
محاسبات تطبیقی به توانایی یک سیستم یادگیری ماشین برای تنظیم رفتار خود در پاسخ به تغییرات محیط اشاره دارد. در حالی که شبکه های عصبی مرسوم دارای یک عملکرد و ظرفیت محاسباتی ثابت هستند، یعنی تعداد یکسانی FLOP را برای پردازش ورودی های مختلف صرف می کنند، یک مدل با محاسبات تطبیقی و پویا، بسته به پیچیدگی ورودی، بودجه محاسباتی را که برای پردازش هر ورودی اختصاص می دهد تعدیل می کند. ورودی
محاسبات تطبیقی در شبکه های عصبی به دو دلیل کلیدی جذاب است. اول، مکانیزمی که سازگاری را معرفی می کند، یک سوگیری استقرایی را ارائه می دهد که می تواند نقش کلیدی در حل برخی از وظایف چالش برانگیز داشته باشد. برای مثال، فعال کردن تعداد متفاوتی از مراحل محاسباتی برای ورودیهای مختلف میتواند در حل مسائل حسابی که نیاز به مدلسازی سلسلهمراتب با عمقهای مختلف دارند، حیاتی باشد. دوم، این توانایی را به پزشکان میدهد تا هزینه استنتاج را از طریق انعطافپذیری بیشتر ارائه شده توسط محاسبات پویا تنظیم کنند، زیرا این مدلها را میتوان تنظیم کرد تا FLOPهای بیشتری را برای پردازش یک ورودی جدید صرف کنند.
شبکه های عصبی را می توان با استفاده از توابع مختلف یا بودجه های محاسباتی برای ورودی های مختلف تطبیق پذیر ساخت. یک شبکه عصبی عمیق را می توان به عنوان تابعی در نظر گرفت که هم بر اساس ورودی و هم بر اساس پارامترهای آن یک نتیجه را خروجی می دهد. برای پیاده سازی انواع تابع تطبیقی، زیرمجموعه ای از پارامترها به طور انتخابی بر اساس ورودی فعال می شوند، فرآیندی که به عنوان محاسبات شرطی شناخته می شود. انطباق بر اساس نوع تابع در مطالعات انجام شده روی ترکیبی از متخصصان مورد بررسی قرار گرفته است، که در آن پارامترهای کم فعال شده برای هر نمونه ورودی از طریق مسیریابی تعیین می شوند.
حوزه دیگری از تحقیقات در محاسبات تطبیقی شامل بودجه های محاسباتی پویا است. برخلاف شبکههای عصبی استاندارد، مانند T5، GPT-3، PalM، و ViT، که بودجه محاسباتی آنها برای نمونههای مختلف ثابت است، تحقیقات اخیر نشان دادهاند که بودجههای محاسباتی تطبیقی میتوانند عملکرد را در وظایفی که ترانسفورماتورها کوتاه میآیند، بهبود بخشند. بسیاری از این آثار با استفاده از عمق پویا برای تخصیص بودجه محاسباتی به سازگاری دست می یابند. به عنوان مثال، الگوریتم زمان محاسبه تطبیقی (ACT) برای ارائه یک بودجه محاسباتی تطبیقی برای شبکههای عصبی مکرر پیشنهاد شد. ترانسفورماتور جهانی با وابسته کردن بودجه محاسباتی به تعداد لایههای ترانسفورماتور مورد استفاده برای هر نمونه ورودی یا نشانه، الگوریتم ACT را به ترانسفورماتورها گسترش میدهد. مطالعات اخیر، مانند PonderNet، رویکرد مشابهی را در حین بهبود مکانیسمهای توقف پویا دنبال میکنند.
در مقاله “محاسبات تطبیقی با توالی ورودی الاستیک”، مدل جدیدی را معرفی می کنیم که از محاسبات تطبیقی به نام استفاده می کند. AdaTape. این مدل یک معماری مبتنی بر ترانسفورماتور است که از مجموعهای پویا از نشانهها برای ایجاد توالی ورودی الاستیک استفاده میکند و دیدگاه منحصربهفردی را در مورد سازگاری در مقایسه با کارهای قبلی ارائه میدهد. AdaTape از مکانیزم خواندن نوار تطبیقی برای تعیین تعداد متفاوتی از نشانههای نوار استفاده میکند که بر اساس پیچیدگی ورودی به هر ورودی اضافه میشوند. AdaTape برای پیاده سازی بسیار ساده است، یک دستگیره موثر برای افزایش دقت در صورت نیاز فراهم می کند، اما در مقایسه با سایر خطوط پایه تطبیقی بسیار کارآمدتر است زیرا به جای عمق مدل، مستقیماً سازگاری را به دنباله ورودی تزریق می کند. در نهایت، Adatape عملکرد بهتری را در وظایف استاندارد، مانند طبقهبندی تصویر، و همچنین وظایف الگوریتمی ارائه میدهد، در حالی که کیفیت مطلوب و مبادله هزینه را حفظ میکند.
