پیشرفتهای اخیر در مدلهای زبان بزرگ (LLM) بسیار امیدوارکننده است، همانطور که در توانایی آنها برای حل مسائل عمومی در چند شات و ضربه صفر تنظیمات، حتی بدون آموزش صریح در مورد این وظایف. این قابل توجه است زیرا در تنظیم چند شات، LLM ها تنها با چند نمونه سوال-پاسخ قبل از دادن یک سوال آزمایشی ارائه می شوند. حتی چالشبرانگیزتر، تنظیم صفر شات است، جایی که LLM مستقیماً با آن درخواست میشود فقط سوال تستی.
اگرچه راهاندازی چند شات بهطور چشمگیری میزان دادههای مورد نیاز برای انطباق یک مدل برای یک مورد خاص را کاهش داده است، هنوز مواردی وجود دارد که تولید اعلانهای نمونه میتواند چالشبرانگیز باشد. برای مثال، ساخت دست ساز حتی تعداد کمی دمو برای طیف وسیعی از وظایف تحت پوشش مدلهای همه منظوره میتواند دشوار یا برای کارهای غیرممکن باشد. به عنوان مثال، برای کارهایی مانند خلاصه کردن مقالات طولانی یا مواردی که نیاز به دانش دامنه دارند (مثلاً پاسخگویی به سؤالات پزشکی)، ایجاد پاسخ های نمونه می تواند چالش برانگیز باشد. در چنین شرایطی، مدلهایی با عملکرد صفر شات بالا مفید هستند، زیرا نیازی به تولید اعلان دستی نیست. با این حال، عملکرد صفر شات معمولا ضعیف تر است زیرا LLM با راهنمایی ارائه نمی شود و بنابراین مستعد خروجی های جعلی است.
در «استدلال صفر-شات بهتر با انگیزههای خودسازگار»، منتشر شده در ACL 2023، ما پیشنهاد میکنیم خودسازگاری مبتنی بر سازگاری (COSP) برای رفع این معضل COSP یک روش درخواست خودکار صفر شات برای مسائل استدلالی است که با دقت انتخاب و ساخته می شود. شبهنمایش هایی برای LLM ها با استفاده از نمونه های بدون برچسب (که معمولاً به راحتی به دست می آیند) و پیش بینی های خود مدل ها. با COSP، شکاف عملکرد بین ضربات صفر و چند شلیک را تا حد زیادی کاهش میدهیم و در عین حال عمومیت مطلوب درخواستهای ضربه صفر را حفظ میکنیم. ما این را با “انگیزه خود تطبیقی جهانی” (USP)، پذیرفته شده در EMNLP 2023 دنبال می کنیم، که در آن ایده را به طیف گسترده ای از عمومی وظایف درک زبان طبیعی (NLU) و تولید زبان طبیعی (NLG) و کارایی آن را نشان می دهد.
ترغیب LLM ها با خروجی های خودشان
دانستن اینکه LLM ها از تظاهرات سود می برند و حداقل دارند مقداری تواناییهای شات صفر، ما تعجب کردیم که آیا خروجیهای شات صفر مدل میتوانند به عنوان نمایشهایی برای این مدل عمل کنند که خودش را تحریک کند. چالش این است که راهحلهای صفر شات ناقص هستند، و ما خطر ارائه نمایشهایی با کیفیت پایین به LLM ها داریم، که میتواند بدتر از عدم نمایش باشد. در واقع، شکل زیر نشان میدهد که افزودن یک نمایش صحیح به یک سؤال میتواند به حل صحیح سؤال آزمون (Demo1 با سؤال) منجر شود، در حالی که افزودن نمایش نادرست (دمو 2 + سؤالات، نسخه آزمایشی 3 با سؤالات) منجر به پاسخهای نادرست میشود. . بنابراین، ما باید نمایش های قابل اعتماد خود تولید شده را انتخاب کنیم.
