
ویدئوها به بخش مهمی از زندگی روزمره ما تبدیل شدهاند و حوزههایی مانند سرگرمی، آموزش و ارتباطات را در بر میگیرند. با این حال، درک محتوای ویدیوها یک کار چالش برانگیز است زیرا ویدیوها اغلب حاوی رویدادهای متعددی هستند که در مقیاس های زمانی مختلف رخ می دهند. به عنوان مثال، ویدئویی از یک موشر که سگها را قبل از اینکه همه با هم مسابقه دهند به سورتمه سگ میبرد، شامل یک رویداد طولانی (سگها در حال کشیدن سورتمه) و یک رویداد کوتاه (سگها به سورتمه میچسبند). یکی از راههای تشویق به تحقیق در درک ویدیو، از طریق کار زیرنویسهای متراکم ویدیو است که شامل بومیسازی موقت و توصیف همه رویدادها در یک ویدیوی چند دقیقهای است. این با زیرنویس یک تصویر و زیرنویس استاندارد ویدیویی که شامل توصیف ویدیوهای کوتاه با تنها جمله.
سیستمهای زیرنویس ویدئویی متراکم کاربردهای گستردهای دارند، مانند در دسترس قرار دادن فیلمها برای افراد دارای اختلالات بینایی یا شنوایی، تولید خودکار فصلهایی برای ویدیوها، یا بهبود جستجوی لحظات ویدیویی در پایگاههای داده بزرگ. با این حال، رویکردهای کنونی زیرنویس ویدئویی متراکم دارای محدودیتهای متعددی هستند – برای مثال، آنها اغلب حاوی اجزای بسیار تخصصی ویژه کار هستند که ادغام آنها در مدلهای پایه قدرتمند را به چالش میکشد. علاوه بر این، آنها اغلب به طور انحصاری بر روی مجموعه داده های مشروح دستی آموزش می بینند که به دست آوردن آنها بسیار دشوار است و از این رو راه حلی مقیاس پذیر نیستند.
در این پست، «Vid2Seq: پیشآموزش در مقیاس بزرگ یک مدل زبان بصری برای زیرنویسهای ویدیویی متراکم» را معرفی میکنیم که در CVPR 2023 نمایش داده میشود. معماری Vid2Seq یک مدل زبان را با نشانههای زمانی خاص تقویت میکند و به آن اجازه میدهد به طور یکپارچه مرزهای رویداد را پیشبینی کند و توضیحات متنی در همان دنباله خروجی. برای پیشآموزش این مدل یکپارچه، از ویدیوهای روایتشده بدون برچسب با فرمولبندی مجدد مرزهای جملات گفتار رونویسیشده بهعنوان مرزهای شبه رویداد، و استفاده از جملات گفتاری رونویسیشده بهعنوان شرح شبه رویداد استفاده میکنیم. مدل Vid2Seq حاصل که روی میلیونها ویدیوی روایتشده از قبل آموزش داده شده است، وضعیت هنر را در انواع معیارهای زیرنویس ویدیویی متراکم از جمله YouCook2، ViTT و ActivityNet Captions بهبود میبخشد. Vid2Seq همچنین به خوبی به تنظیمات زیرنویس ویدیویی متراکم چند شات، وظیفه نوشتن شرح پاراگراف ویدیو، و وظیفه شرح استاندارد ویدیو تعمیم میدهد. در نهایت، کد Vid2Seq را نیز در اینجا منتشر کرده ایم.
 |
| Vid2Seq یک مدل زبان بصری است که شرح رویدادهای متراکم را همراه با زمینه زمانی آنها در یک ویدیو با تولید یک دنباله از نشانهها پیشبینی میکند. |
یک مدل زبان بصری برای زیرنویس ویدیویی متراکم
معماریهای ترانسفورماتور چندوجهی، وضعیت هنر را در طیف گستردهای از وظایف ویدئویی، مانند تشخیص عمل، بهبود بخشیدهاند. با این حال، انطباق چنین معماری با وظیفه پیچیده محلی سازی مشترک و شرح رویدادها در ویدیوهای چند دقیقه ای کار ساده ای نیست.
