
تشخیص یک کار اساسی بینایی است که هدف آن بومی سازی و تشخیص اشیاء در یک تصویر است. با این حال، فرآیند جمعآوری دادههای حاشیهنویسی دستی جعبههای محدودکننده یا ماسکهای نمونه خستهکننده و پرهزینه است، که اندازه واژگان تشخیص مدرن را به تقریباً 1000 کلاس شی محدود میکند. این مرتبه کوچکتر از واژگانی است که مردم برای توصیف دنیای بصری استفاده میکنند و بسیاری از دستهها را کنار گذاشته است. مدلهای بینایی و زبان اخیر (VLM)، مانند CLIP، قابلیتهای تشخیص بصری واژگان باز را از طریق یادگیری از جفتهای تصویر-متن در مقیاس اینترنت نشان دادهاند. این VLMها برای طبقهبندی صفر شات با استفاده از وزنهای مدل منجمد بدون نیاز به تنظیم دقیق اعمال میشوند، که در تضاد کامل با پارادایمهای موجود برای بازآموزی یا تنظیم دقیق VLMها برای وظایف تشخیص واژگان باز است.
به طور شهودی، برای تراز کردن محتوای تصویر با توضیحات متن در طول آموزش، VLM ها ممکن است ویژگی های حساس به منطقه و ویژگی های متمایز را یاد بگیرند که قابل انتقال به تشخیص شی هستند. با کمال تعجب، ویژگیهای یک VLM منجمد حاوی اطلاعات غنی است که هم برای توصیف اشکال شیء حساس به ناحیه (ستون دوم زیر) و هم برای طبقهبندی ناحیه (ستون سوم زیر) متمایز است. در واقع، گروهبندی ویژگیها میتواند به خوبی مرزهای شی را بدون هیچ نظارتی مشخص کند. این به ما انگیزه می دهد تا استفاده از VLM های منجمد را برای تشخیص اشیا با واژگان باز با هدف گسترش تشخیص فراتر از مجموعه محدود دسته های حاشیه نویسی کشف کنیم.
