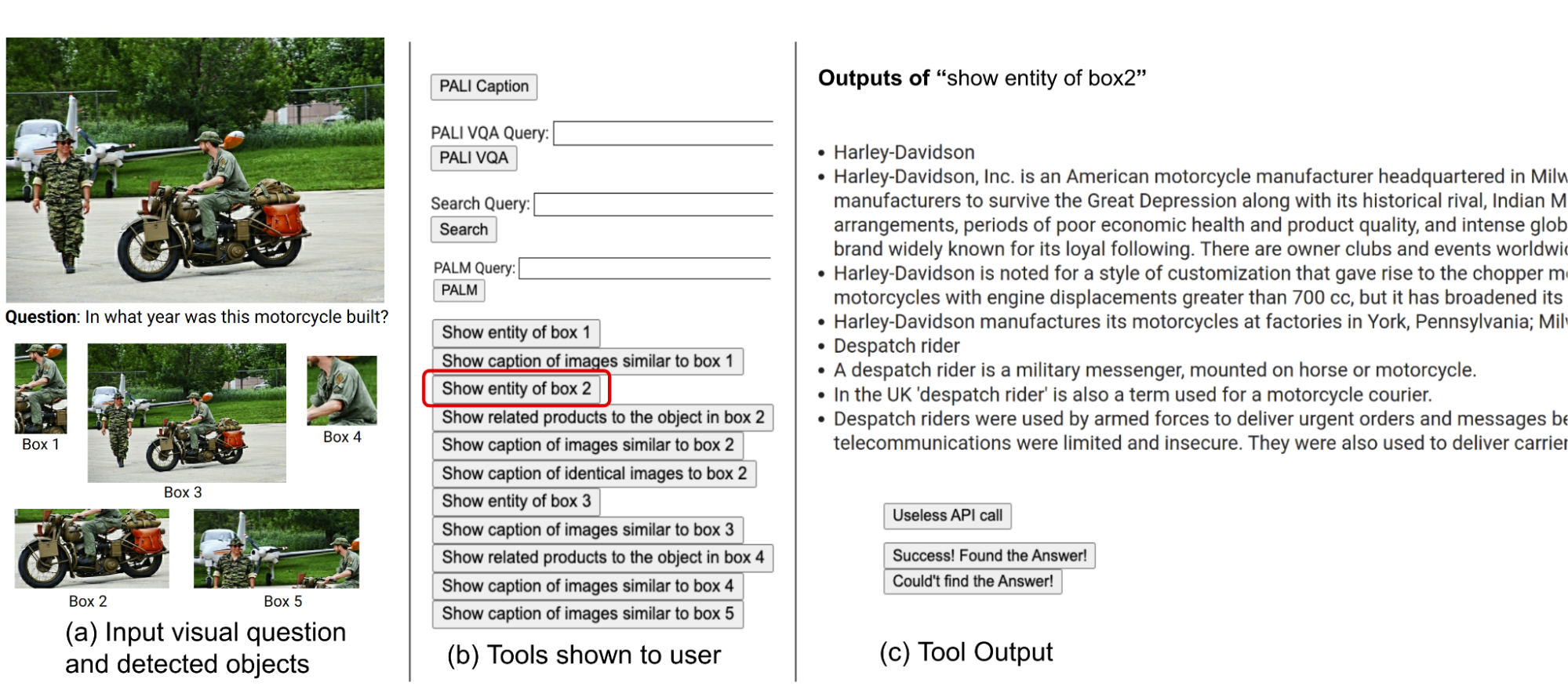
کاربران به مجموعهای از ابزارهای مشابه روش ما مجهز بودند، از جمله PALI، PALM، و جستجوی وب. آنها تصاویر ورودی، سوالات، برش اشیاء شناسایی شده و دکمه های مرتبط با نتایج جستجوی تصویر را دریافت کردند. این دکمهها اطلاعات متنوعی در مورد برشهای اشیاء شناساییشده، مانند موجودیتهای نمودار دانش، شرح تصاویر مشابه، عناوین محصولات مرتبط، و شرح تصاویر یکسان ارائه میدهند.