 |
| نمونه ورودی و خروجی برای کارهای استدلالی، که نیاز به روش انتخاب دقیق طراحی شده برای نمایش های درون متنی را نشان می دهد (مجموعه داده های MultiArith و مدل PaLM-62B): (1) شات صفر زنجیره ای از فکر بدون نسخه ی نمایشی: منطق صحیح اما پاسخ اشتباه. (2) نسخه ی نمایشی صحیح (Demo1) و پاسخ صحیح. (3) نسخه ی نمایشی صحیح اما تکراری (Demo2) منجر به خروجی های تکراری می شود. (4) نسخه ی نمایشی اشتباه (Demo3) منجر به پاسخ اشتباه می شود. اما (5) ترکیب Demo3 و Demo1 دوباره به یک پاسخ صحیح منجر می شود. |
COSP از یک مشاهدات کلیدی LLM استفاده می کند: اینکه پیش بینی های مطمئن و ثابت به احتمال زیاد صحیح هستند. البته این مشاهدات به این بستگی دارد که برآورد عدم قطعیت LLM چقدر خوب است. خوشبختانه، در مدلهای بزرگ، کارهای قبلی نشان میدهد که تخمینهای عدم قطعیت قوی هستند. از آنجایی که اندازهگیری اطمینان فقط به پیشبینیهای مدل نیاز دارد، نه برچسبها، پیشنهاد میکنیم از آن به عنوان یک پروکسی صحت استفاده کنیم. سپس خروجی های با اطمینان بالا و ورودی های آنها به عنوان استفاده می شود شبه-تظاهرات.
با این بهعنوان پیشفرض شروع، ما اعتماد مدل به خروجی آن را بر اساس سازگاری خود تخمین میزنیم و از این معیار برای انتخاب نمایشهای خودساخته قوی استفاده میکنیم. ما چندین بار از LLMها با درخواست زنجیره افکار (CoT) یک سوال مشابه را می پرسیم. برای هدایت مدل برای تولید طیف وسیعی از دلایل احتمالی و پاسخهای نهایی، تصادفی بودن را که توسط یک فراپارامتر «دما» کنترل میشود، اضافه میکنیم. در یک حالت شدید، اگر مدل 100٪ مطمئن باشد، باید هر بار پاسخ های نهایی یکسان را ارائه دهد. سپس آنتروپی پاسخها را برای سنجش عدم قطعیت محاسبه میکنیم – پاسخهایی که سازگاری بالایی دارند و LLM برای آنها مطمئنتر است، احتمالاً درست هستند و انتخاب خواهند شد.
با فرض اینکه wه با مجموعه ای از سوالات بدون برچسب ارائه می شوند، روش COSP به شرح زیر است:
- هر سوال بدون برچسب را در یک LLM وارد کنید، با نمونهبرداری چندین بار از مدل، دلایل و پاسخهای متعددی به دست آورید. متداولترین پاسخها برجسته میشوند و به دنبال آن نمرهای وجود دارد که سازگاری پاسخها را در چندین خروجی نمونهگیری میکند (بالاتر بهتر است). علاوه بر طرفداری از پاسخهای ثابتتر، ما همچنین تکرار را در یک پاسخ جریمه میکنیم (یعنی با کلمات یا عبارات تکراری) و تنوع نمایشهای انتخابی را تشویق میکنیم. ما ترجیح را نسبت به خروجیهای ثابت، غیر تکراری و متنوع در قالب یک تابع امتیازدهی رمزگذاری میکنیم که از مجموع وزنی سه امتیاز برای انتخاب شبه نمایشهای خودساخته تشکیل شده است.
- ما شبه تظاهرات را به سؤالات آزمون الحاق می کنیم، آنها را به LLM می دهیم و پاسخ پیش بینی شده نهایی را به دست می آوریم.