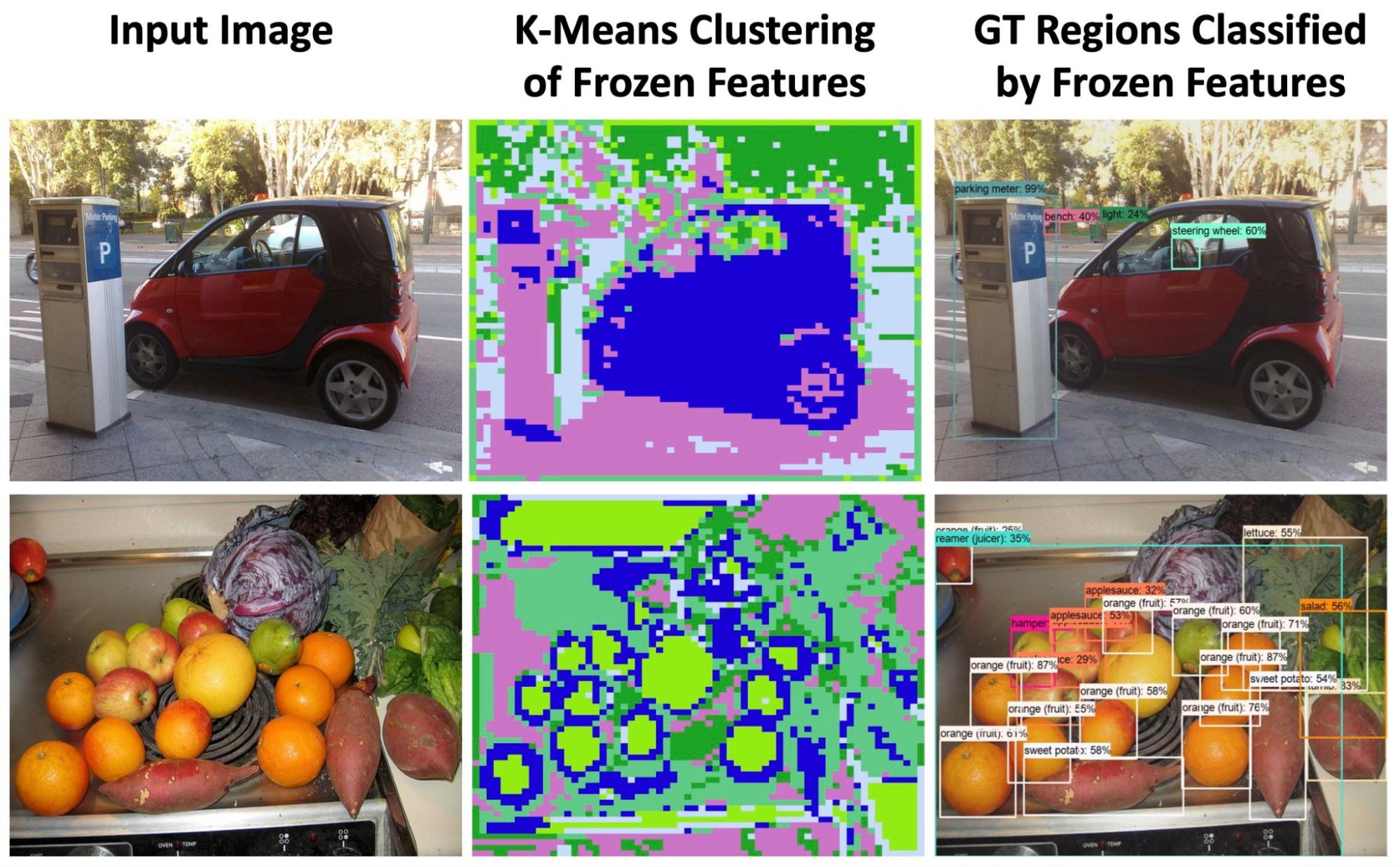 |
| ما پتانسیل دید منجمد و ویژگی های زبان را برای تشخیص واژگان باز بررسی می کنیم. گروه بندی ویژگی K-Means اطلاعات معنایی غنی و حساس به منطقه را نشان می دهد که در آن مرزهای شی به خوبی مشخص شده اند (ستون 2). همین ویژگیهای منجمد میتوانند مناطق حقیقت (GT) را به خوبی بدون تنظیم دقیق طبقهبندی کنند (ستون 3). |
در «F-VLM: تشخیص اشیاء با واژگان باز بر روی مدلهای بینایی و زبان منجمد»، ارائهشده در ICLR 2023، ما یک رویکرد تشخیص واژگان باز ساده و مقیاسپذیر را معرفی میکنیم که بر روی VLMهای منجمد ساخته شده است. F-VLM پیچیدگی آموزشی یک آشکارساز واژگان باز را به کمتر از یک آشکارساز استاندارد کاهش میدهد و نیاز به تقطیر دانش، پیشآموزش متناسب با تشخیص، یا یادگیری با نظارت ضعیف را از بین میبرد. ما نشان میدهیم که با حفظ دانش VLMهای از قبل آموزشدیده شده بهطور کامل، F-VLM فلسفه مشابهی با ViTDet حفظ میکند و یادگیری خاص آشکارساز را از دانش بینایی بیشتر در ستون فقرات آشکارساز جدا میکند. ما همچنین کد F-VLM را به همراه یک نسخه نمایشی در صفحه پروژه خود منتشر می کنیم.