ما اقدامات و خروجی های کاربر را ضبط می کنیم و از آن به عنوان راهنمای سیستم خود به دو روش کلیدی استفاده می کنیم. ابتدا، با تجزیه و تحلیل توالی تصمیمات اتخاذ شده توسط کاربران، یک نمودار انتقال ایجاد می کنیم (در زیر نشان داده شده است). این نمودار حالت های متمایز را تعریف می کند و مجموعه اقدامات موجود در هر حالت را محدود می کند. به عنوان مثال، در حالت شروع، سیستم می تواند تنها یکی از این سه عمل را انجام دهد: PALI caption، PALI VQA یا تشخیص شی. دوم، ما از نمونههای تصمیمگیری انسانی برای راهنمایی برنامهریز و استدلالکننده خود با موارد متنی مرتبط برای افزایش عملکرد و اثربخشی سیستم خود استفاده میکنیم.
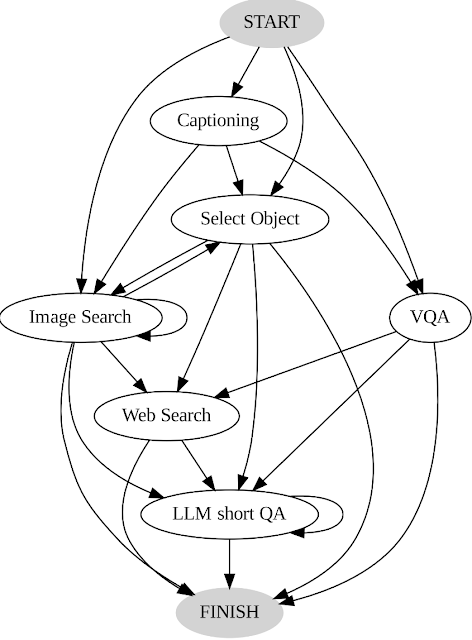 |
| نمودار انتقال AVIS. |
چارچوب کلی
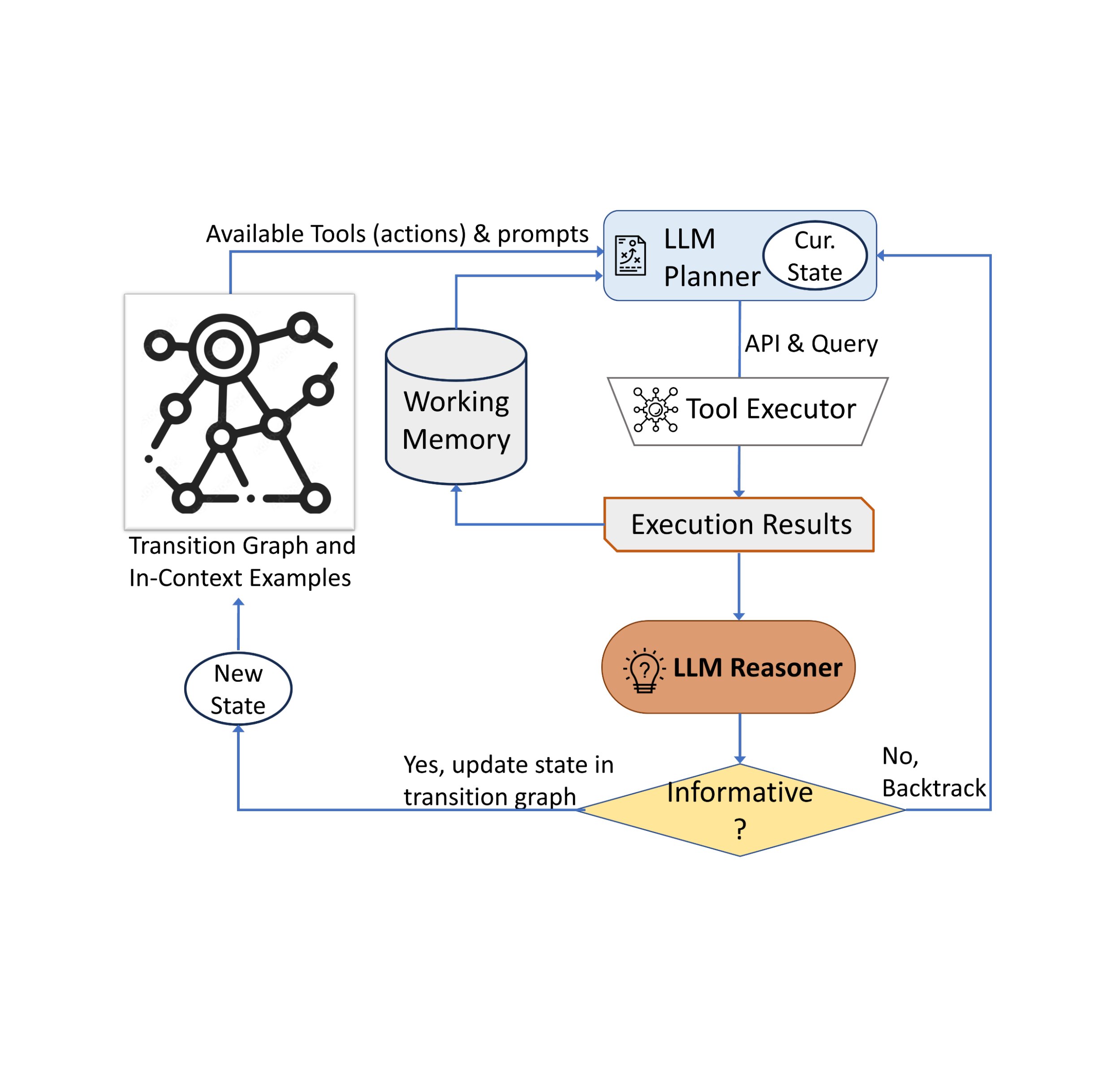
رویکرد ما از یک استراتژی تصمیم گیری پویا استفاده می کند که برای پاسخ به پرسش های جستجوی اطلاعات بصری طراحی شده است. سیستم ما دارای سه جزء اصلی