ترانسفورماتور محاسباتی تطبیقی با توالی ورودی الاستیک
AdaTape از هر دو نوع تابع تطبیقی و بودجه محاسباتی پویا استفاده می کند. به طور خاص، برای دستهای از توالیهای ورودی پس از توکنسازی (به عنوان مثال، طرح خطی تکههای غیر همپوشانی از یک تصویر در ترانسفورماتور بینایی)، AdaTape از یک بردار که هر ورودی را نشان میدهد برای انتخاب پویا دنبالهای با اندازه متغیر از توکنهای نوار استفاده میکند.
AdaTape از بانکی از توکنها به نام «بانک نوار» استفاده میکند تا تمام توکنهای نوار کاندید را که از طریق مکانیسم خواندن نوار تطبیقی با مدل تعامل دارند، ذخیره کند. ما دو روش مختلف را برای ایجاد بانک نوار بررسی می کنیم: بانک ورودی محور و بانک قابل یادگیری.
ایده کلی از ورودی محور بانک عبارت است از استخراج بانکی از نشانهها از ورودی در حالی که از رویکردی متفاوت نسبت به توکنایزر مدل اصلی برای نگاشت ورودی خام به دنبالهای از نشانههای ورودی استفاده میکند. این امکان دسترسی پویا و بر اساس تقاضا به اطلاعات ورودی را فراهم می کند که با استفاده از دیدگاه متفاوتی به دست می آید، به عنوان مثال، وضوح تصویر متفاوت یا سطح متفاوتی از انتزاع.
در برخی موارد، توکنسازی در سطوح مختلف انتزاع امکانپذیر نیست، بنابراین یک بانک نواری مبتنی بر ورودی امکانپذیر نیست، مانند زمانی که تقسیم بیشتر هر گره در یک ترانسفورماتور گراف دشوار است. برای پرداختن به این موضوع، AdaTape رویکرد کلی تری را برای تولید بانک نوار با استفاده از مجموعه ای از بردارهای قابل آموزش به عنوان نشانه های نوار ارائه می دهد. این رویکرد به عنوان بانک قابل یادگیری و می تواند به عنوان یک لایه جاسازی دیده شود که در آن مدل می تواند به صورت پویا توکن ها را بر اساس پیچیدگی مثال ورودی بازیابی کند. بانک قابل یادگیری AdaTape را قادر میسازد تا یک بانک نواری انعطافپذیرتر ایجاد کند و به آن امکان میدهد بودجه محاسباتی خود را به صورت پویا بر اساس پیچیدگی هر نمونه ورودی تنظیم کند، به عنوان مثال، نمونههای پیچیدهتر توکنهای بیشتری را از بانک بازیابی میکنند، که به مدل اجازه نمیدهد. فقط از دانش ذخیره شده در بانک استفاده کنید، بلکه FLOPهای بیشتری را برای پردازش آن صرف کنید، زیرا ورودی اکنون بزرگتر است.
در نهایت، توکن های نوار انتخاب شده به ورودی اصلی اضافه می شوند و به لایه های ترانسفورماتور زیر تغذیه می شوند. برای هر لایه ترانسفورماتور، توجه چند سر یکسان در تمام توکن های ورودی و نوار استفاده می شود. با این حال، دو شبکه مختلف پیشخور (FFN) استفاده میشود: یکی برای همه نشانهها از ورودی اصلی و دیگری برای همه نشانههای نوار. ما کیفیت کمی بهتر را با استفاده از شبکه های فید فوروارد جداگانه برای توکن های ورودی و نوار مشاهده کردیم.