یادگیری بر روی بینایی منجمد و مدل های زبان
ما می خواهیم تا حد امکان دانش VLM های از پیش آموزش دیده را با هدف به حداقل رساندن تلاش و هزینه مورد نیاز برای تطبیق آنها برای تشخیص واژگان باز حفظ کنیم. ما از یک رمزگذار تصویر VLM منجمد به عنوان ستون فقرات آشکارساز و یک رمزگذار متن برای ذخیره سازی جاسازیهای متن شناسایی واژگان مجموعه داده آفلاین استفاده میکنیم. ما این ستون فقرات VLM را می گیریم و یک سر آشکارساز وصل می کنیم، که نواحی شی را برای محلی سازی پیش بینی می کند و امتیازهای تشخیص را که احتمال وجود جعبه شناسایی شده از یک دسته خاص را نشان می دهد، خروجی می دهد. امتیازهای تشخیص شباهت کسینوس ویژگیهای ناحیه (مجموعهای از جعبههای مرزی که سر آشکارساز خروجی میدهد) و جاسازیهای متن دستهبندی است. تعبیههای متن دستهبندی با تغذیه نام دستهها از طریق مدل متنی VLM از پیش آموزشدیده (که دارای هر دو مدل تصویر و متن) r به دست میآید.
رمزگذار تصویر VLM از دو بخش تشکیل شده است: 1) استخراج کننده ویژگی و 2) لایه ادغام ویژگی. ما از استخراج کننده ویژگی برای آموزش سر آشکارساز استفاده می کنیم، که تنها مرحله ای است که آموزش می دهیم (در داده های تشخیص استاندارد)، تا به ما اجازه دهد مستقیماً از وزنه های منجمد استفاده کنیم و دانش معنایی غنی را به ارث ببریم (مانند دسته های دم بلند مانند مارتینی، کلاه فدورا، نشان) از ستون فقرات VLM. تلفات تشخیص شامل رگرسیون جعبه و تلفات طبقه بندی می شود.
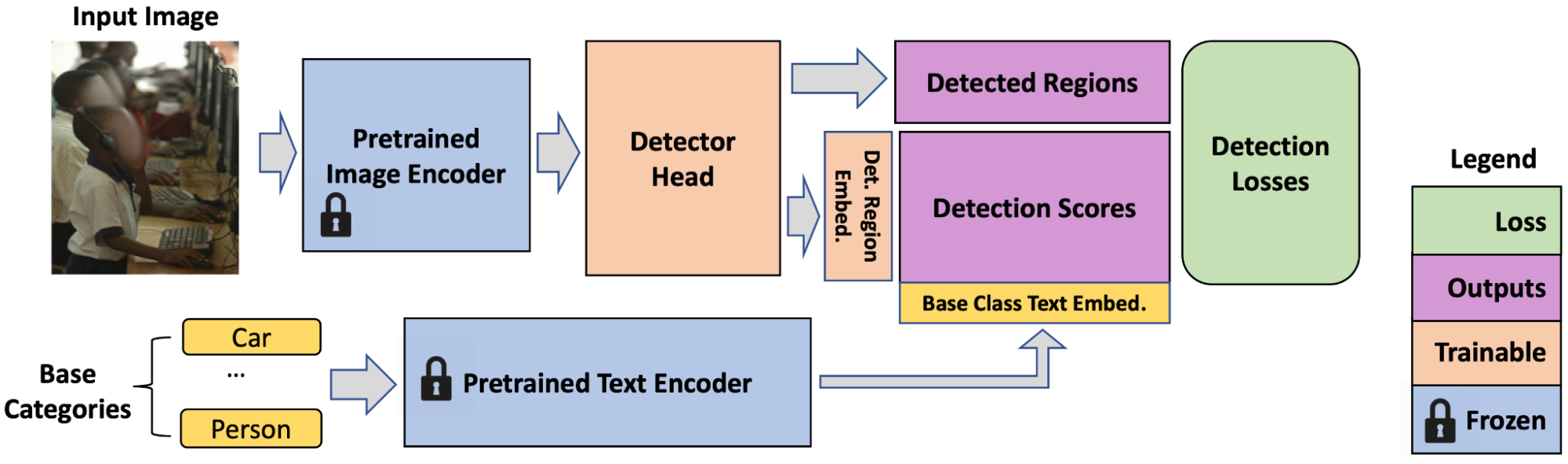 |
| در زمان آموزش، F-VLM به سادگی یک آشکارساز است که آخرین لایه طبقهبندی با جاسازیهای متن دستهبندی پایه جایگزین شده است. |
شناسایی واژگان باز در سطح منطقه
