
اگر قرار است جنگ باشد ، اگر یک بازار رقابتی در پردازنده های سطح بالا و کلاس سرور وجود داشته باشد ، مانند سال 1999 ، این بار میدان جنگ “پسوندهای برداری” خواهد بود. این توسعه هایی است که طراحان باهوش می توانند در مجموعه دستورالعمل های اصلی پردازنده انجام دهند و به آنها امکان می دهد تا عملکردهای منفرد ، اغلب سفارشی (یا قابل تنظیم) را روی آرایه های گسترده داده به جای ثبت های منفرد انجام دهند.
در اعلام جدیدترین تراشه های سرور Neoverse اخیراً ، Arm این موضوع را کاملاً واضح اعلام کرد: افزودن پسوندهای برداری مقیاس پذیر (SVE) به Arm Neoverse V1 جدید و Arm Neoverse N2 بیشتر ، البته نه به طور کامل ، در مورد ارائه شرکای آن است – شرکت هایی که تراشه های فیزیکی را بر اساس IP Arm طراحی ، تولید و می فروشند – اهرم فشار مورد نیاز برای افزایش در برابر نسل سوم Xeon اینتل.
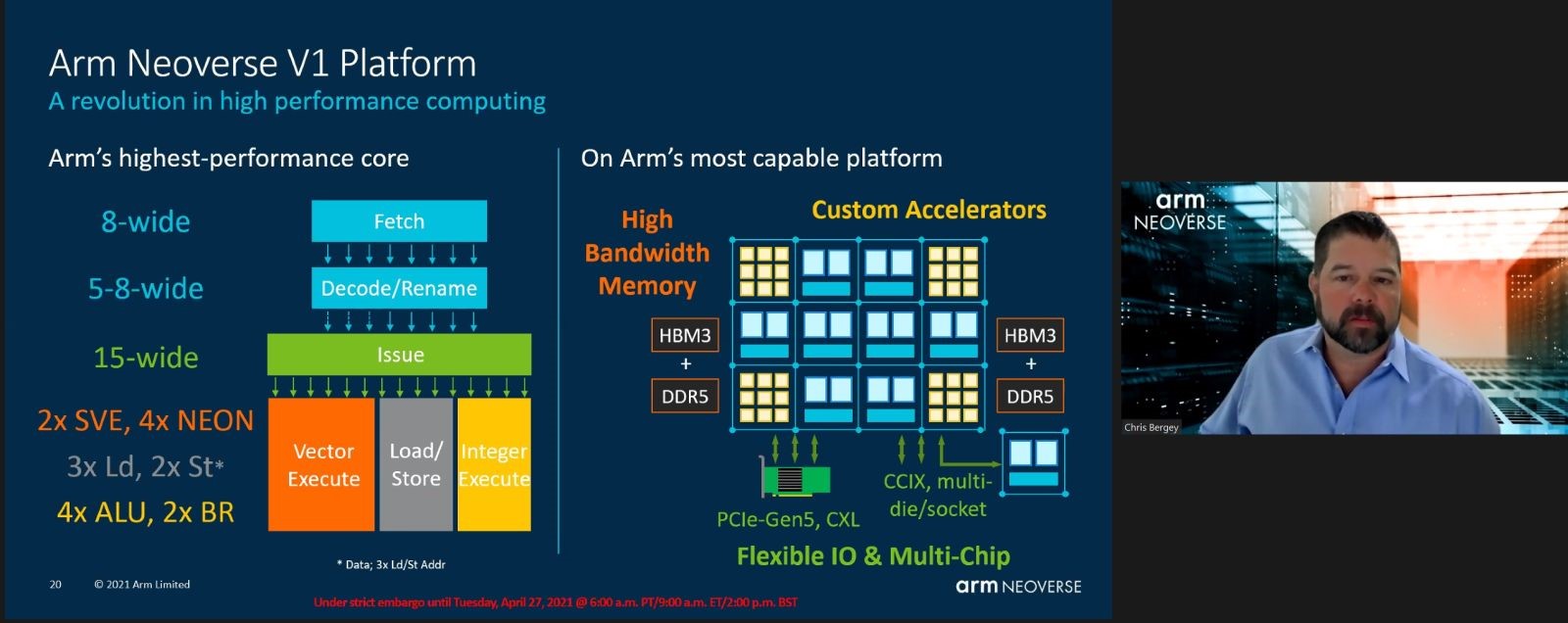
کریس برگی ، معاون ارشد ارشد Arm و مدیر کل زیرساخت ها ، در جلسه توجیهی با خبرنگاران گفت: “پلتفرم Neoverse V1 از قابلیت های IP لازم برای هدف قرار دادن بازارهایی مانند محاسبات با کارایی بالا و مقیاس بزرگ پشتیبانی می کند.” “ما به شرکای خود این انعطاف را می دهیم تا از شتاب دهنده های تخصصی در حال کار استفاده کنند. آنها همچنین در اندازه گیری صحیح ورودی / خروجی و تراشه های اهرمی و قابلیت های چند تراشه ای – برای فشار دادن به شمارش هسته ای و عملکرد اما با ترکیب قالب های کوچکتر که بازده و هزینه های بهتری را ارائه می دهند ، آزادی دارند. “
در اصطلاحات بازو ، “chiplet” یک “صفحه” چاپ شده با لیتوگرافی از یک جز پردازنده است. یک بستر ، با توجه به نیازهای صاحب امتیاز / شریک ، ممکن است به طور قابل تصور از دو تراشه پشتیبانی کند.