است. اول، ما یک برنامه ریز برای تعیین اقدام بعدی، از جمله فراخوانی مناسب API و پرس و جوی مورد نیاز برای پردازش. دوم، ما یک حافظه کاری که اطلاعات مربوط به نتایج به دست آمده از اجرای API را حفظ می کند. آخرین، ما یک استدلال کننده، که نقش آن پردازش خروجی های فراخوانی API است. تعیین می کند که آیا اطلاعات به دست آمده برای ایجاد پاسخ نهایی کافی است یا نیاز به بازیابی اطلاعات اضافی است.
برنامه ریز هر بار که تصمیم می گیرد در مورد اینکه کدام ابزار را بکار گیرد و چه درخواستی را برای آن ارسال کند، یک سری مراحل را انجام می دهد. بر اساس وضعیت فعلی، برنامه ریز مجموعه ای از اقدامات بالقوه بعدی را ارائه می دهد. فضای عمل بالقوه ممکن است آنقدر بزرگ باشد که فضای جستجو را غیرقابل تحمل کند. برای پرداختن به این موضوع، برنامه ریز برای حذف اقدامات نامربوط به نمودار انتقال اشاره می کند. برنامه ریز همچنین اقداماتی را که قبلاً انجام شده و در حافظه کاری ذخیره شده اند را حذف می کند.