توانایی انجام بازشناسی واژگان باز در سطح منطقه (یعنی سطح جعبه مرزی بر خلاف سطح تصویر) جدایی ناپذیر F-VLM است. از آنجایی که ویژگیهای ستون فقرات منجمد شدهاند، برای دستههای آموزشی (مانند دونات، گورخر) بیش از حد مناسب نیستند و میتوانند مستقیماً برای طبقهبندی در سطح منطقه برش داده شوند. F-VLM این طبقه بندی واژگان باز را فقط در زمان آزمون انجام می دهد. برای به دست آوردن ویژگی های VLM برای یک منطقه، لایه ادغام ویژگی را روی ویژگی های خروجی ستون فقرات برش داده شده اعمال می کنیم. از آنجایی که لایه ادغام به ورودی های با اندازه ثابت نیاز دارد، به عنوان مثال، 7×7 برای ستون فقرات CLIP ResNet50 (R50)، ویژگی های منطقه را با لایه ROI-Align (در زیر نشان داده شده) برش داده و اندازه آن را تغییر می دهیم. برخلاف روشهای تشخیص واژگان باز موجود، ما مناطق تصویر RGB را برش نمیدهیم و اندازه آنها را تغییر نمیدهیم و جاسازیهای آنها را در یک فرآیند آفلاین جداگانه ذخیره نمیکنیم، بلکه سر آشکارساز را در یک مرحله آموزش میدهیم. این سادهتر است و باعث استفاده کارآمدتر از فضای ذخیرهسازی دیسک میشود. علاوه بر این، ویژگیهای ناحیه VLM را در طول آموزش برش نمیدهیم زیرا ویژگیهای ستون فقرات ثابت هستند.
علیرغم اینکه هرگز در مناطق آموزش داده نشده است، ویژگی های منطقه برش داده شده قابلیت تشخیص واژگان باز خوب را حفظ می کند. با این حال، مشاهده میکنیم که ویژگیهای منطقه برشخورده به اندازه کافی به کیفیت محلیسازی مناطق حساس نیستند، به عنوان مثال، یک جعبه ضعیف در مقابل کاملاً موضعی هر دو ویژگیهای مشابهی دارند. این ممکن است برای طبقه بندی خوب باشد، اما برای تشخیص مشکل ساز است، زیرا ما به نمرات تشخیص نیاز داریم تا کیفیت محلی سازی را نیز منعکس کند. برای رفع این مشکل، میانگین هندسی را برای ترکیب امتیازات VLM با امتیازهای تشخیص برای هر منطقه و دسته اعمال میکنیم. نمرات VLM نشان دهنده احتمال بودن یک جعبه تشخیص با توجه به VLM از قبل آموزش دیده از یک دسته خاص است. نمرات تشخیص توزیع احتمال کلاس هر جعبه را بر اساس شباهت ویژگیهای منطقه و جاسازیهای متن ورودی نشان میدهد.