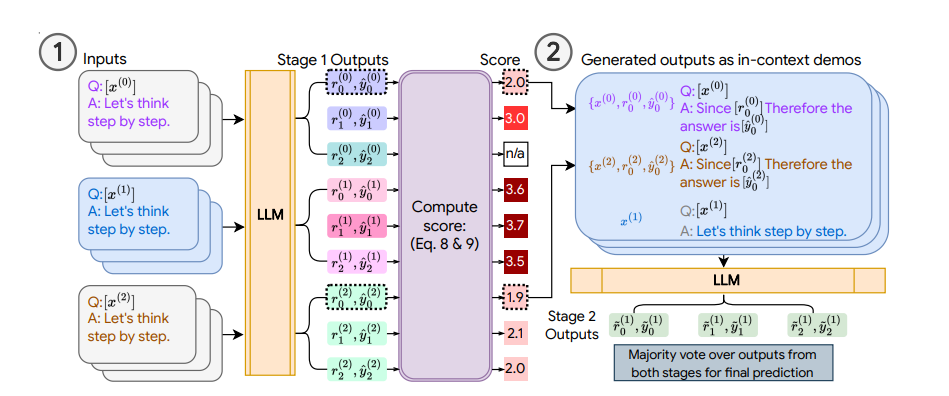 |
| تصویر COSP: در مرحله 1 (ترک کرد، ما چندین بار CoT صفر شات را اجرا می کنیم تا مجموعه ای از نمایش ها (که هر کدام شامل سؤال، منطق تولید شده و پیش بینی است) ایجاد کرده و امتیازی را تعیین کنیم. در مرحله 2 (درست، سؤال آزمایشی فعلی را با شبه دموها (جعبه های آبی) تقویت می کنیم و دوباره LLM را پرس و جو می کنیم. اکثریت رای بر خروجی های هر دو مرحله، پیش بینی نهایی را تشکیل می دهد. |
COSP بر روی وظایف پاسخگویی به سؤالات با تحریک CoT تمرکز می کند که اندازه گیری سازگاری خود آسان است زیرا سؤالات دارای پاسخ های صحیح منحصر به فرد هستند. اما این می تواند برای کارهای دیگر دشوار باشد، مانند پاسخگویی به سؤالات باز یا کارهای تولیدی که پاسخ های منحصر به فرد ندارند (مثلاً خلاصه سازی متن). برای رفع این محدودیت، USP را معرفی می کنیم که در آن رویکرد خود را به سایر وظایف عمومی NLP تعمیم می دهیم:
- طبقه بندی (CLS): مشکلاتی که در آنها می توانیم احتمال هر کلاس را با استفاده از لجیت خروجی شبکه عصبی هر کلاس محاسبه کنیم. به این ترتیب، میتوانیم عدم قطعیت را بدون نمونهگیری چندگانه با محاسبه آنتروپی توزیع لاجیت اندازهگیری کنیم.
- تولید فرم کوتاه (SFG): مشکلاتی مانند پاسخ به سؤال که در آن میتوانیم از همان روش ذکر شده در بالا برای COSP استفاده کنیم، اما، در صورت لزوم، بدون مرحله تولید منطق.
- نسل بلند (LFG): مشکلاتی مانند خلاصهسازی و ترجمه، که در آن سؤالات اغلب باز هستند و بعید است خروجیها یکسان باشند، حتی اگر LLM قطعی باشد. در این مورد از an استفاده می کنیم متریک همپوشانی که در آن میانگین را محاسبه می کنیم به صورت جفتی امتیاز ROUGE بین خروجی های مختلف به همان پرس و جو.
 |
| تصویر USP در وظایف نمونه (طبقه بندی، QA و خلاصه متن). مشابه COSP، LLM ابتدا پیشبینیهایی را روی یک مجموعه داده بدون برچسب تولید میکند که خروجیهای آن با آنتروپی لاجیت، سازگاری یا تراز، بسته به نوع کار، امتیازدهی میشوند، و شبه نمایشها از این جفتهای ورودی-خروجی انتخاب میشوند. در مرحله 2، نمونه های آزمایشی با شبه نمایشی برای پیش بینی افزوده می شوند. |
ما امتیازات اطمینان مربوطه را بسته به نوع کار در مجموعه نمونههای آزمایشی بدون برچسب فوقالذکر محاسبه میکنیم. پس از امتیازدهی، مشابه COSP، پاسخهای مطمئن، متنوع و کمتر تکراری را انتخاب میکنیم تا یک مجموعه شبه نمایشی تولید شده توسط مدل را تشکیل دهیم. ما در نهایت LLM را دوباره در قالب چند شات با این شبه نمایش ها پرس و جو می کنیم تا پیش بینی های نهایی را در کل مجموعه آزمایش به دست آوریم.