سپس، برنامهریز مجموعهای از مثالهای مرتبط را جمعآوری میکند که از تصمیمهایی که قبلاً توسط انسانها در طول مطالعه کاربر گرفته شده است جمعآوری شدهاند. با این مثالها و حافظه کاری که دادههای جمعآوریشده از فعل و انفعالات ابزار گذشته را نگه میدارد، برنامهریز یک درخواست را فرموله میکند. سپس درخواست به LLM ارسال میشود، که یک پاسخ ساختاریافته را برمیگرداند و ابزار بعدی را که باید فعال شود و درخواستی که باید به آن ارسال شود، تعیین میکند. این طراحی به برنامه ریز اجازه می دهد تا چندین بار در طول فرآیند فراخوانی شود، در نتیجه تصمیم گیری پویا را تسهیل می کند که به تدریج منجر به پاسخ به پرس و جو ورودی می شود.
ما از یک استدلال برای تجزیه و تحلیل خروجی اجرای ابزار استفاده می کنیم، اطلاعات مفید را استخراج می کنیم و تصمیم می گیریم که خروجی ابزار در کدام دسته قرار می گیرد: آموزنده، غیر اطلاعاتی، یا پاسخ نهایی. روش ما از LLM با مثالهای مناسب و درون متنی برای اجرای استدلال استفاده میکند. اگر استدلال کننده به این نتیجه برسد که آماده ارائه پاسخ است، پاسخ نهایی را خروجی می دهد و در نتیجه کار را به پایان می رساند. اگر تشخیص دهد که خروجی ابزار غیر اطلاعاتی است، به برنامه ریز برمی گردد تا عمل دیگری را بر اساس وضعیت فعلی انتخاب کند. اگر خروجی ابزار را مفید بداند، وضعیت را تغییر میدهد و کنترل را به برنامهریز برمیگرداند تا در وضعیت جدید تصمیم جدیدی بگیرد.
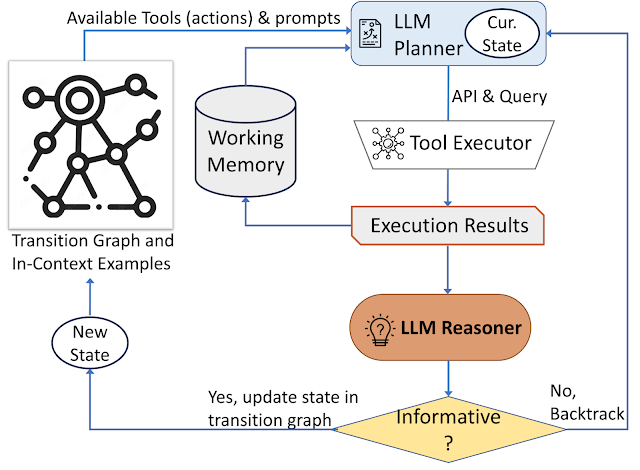 |
| AVIS از یک استراتژی تصمیم گیری پویا برای پاسخ به پرسش های جستجوی اطلاعات بصری استفاده می کند. |
نتایج
ما AVIS را روی مجموعه داده های Infoseek و OK-VQA ارزیابی می کنیم. همانطور که در زیر نشان داده شده است، حتی مدلهای قوی با زبان بصری، مانند OFA و PaLI، هنگام تنظیم دقیق در Infoseek، دقت بالایی ندارند. رویکرد ما (AVIS)، بدون تنظیم دقیق، به دقت 50.7 درصد در تقسیم موجودیت نامرئی این مجموعه داده میرسد.