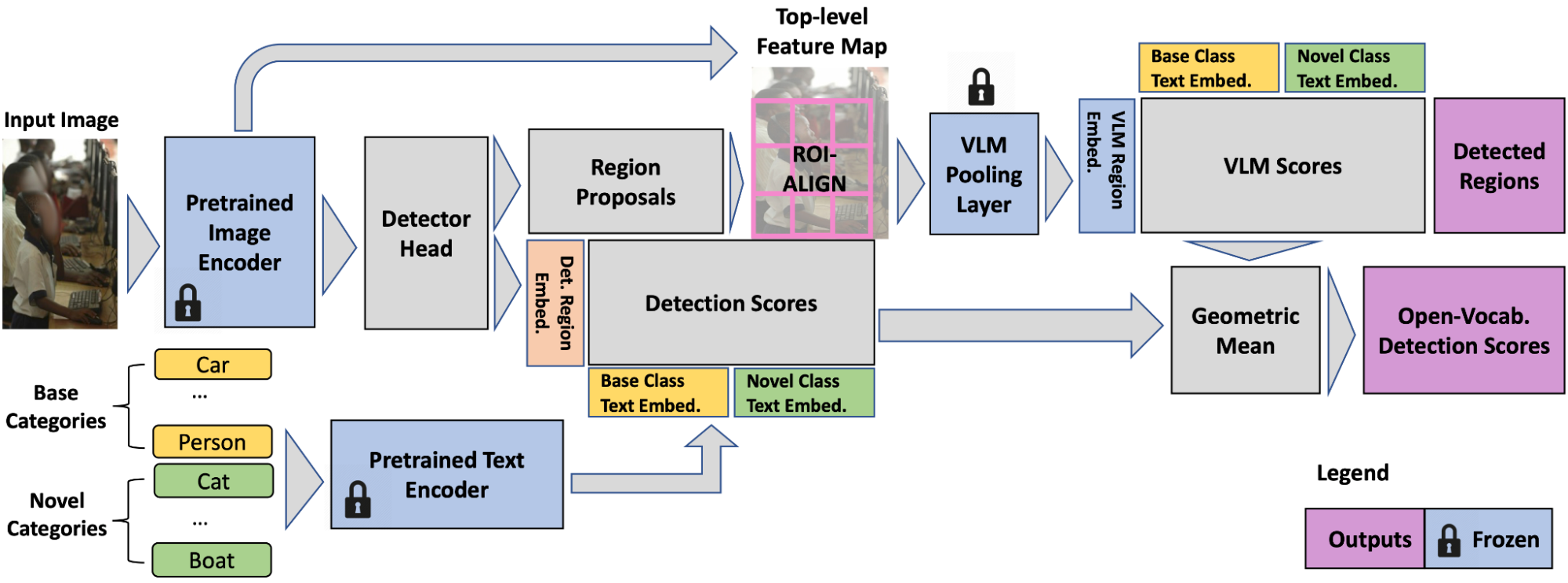 |
| در زمان آزمایش، F-VLM از پیشنهادهای منطقه برای برش ویژگی های سطح بالای ستون فقرات VLM و محاسبه امتیاز VLM در هر منطقه استفاده می کند. سر آشکارساز آموزش دیده جعبه های تشخیص و ماسک ها را فراهم می کند، در حالی که نمرات تشخیص نهایی ترکیبی از نمرات تشخیص و VLM است. |
ارزیابی
ما F-VLM را به معیار تشخیص واژگان باز محبوب LVIS اعمال می کنیم. در سطح سیستم، بهترین F-VLM به 32.8 میانگین دقت (AP) در دستههای نادر (APr) دست مییابد که با 6.5 ماسک APr و بسیاری از رویکردهای دیگر مبتنی بر تقطیر دانش، پیشآموزش، یا تمرین مشترک با نظارت ضعیف F-VLM ویژگی مقیاس پذیری قوی با ظرفیت مدل منجمد را نشان می دهد، در حالی که تعداد پارامترهای قابل آموزش ثابت است. علاوه بر این، F-VLM در وظایف تشخیص انتقال (به عنوان مثال، مجموعه داده های Objects365 و Ego4D) به سادگی با جایگزینی واژگان بدون تنظیم دقیق مدل، تعمیم و مقیاس بندی می کند. ما مدلهای آموزشدیده LVIS را روی مجموعهدادههای محبوب Objects365 آزمایش میکنیم و نشان میدهیم که این مدل میتواند بدون آموزش دادههای تشخیص درون دامنه، بسیار خوب کار کند.