استراتژی بردار Arm Neoverse V1، N2
نمونه کارها Arm’s Neoverse همان چیزی است که این امکان را برای تولیدکنندگان تراشه مانند Ampere فراهم کرده است که پا در برابر اینتل و AMD در بازار مرکز داده حرکت کنند. تا کنون ، این مورد به دو عامل در دسترس مجوزها قرار گرفته است: Neoverse E1 (“Helios”) ، که اجرای دستورالعمل های خارج از سفارش و چند رشته ای همزمان را در هم می آمیزد. و Neoverse N1 (“Ares”) ، که هدف آن متعادل سازی عملکرد خام در هر وات با مصرف کم انرژی است. این دو بازار از بازار HPC بودند که شرکایی مانند آمپر و مارول می توانستند به راحتی و بدون ریسک زیاد با آنها مقابله کنند.
Arm اکنون دو هسته دیگر به این مخلوط اضافه کرده است: N2 ، با طراحی در زمینه بهبود عملکرد N1. و V1 نام گیج کننده دارد. نه ، “V” به معنای “نسخه” نیست ، که ممکن است گیج کننده باشد وقتی شما در مورد نسخه دوم یک سیستم عامل صحبت می کنید. مخفف “بردار” است. همانطور که افشاگری های برگی روشن تر شد ، تولیدکنندگان با این هسته بهترین فرصت را برای ساخت پردازنده های تخصصی – شاید در حجم کم – خواهند داشت که می تواند جذابیت بیشتری برای مشتریان در کلاس های خاص ایجاد کند. به م institutionsسسات دانشگاهی فکر کنید که شبیه سازهای محاسبات کوانتومی یا ارائه دهندگان خدمات 5G در حال ساخت قابلیت های محاسبات ابری محلی در لبه مشتری هستند.
SVE ، گفت: Bergey ، “مجموعه کاملا جدیدی از برنامه نویسی برداری و ابزار دستکاری داده را برای توسعه دهندگان Arm فراهم می کند.” نمونه ای که وی ارائه داد ، شامل اجرای قبلی Arm در اجرای چندین دستورالعمل Single Instructive Multiple Data (SIMD ، “siméee” تلفظ می شود) است. این یک شکل اولیه از برداری است ، که در آن یک دستورالعمل واحد به طور همزمان بر روی یک جدول گسترده یا “تاپل” داده اجرا می شود. (GPU های امروزی اساساً موتورهای چند رشته ای SIMD هستند.) از نظر تاریخی ، خطوط لوله سیم کارت از پدیده ای به نام “واگرایی جریان کنترل” رنج می برند. این جایی است که رشته های محاسبه موازی در انتها مسیرهای مختلفی را طی می کنند و در کنار هم قرار گرفتن مشکل دارند. یک صحنه فیلم تعقیب و گریز را در کوهی تصور کنید که در آن اتومبیل در حال تعقیب و گریز است که به نظر می رسد یک میانبر در یک مسیر پر پیچ و خم در کنار کوه است تا در نهایت دوباره به آن صعود کند و در نهایت اتومبیل تعقیب شده خود را پیدا کند.

اجرای Arm از SVE برای جایگزینی م effectivelyثر SIMD خود ، SVE2 نامیده می شود ، آنچه را كه شركت “خودكش برداری” می نامد ، اعمال می كند. اگرچه دقیقاً مشخص نیست كه مهندسان Arm دقیقاً كدام رویكرد خودكشگری را انتخاب كرده اند (ممكن است IP خود را به دیگران مجوز دهد ، اما منبع باز نیست) ، یك روش محتمل در محافل دانشگاهی پرتاب شده است. این ایده که “بردار کل عملکرد” نامیده می شود ، اساساً این ایده است که ممکن است مسیرهای میانبر در اطراف کوه از قبل نقشه برداری شود و اطمینان حاصل شود که همه مسیرها در نقطه مناسب همگرایی دارند. تمام مدت زمانی که پردازنده ها برای سازگاری با مسیرهای اجرای خود صرف می کنند ، قابل بازیابی است.