نتایج کلیدی
برای COSP، ما روی مجموعهای از شش مسئله استدلالی حسابی و عقلانی تمرکز میکنیم و با 0-shot-CoT مقایسه میکنیم (یعنی فقط “بیایید قدم به قدم فکر کنیم”). ما از خودسازگاری در همه خطوط مبنا استفاده می کنیم به طوری که آنها تقریباً از همان مقدار منابع محاسباتی COSP استفاده می کنند. در مقایسه با سه LLM، می بینیم که COSP صفر شات به طور قابل توجهی از خط پایه صفر شات استاندارد بهتر عمل می کند.
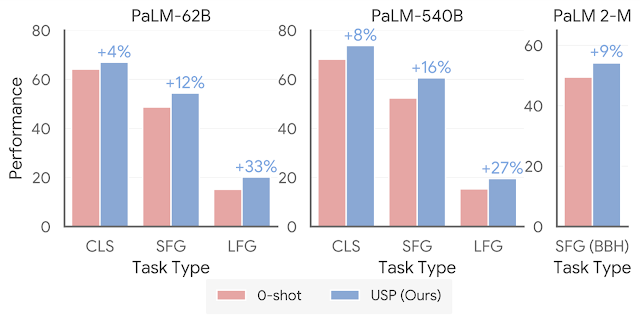 |
| USP عملکرد 0 شوت را به طور قابل توجهی بهبود می بخشد. “CLS” به طور متوسط 15 کار طبقه بندی است. “SFG” میانگین پنج وظیفه تولید کوتاه است. “LFG” میانگین دو کار خلاصه سازی است. “SFG (BBH)” میانگینی از تمام کارهای سخت BIG-Bench است که هر سوال در قالب SFG است. |
برای USP، ما تجزیه و تحلیل خود را به طیف وسیع تری از وظایف، از جمله بیش از 25 طبقه بندی، تولید فرم کوتاه، و وظایف تولید با فرم طولانی گسترش می دهیم. با استفاده از مدلهای پیشرفته PalM 2، ما همچنین در برابر مجموعه وظایف سخت BIG-Bench آزمایش میکنیم که در آن LLMها قبلاً در مقایسه با افراد ضعیف عمل میکردند. ما نشان میدهیم که در همه موارد، USP مجدداً از خطوط پایه بهتر عمل میکند و برای ارائه نمونههای طلایی رقابتی است.
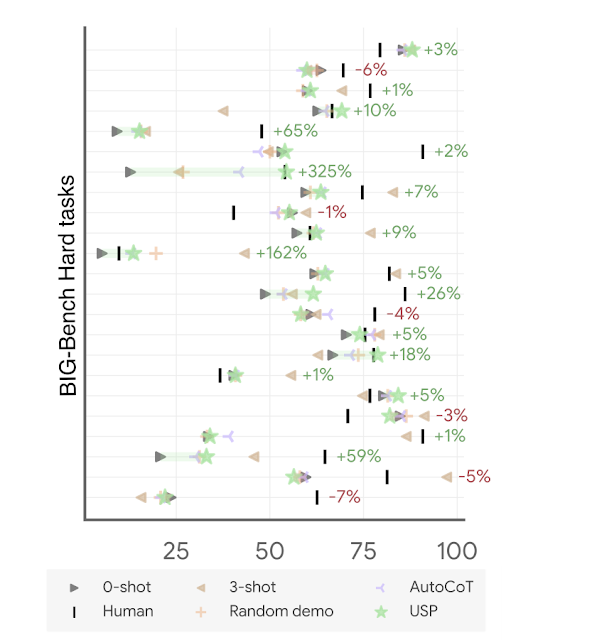 |
| دقت در کارهای سخت BIG-Bench با PalM 2-M (هر خط نشان دهنده وظیفه مجموعه است). افزایش/از دست دادن USP (ستاره های سبز) نسبت به 0-شات استاندارد (مثلث های سبز) به درصد نشان داده شده است. «انسان» به عملکرد متوسط انسان اشاره دارد. “AutoCoT” و “تصادفی نسخه ی نمایشی” پایه هایی هستند که ما در مقاله با آنها مقایسه می کنیم. و “3-shot” عملکرد چند شات برای سه دموی دست ساز در قالب CoT است. |
ما همچنین مکانیسم کار USP را با تأیید مشاهدات کلیدی بالا در مورد رابطه بین اطمینان و صحت تجزیه و تحلیل کردیم و دریافتیم که در اکثریت قریب به اتفاق موارد، USP پیشبینیهای مطمئنی را انتخاب میکند که به احتمال زیاد در همه انواع وظایف در نظر گرفته شده بهتر هستند. در شکل زیر نشان داده شده است.