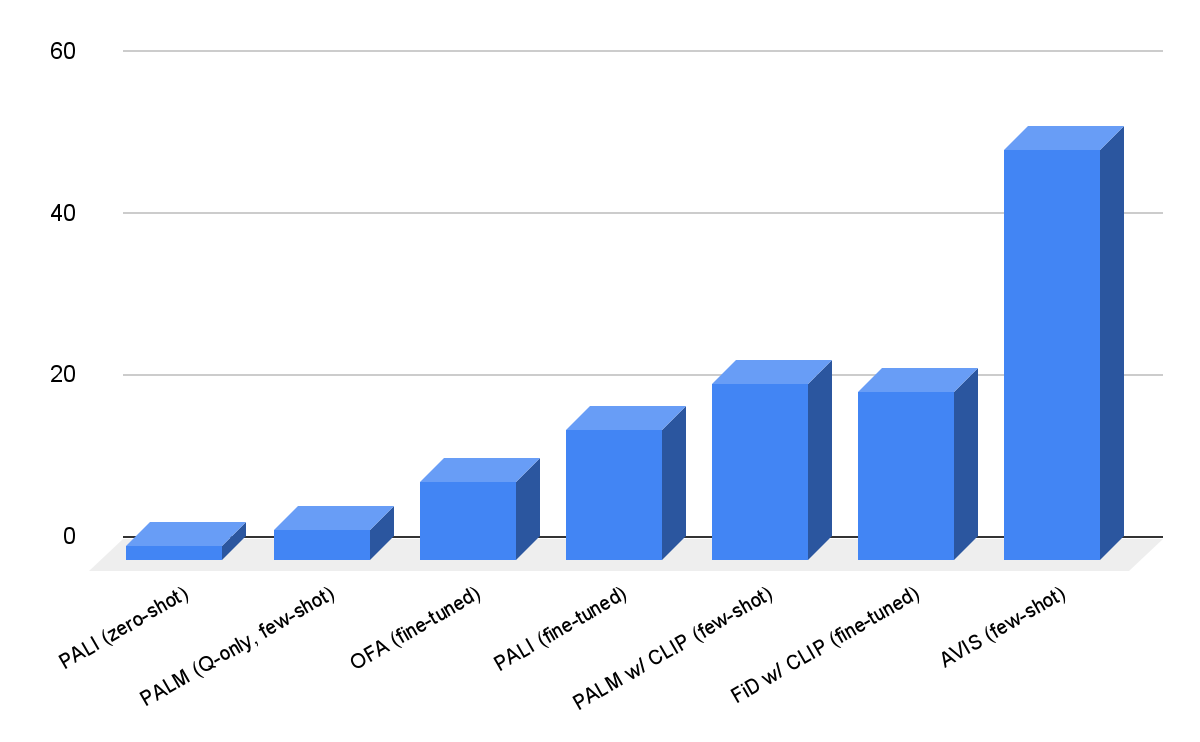 |
| نتایج پاسخگویی به پرسش بصری AVIS در مجموعه داده Infoseek. AVIS در مقایسه با خطوط پایه قبلی بر اساس PaLI، PalM و OFA به دقت بالاتری دست می یابد. |
نتایج ما در مجموعه داده OK-VQA در زیر نشان داده شده است. AVIS با نمونههای چند عکس درون متنی به دقت 60.2 درصد میرسد، بالاتر از بسیاری از کارهای قبلی. AVIS در مقایسه با مدل PALI که روی OK-VQA تنظیم شده است، دقت کمتر اما قابل مقایسه ای به دست می آورد. این تفاوت، در مقایسه با Infoseek که در آن AVIS بهتر از PALI تنظیم شده بهتر عمل می کند، به این دلیل است که بیشتر نمونه های پرسش-پاسخ در OK-VQA به جای دانش دقیق، بر دانش عقل سلیم تکیه دارند. بنابراین، PaLI قادر است چنین دانش عمومی را در پارامترهای مدل رمزگذاری کند و نیازی به دانش خارجی ندارد.