Bergey ادعا می کند که این احیای زمان واگرایی از دست رفته عمدتاً مسوولیت آنچه را که می گوید افزایش عملکرد 3.5 برابر در آزمون های SIMD است ، در مقایسه با فناوری “Neon” SIMD که این شرکت برای Neoverse N1 استفاده کرده است ، است.
قدم گذاشتن روی پاشنه آشیل دریاچه یخی
اوایل ماه آوریل اینتل از نسل سوم سری Xeon (“دریاچه یخ”) مورد انتظار خود رونمایی کرد. در طی آن رونمایی ، مهندسان اینتل ذکر کردند که پسوندهای برداری همچنان یکی از ویژگی های اصلی معماری Xeon است. به عنوان مثال ، اینتل موارد قابل توجهی در توانایی پردازنده ها برای رمزگذاری و رمزگشایی ایجاد کرده است ، بنابراین کد اشیا را قادر می سازد تا به صورت رمزگذاری شده به تراشه تحویل داده شوند.
Sailesh Kottapali ، معمار ارشد اینتل ، در یک جلسه توجیهی با خبرنگاران توضیح داد: “ما دستورالعمل های برداری را معرفی کرده ایم که در واقع عملکرد رمزنگاری را چندین برابر بهبود می بخشد.” “ما از طریق برخی از این دستورالعمل های برداری که معرفی کرده ایم ، پیشرفت های چند برابری داریم.”
اما علاوه بر ارجاع مبهم VP شرکت سازنده اینتل ، لیزا اسپلمن به شرکت وی که طراحی مرجعی را می توان بر اساس آن بهینه و بهینه سازی کرد ، پیامی مبنی بر توسعه پذیری از طریق SVE چیزی نبود که اشخاص ثالث بتوانند انجام دهند. در مقابل ، Bergey Arm بر مفهوم شتاب سفارشی در رابطه با SVE تأکید کرد.
وی اظهار داشت ، افزودن SVE به Neoverse V1 (با نام رمز “زئوس”) ، برخی از پیشرفتهای بزرگ [Neoverse] N1: 1.8 برابر در دامنه بارهای برداری ، توان عملیاتی نقطه شناور را با SVE دو برابر کنید و از سایر دستورالعمل ها و پیشرفت های دیگر ، قدرت یادگیری ماشین را تا 4 برابر کنید. البته ، SVE توانایی جدید برنامه نویسی با عملکرد بالا و سازگار با توسعه را به HPC ارائه می دهد. “
ما از برگی خواستیم تا مشخص کند نقش Arm در هدایت معماری سرور دقیقاً در این مرحله چیست. آیا به سمت تفکیک پیش می رود و اگر چنین است ، آیا دیگر نباید تصور کنیم که کیفیت عملکرد عمدتاً یک عامل CPU یا SoC است؟
وی پاسخ داد: “ما همچنان در زمینه بهینه سازی معماری و به کارگیری تکنیک های جدید بسیار سخت کار می کنیم.” “اما من فکر می کنم یکی از جهات روشن صنعت ، اتصال فشرده با شتاب دهنده ها است … ما به دلیل اتصال فشرده با شتاب دهنده ها ، علاوه بر ادامه ساخت پردازنده ها همچنین عملکرد بیشتری دارند. “
در حالی که هرگونه مراجعه مستقیم را رد می کرد ، توضیحات Bergey به نظر می رسید که عمداً با اعلامیه اخیر انویدیا مبنی بر تولید CPU مبتنی بر Arm ، با کد “Grace” سازگار باشد و هدف آن تأمین نیازهای هوش مصنوعی در مرکز داده است ، با تاریخ حمل و نقل پیش بینی شده برای اوایل سال 2023. انویدیا در حال حاضر شتاب دهنده های GPU خود را با هدف هوش مصنوعی تولید می کند ، که چنان موفق شده اند که سرمایه گذاران و تحلیل گران از قبل گرافیک را به عنوان تجارت جانبی خود تصور می کنند.
انویدیا در اعلامیه خود هرگونه مراجعه مستقیم به Neoverse را کنار گذاشت. همچنین می توان تصور کرد که استراتژی انویدیا برای دستیابی به Arm نیازی به آن ندارد ، در صورتی که دولت انگلیس سرانجام جلوی تصرف را بگیرد. مطمئناً هنوز “جفت شدیدی” در این امتیاز وجود نداشته است.
اما به نظر می رسد Arm به عمد تصویری از معماری سیستم تفکیک شده آینده را با Neoverse در مرکز خود و یک اکوسیستم از معماران پسوند بردار که به دور آن می چرخند ، ترسیم می کند. اگر Arm بتواند این ویژگی را بیش از یک چشم انداز مبهم و نامشخص در یک محصول محکم ایجاد کند ، می تواند با موفقیت از یک جنبه از طراحی اینتل بهره ببرد که احتمالاً نمی تواند با زمان تغییر تغییر کند: تنها وابستگی آن به خود برای توسعه پذیری هسته اصلی.