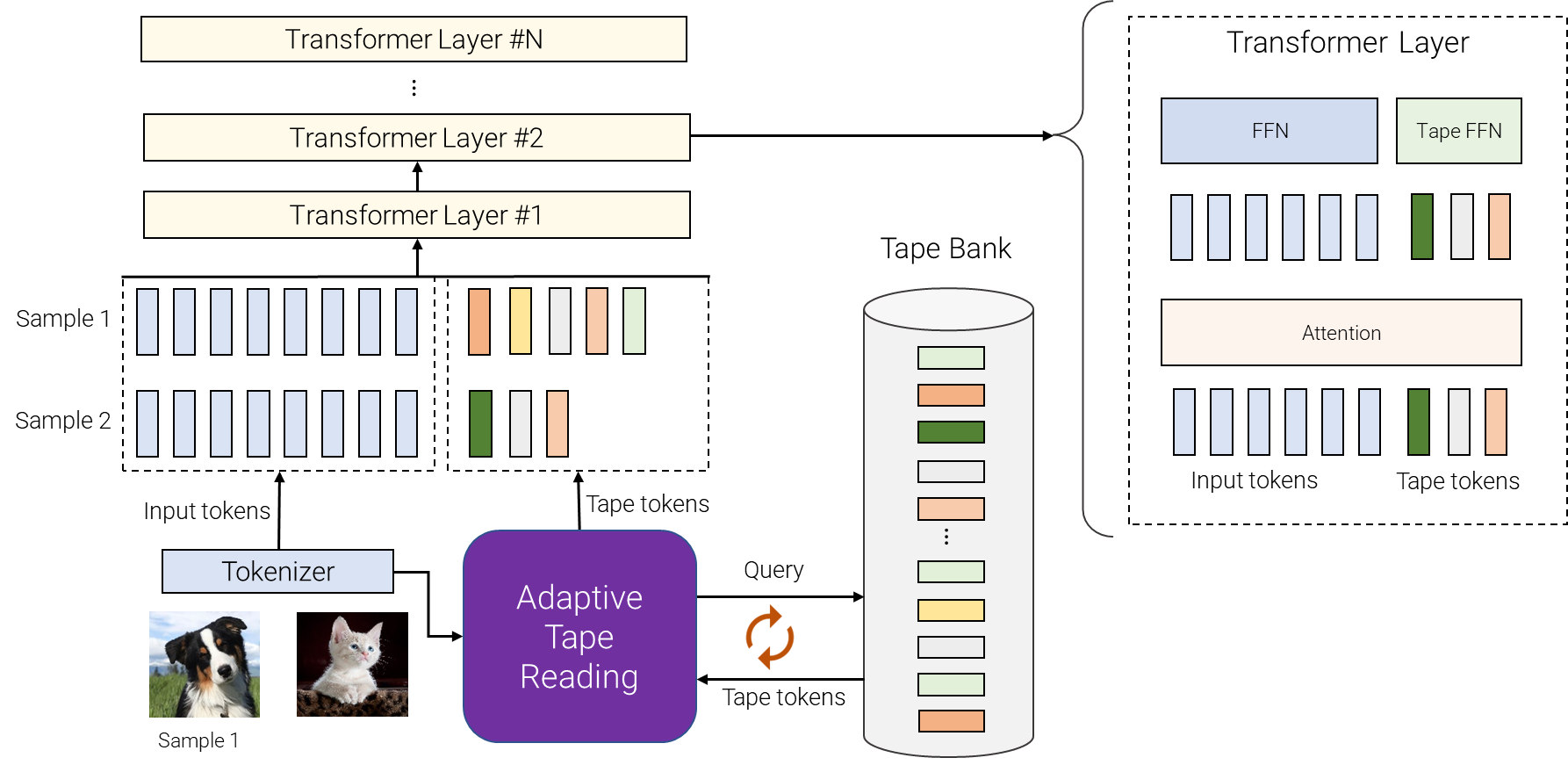 |
| مروری بر AdaTape. برای نمونه های مختلف، تعداد متغیری از توکن های مختلف را از بانک نوار انتخاب می کنیم. بانک نوار را می توان از ورودی هدایت کرد، به عنوان مثال، با استخراج برخی اطلاعات ریز دانه اضافی یا می تواند مجموعه ای از بردارهای قابل آموزش باشد. خواندن نوار تطبیقی برای انتخاب بازگشتی توالیهای مختلف نشانههای نوار، با طولهای متغیر، برای ورودیهای مختلف استفاده میشود. سپس این نشانه ها به سادگی به ورودی ها اضافه می شوند و به رمزگذار ترانسفورماتور تغذیه می شوند. |
AdaTape سوگیری استقرایی مفیدی را ارائه می دهد
ما AdaTape را بر روی برابری ارزیابی می کنیم، یک کار بسیار چالش برانگیز برای ترانسفورماتور استاندارد، برای مطالعه اثر سوگیری های القایی در AdaTape. با تکلیف برابری، با توجه به دنباله های 1s، 0s و -1s، مدل باید زوج بودن یا عجیب بودن تعداد 1s در دنباله را پیش بینی کند. برابری ساده ترین زبان منظم غیر رایگان یا دوره ای است، اما شاید در کمال تعجب، این کار توسط Transformer استاندارد غیرقابل حل باشد.