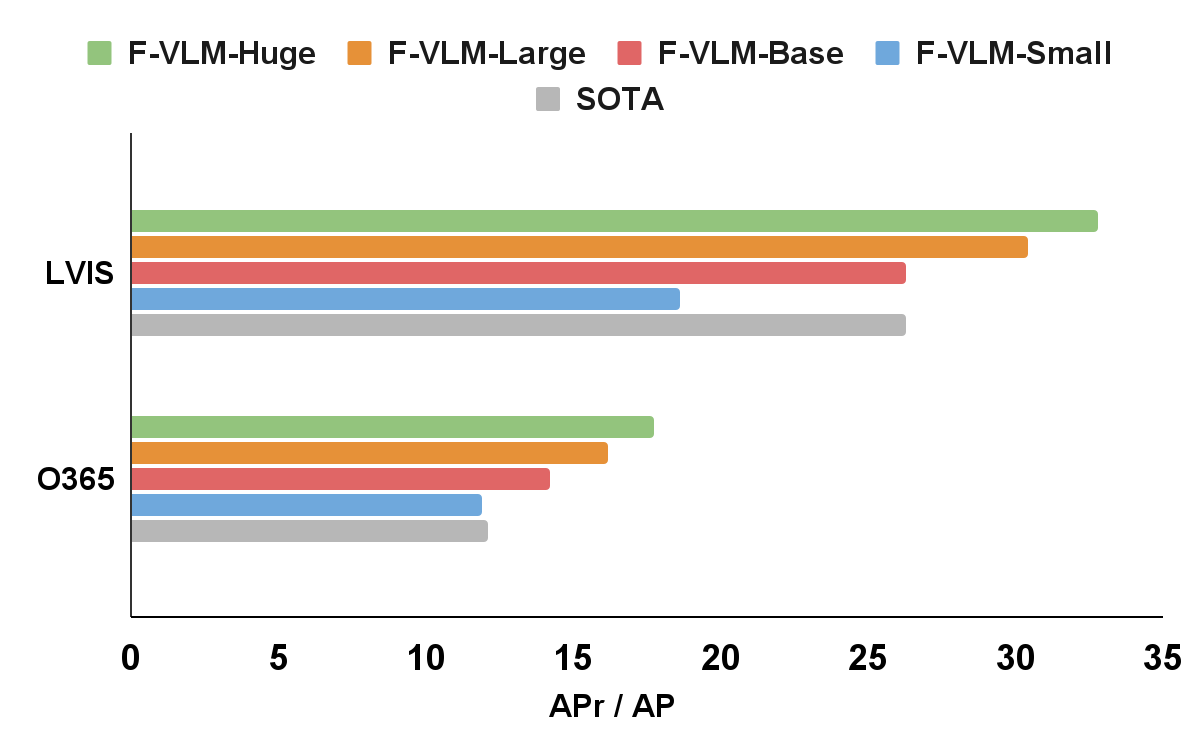 |
| F-VLM از وضعیت هنر (SOTA) در معیار تشخیص واژگان باز LVIS و تشخیص شی انتقال عملکرد بهتری دارد. در محور x، ماسک متریک LVIS AP را در دستههای نادر (APr) و جعبه متریک Objects365 (O365) را در همه دستهها نشان میدهیم. اندازه ستون فقرات آشکارساز به شرح زیر است: کوچک (R50)، پایه (R50x4)، بزرگ (R50x16)، بزرگ (R50x64). نامگذاری از قرارداد CLIP پیروی می کند. |
ما F-VLM را در تشخیص واژگان باز و وظایف تشخیص انتقال تجسم می کنیم (در زیر نشان داده شده است). در LVIS و Objects365، F-VLM به درستی اشیاء جدید و معمولی را تشخیص می دهد. یکی از مزایای کلیدی تشخیص واژگان باز، آزمایش بر روی داده های خارج از توزیع با دسته بندی هایی است که کاربران در حال پرواز ارائه می دهند. برای تجسم بیشتر در مورد مجموعه داده های LVIS، Objects365 و Ego4D به مقاله F-VLM مراجعه کنید.