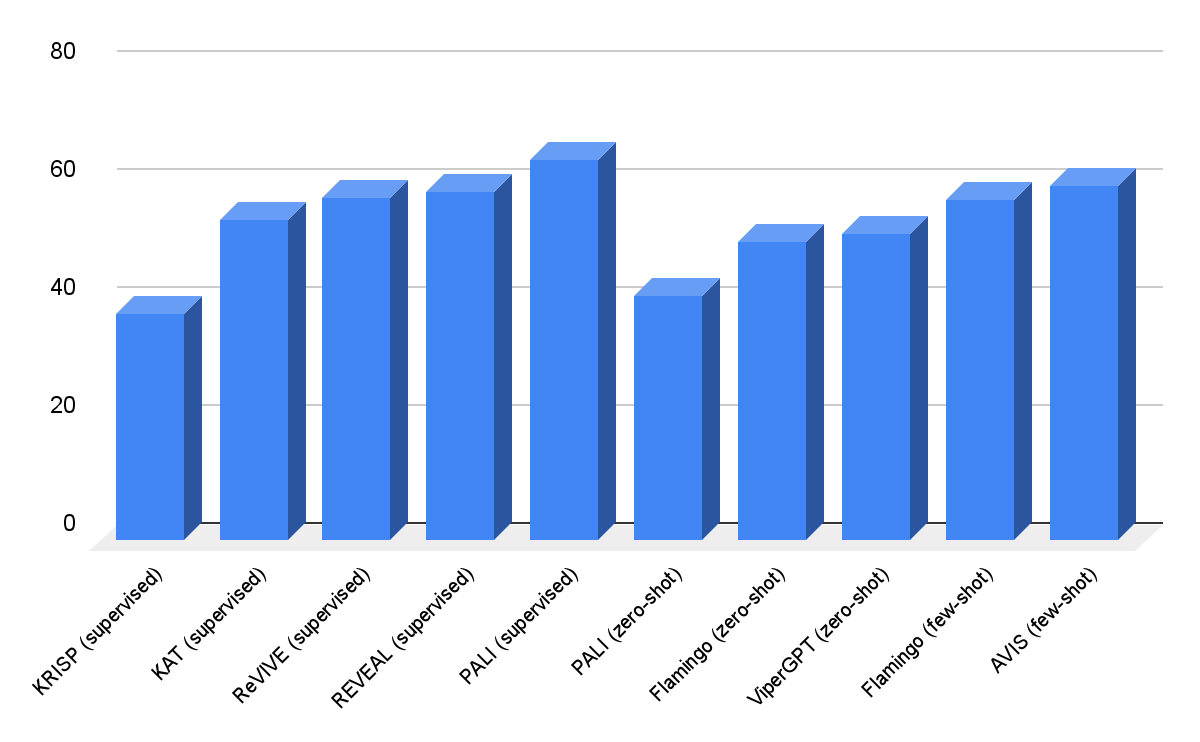 |
| نتایج پاسخگویی به سوال تصویری در A-OKVQA. AVIS در مقایسه با کارهای قبلی که از یادگیری چند شات یا صفر شات استفاده میکنند، از جمله Flamingo، PaLI و ViperGPT، به دقت بالاتری دست مییابد. AVIS همچنین نسبت به بسیاری از کارهای قبلی که بر روی مجموعه داده های OK-VQA تنظیم شده اند، از جمله REVEAL، ReVIVE، KAT و KRISP، به دقت بالاتری دست می یابد و به نتایج نزدیک به مدل PaLI تنظیم شده نزدیک می شود. |
نتیجه
ما یک رویکرد جدید ارائه می کنیم که LLM ها را با توانایی استفاده از ابزارهای مختلف برای پاسخ دادن به سوالات بصری دانش فشرده مجهز می کند. روششناسی ما، که بر دادههای تصمیمگیری انسانی جمعآوریشده از یک مطالعه کاربر تثبیت شده است، از یک چارچوب ساختاریافته استفاده میکند که از یک برنامهریز مبتنی بر LLM برای تصمیمگیری پویا در مورد انتخاب ابزار و تشکیل پرس و جو استفاده میکند. یک استدلالگر مبتنی بر LLM وظیفه پردازش و استخراج اطلاعات کلیدی را از خروجی ابزار انتخابی دارد. روش ما به طور مکرر از برنامه ریز و استدلال کننده برای استفاده از ابزارهای مختلف استفاده می کند تا زمانی که تمام اطلاعات لازم برای پاسخ به سؤال بصری جمع آوری شود.
سپاسگزاریها
این تحقیق توسط Ziniu Hu، Ahmet Iscen، Chen Sun، Kai-Wei Chang، Yizhou Sun، David A. Ross، Cordelia Schmid و علیرضا فتحی انجام شده است.