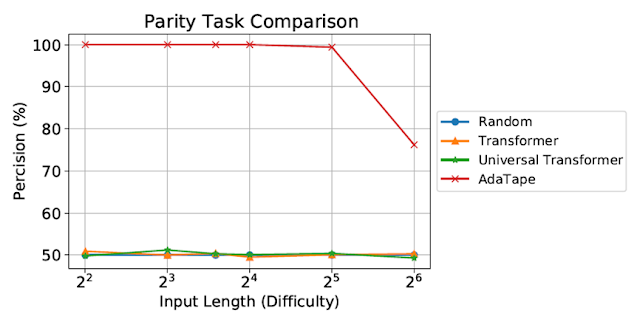 |
| ارزیابی تکلیف برابری ترانسفورماتور استاندارد و ترانسفورماتور جهانی قادر به انجام این کار نبودند، هر دو عملکرد را در سطح یک خط پایه حدس تصادفی نشان دادند. |
ترانسفورماتور استاندارد و ترانسفورماتور یونیورسال علیرغم ارزیابی روی توالی های کوتاه و ساده، قادر به انجام وظیفه برابری نبودند زیرا قادر به حفظ شمارنده در مدل نیستند. با این حال، AdaTape از تمام خطوط پایه بهتر عمل می کند، زیرا یک بازگشت سبک وزن را در مکانیسم انتخاب ورودی خود گنجانده است، و یک سوگیری القایی را ارائه می دهد که امکان نگهداری ضمنی یک شمارنده را فراهم می کند، که در ترانسفورماتورهای استاندارد امکان پذیر نیست.
ارزیابی در طبقه بندی تصاویر
ما همچنین AdaTape را در کار طبقه بندی تصویر ارزیابی می کنیم. برای انجام این کار، AdaTape را روی ImageNet-1K از ابتدا آموزش دادیم. شکل زیر دقت AdaTape و روش های پایه، از جمله A-ViT، و Universal Transformer ViT (UViT و U2T) را در برابر سرعت آنها (اندازه گیری شده به عنوان تعداد تصاویر، پردازش شده توسط هر کد، در ثانیه) نشان می دهد. از نظر کیفیت و هزینه، AdaTape بسیار بهتر از خطوط پایه ترانسفورماتور تطبیقی جایگزین عمل می کند. از نظر کارایی، مدل های بزرگتر AdaTape (از نظر تعداد پارامترها) سریعتر از خطوط پایه کوچکتر هستند. چنین نتایجی با یافتههای کار قبلی که نشان میدهد معماریهای عمق مدل تطبیقی برای بسیاری از شتابدهندهها، مانند TPU، مناسب نیستند، مطابقت دارد.
 |
| ما AdaTape را با آموزش روی ImageNet از ابتدا ارزیابی می کنیم. برای A-ViT، ما نه تنها نتایج آنها را از روی مقاله گزارش میکنیم، بلکه A-ViT را با آموزش از ابتدا، یعنی A-ViT (ما) دوباره پیادهسازی میکنیم. |
مطالعه رفتار AdaTape
علاوه بر عملکرد آن در کار برابری و ImageNet-1K، ما همچنین رفتار انتخاب نشانه AdaTape را با یک بانک ورودی محور در مجموعه اعتبارسنجی JFT-300M ارزیابی کردیم. برای درک بهتر رفتار مدل، نتایج انتخاب نشانه را روی مدل تجسم کردیم بانک ورودی محور به عنوان نقشه های حرارتی، که در آن رنگ های روشن تر به این معنی است که موقعیت بیشتر انتخاب می شود. نقشه های حرارتی نشان می دهد که AdaTape بیشتر پچ های مرکزی را انتخاب می کند. این با دانش قبلی ما مطابقت دارد، زیرا وصلههای مرکزی معمولاً آموزندهتر هستند – به ویژه در زمینه مجموعه دادههایی با تصاویر طبیعی، جایی که شی اصلی در وسط تصویر است. این نتیجه هوش AdaTape را برجسته می کند، زیرا می تواند به طور موثر وصله های اطلاعاتی بیشتری را برای بهبود عملکرد خود شناسایی و اولویت بندی کند.
 |
| ما نقشه حرارتی انتخاب نوار نوار AdaTape-B/32 (سمت چپ) و AdaTape-B/16 (راست) را تجسم می کنیم. رنگ گرمتر / روشن تر به این معنی است که پچ در این موقعیت بیشتر انتخاب می شود. |
نتیجه
AdaTape با طول دنباله های الاستیک تولید شده توسط مکانیسم خواندن نوار تطبیقی مشخص می شود. این همچنین یک سوگیری القایی جدید را معرفی می کند که AdaTape را قادر می سازد تا دارای پتانسیل حل وظایفی باشد که هم برای ترانسفورماتورهای استاندارد و هم برای ترانسفورماتورهای تطبیقی موجود چالش برانگیز هستند. با انجام آزمایشهای جامع بر روی معیارهای تشخیص تصویر، نشان میدهیم که AdaTape از ترانسفورماتورهای استاندارد و ترانسفورماتورهای معماری تطبیقی بهتر عمل میکند زمانی که محاسبه ثابت نگه داشته میشود.
قدردانی
یکی از نویسندگان این پست، مصطفی دهقانی، هم اکنون در Google DeepMind است.