 |
| F-VLM واژگان باز و تشخیص انتقال. بالا: تشخیص واژگان باز در LVIS. ما فقط دسته بندی های جدید را برای وضوح نشان می دهیم. پایین: انتقال به مجموعه داده Objects365 تشخیص دقیق بسیاری از دسته ها را نشان می دهد. دستههای جدید شناسایی شدند: فدورا، مارتینی، پرچم، کلاه ایمنی فوتبال (LVIS). اسلاید (Objects365). |
کارایی آموزش
ما نشان میدهیم که F-VLM میتواند با منابع محاسباتی بسیار کمتر در جدول زیر به عملکرد بالا دست یابد. در مقایسه با رویکرد پیشرفته، F-VLM می تواند با 226 برابر منابع کمتر و 57 برابر زمان ساعت دیواری سریعتر، عملکرد بهتری داشته باشد. جدا از صرفه جویی در منابع آموزشی، F-VLM دارای پتانسیل برای صرفه جویی قابل توجهی در حافظه در زمان تمرین با اجرای ستون فقرات در حالت استنتاج است. سیستم F-VLM تقریباً به سرعت یک آشکارساز استاندارد در زمان استنتاج کار می کند، زیرا تنها اضافه شده یک لایه تمرکز واحد روی ویژگی های منطقه شناسایی شده است.
| روش | APr | دوره های آموزشی | هزینه آموزش (در هر ساعت هسته) |
صرفه جویی در هزینه های آموزشی | ||||||||||
| SOTA | 26.3 | 460 | 8000 | 1x | ||||||||||
| F-VLM | 32.8 | 118 | 565 | 14 برابر | ||||||||||
| F-VLM | 31.0 | 14.7 | 71 | 113x | ||||||||||
| F-VLM | 27.7 | 7.4 | 35 | 226x |
ما نتایج اضافی را با استفاده از دستور العمل های آموزشی کوتاهتر Detectron2 (دوره 12 و 36) ارائه می دهیم و با استفاده از ستون فقرات منجمد عملکرد قوی مشابهی را نشان می دهیم. تنظیمات پیش فرض با رنگ خاکستری مشخص شده است.
| ستون فقرات | جیتر در مقیاس بزرگ | #دوران | اندازه دسته | APr | ||||||||||
| R50 | 12 | 16 | 18.1 | |||||||||||
| R50 | 36 | 64 | 18.5 | |||||||||||
| R50 | ✓ | 100 | 256 | 18.6 | ||||||||||
| R50x64 | 12 | 16 | 31.9 | |||||||||||
| R50x64 | 36 | 64 | 32.6 | |||||||||||
| R50x64 | ✓ | 100 | 256 | 32.8 |
نتیجه
ما F-VLM را ارائه میدهیم – یک روش تشخیص واژگان باز ساده که از قدرت مدلهای زبان بینایی بزرگ منجمد شده از قبل آموزش دیده برای تشخیص اشیاء جدید استفاده میکند. این کار بدون نیاز به تقطیر دانش، پیشآموزش متناسب با تشخیص، یا یادگیری با نظارت ضعیف انجام میشود. رویکرد ما صرفه جویی قابل توجهی در محاسبات ارائه می دهد و نیاز به برچسب های سطح تصویر را برطرف می کند. F-VLM در تشخیص واژگان باز در معیار LVIS در سطح سیستم به پیشرفتهترین پیشرفتها دست مییابد و تشخیص انتقال بسیار رقابتی را در سایر مجموعههای داده نشان میدهد. ما امیدواریم که این مطالعه بتواند تحقیقات بیشتر در زمینه تشخیص اشیاء جدید را تسهیل کند و به جامعه کمک کند VLM های منجمد را برای طیف وسیع تری از وظایف بینایی کشف کند.
سپاسگزاریها
این کار توسط Weicheng Kuo، Yin Cui، Xiuye Gu، AJ Piergiovanni و Anelia Angelova انجام شده است. مایلیم از همکاران خود در Google Research برای مشاوره و بحث های مفیدشان تشکر کنیم.