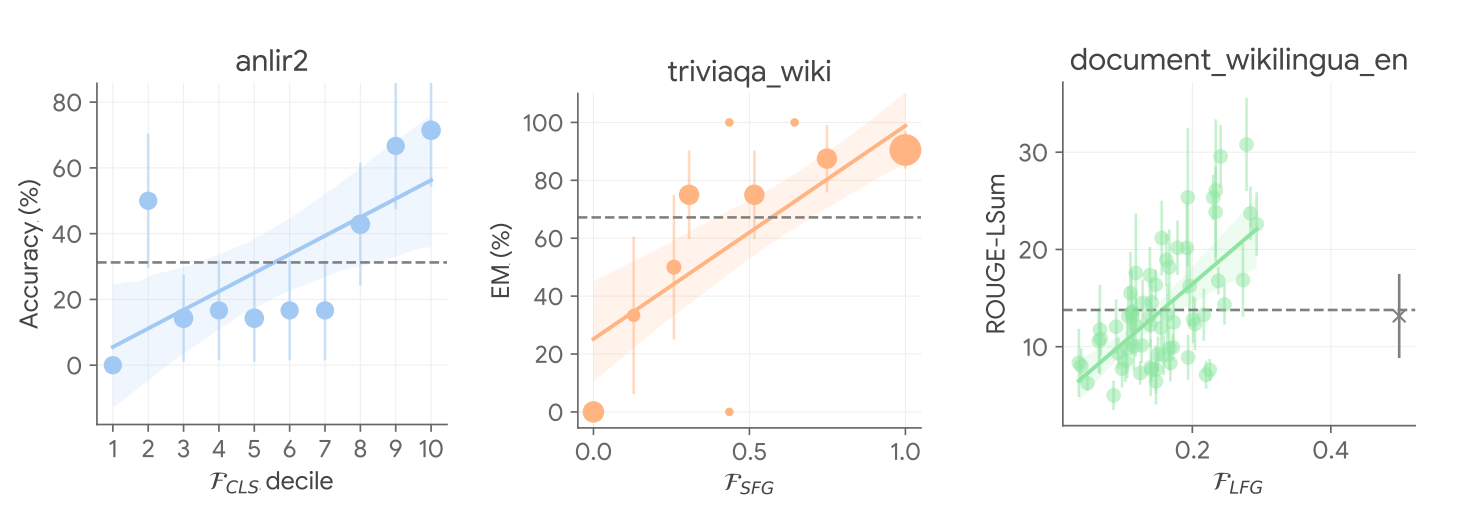 |
| USP پیش بینی های مطمئنی را انتخاب می کند که به احتمال زیاد بهتر هستند. معیارهای عملکرد واقعی در برابر امتیازات اطمینان USP در وظایف انتخابی در انواع مختلف وظایف (آبی: CLS، نارنجی: SFG، سبز: LFG) با PaLM-540B. |
نتیجه
استنتاج صفر شات یک قابلیت بسیار مورد توجه LLM های مدرن است، اما موفقیتی که در آن چالش های منحصر به فردی ایجاد می کند. ما COSP و USP را پیشنهاد میکنیم، خانوادهای از تکنیکهای هشدار خودکار همه کاره و بدون شات که برای طیف گستردهای از وظایف قابل استفاده است. ما پیشرفت زیادی را نسبت به خطوط پایه پیشرفته نسبت به چندین کار و ترکیب مدل نشان میدهیم.
سپاسگزاریها
این کار توسط Xingchen Wan، Ruoxi Sun، Hootan Nakhost، Hanjun Dai، Julian Martin Eisenschlos، Sercan Ö انجام شده است. آریک، و توماس فایستر. مایلیم از Jinsung Yoon Xuezhi Wang برای ارائه نظرات مفید و سایر همکاران در Google Cloud AI Research برای بحث و بازخوردشان تشکر کنیم.