برای یک نمای کلی از نحوه دستیابی به این هدف، یک مدل زبان بصری را با نشانههای زمانی خاص (مانند نشانههای نوشتاری) که نشاندهنده مُهرهای زمانی گسستهشده در ویدیو هستند، شبیه به Pix2Seq در حوزه فضایی، تقویت میکنیم. با توجه به ورودیهای بصری، مدل Vid2Seq حاصل میتواند هم به عنوان ورودی گرفته شود و هم دنبالههایی از متن و نشانههای زمانی تولید کند. اول، این مدل Vid2Seq را قادر میسازد تا اطلاعات زمانی ورودی گفتار رونویسی شده را که به صورت یک دنباله از نشانهها پخش میشود، درک کند. دوم، این امر به Vid2Seq اجازه میدهد تا به طور مشترک شرحهای رویداد متراکم را پیشبینی کند و به طور موقت آنها را در ویدیو ثابت کند، در حالی که یک تنها دنباله ای از نشانه ها
معماری Vid2Seq شامل یک رمزگذار بصری و یک رمزگذار متن است که به ترتیب فریمهای ویدیو و ورودی گفتار رونویسی شده را رمزگذاری میکنند. سپس رمزگذاریهای بهدستآمده به یک رمزگشای متنی ارسال میشوند، که بهطور خودکار توالی خروجی زیرنویسهای رویداد متراکم را همراه با محلیسازی زمانی آنها در ویدیو پیشبینی میکند. معماری با یک ستون فقرات بصری قدرتمند و یک مدل زبان قوی راه اندازی شده است.
 |
| نمای کلی مدل Vid2Seq: ما شرح رویداد متراکم را به عنوان یک مشکل ترتیب به دنباله فرموله میکنیم، با استفاده از نشانههای زمانی خاص به مدل اجازه میدهیم توالیهایی از نشانهها را بهطور یکپارچه درک و تولید کند که حاوی اطلاعات معنایی متنی و اطلاعات محلیسازی زمانی است که هر جمله متنی را در ویدیو پایهگذاری میکند. . |
پیش آموزش در مقیاس بزرگ بر روی ویدیوهای روایت نشده
با توجه به ماهیت متراکم کار، مجموعه دستی حاشیه نویسی برای زیرنویس ویدیویی متراکم گران است. از این رو ما مدل Vid2Seq را با استفاده از unlabeled از قبل آموزش می دهیم ویدیوهای روایت شده، که به راحتی در مقیاس در دسترس هستند. به طور خاص، ما از مجموعه داده YT-Temporal-1B استفاده می کنیم که شامل 18 میلیون ویدیوی روایت شده است که طیف گسترده ای از دامنه ها را پوشش می دهد.
ما از جملات گفتاری رونویسی شده و مهرهای زمانی مربوط به آنها به عنوان نظارت استفاده می کنیم که به عنوان یک دنباله از نشانه ها پخش می شوند. ما Vid2Seq را با یک هدف مولد از قبل آموزش میدهیم که به رمزگشا میآموزد که توالی گفتار رونویسی شده را فقط با ورودیهای بصری پیشبینی کند، و یک هدف حذف نویز که یادگیری چندوجهی را با نیاز به مدل برای پیشبینی نشانههای پوشانده شده با توالی گفتار رونویسی شده پر سر و صدا و ورودیهای بصری تشویق میکند. به ویژه، نویز به دنباله گفتار با پوشاندن تصادفی گستره نشانه ها اضافه می شود.
 |
| Vid2Seq روی ویدیوهای روایتشده بدون برچسب با هدف تولیدی (بالا) و یک هدف حذف کننده (پایین). |
نتایج در مورد معیارهای زیرنویس متراکم پایین دست
مدل Vid2Seq از پیش آموزشدیده حاصل را میتوان در وظایف پاییندستی با یک هدف حداکثر احتمال ساده با استفاده از اجبار معلم تنظیم کرد (یعنی پیشبینی نشانه بعدی با توجه به نشانههای حقیقت زمینی قبلی). پس از تنظیم دقیق، Vid2Seq به طور قابلتوجهی وضعیت هنر را در سه معیار زیرنویس ویدئویی متراکم پایین دست (ActivityNet Captions، YouCook2 و ViTT) و دو معیار زیرنویس کلیپ ویدیویی (MSR-VTT، MSVD) بهبود میبخشد. در مقاله خود ما مطالعات فرسایشی اضافی، نتایج کیفی، و همچنین نتایج در تنظیمات چند شات و در کار زیرنویس پاراگراف ویدیویی ارائه میکنیم.
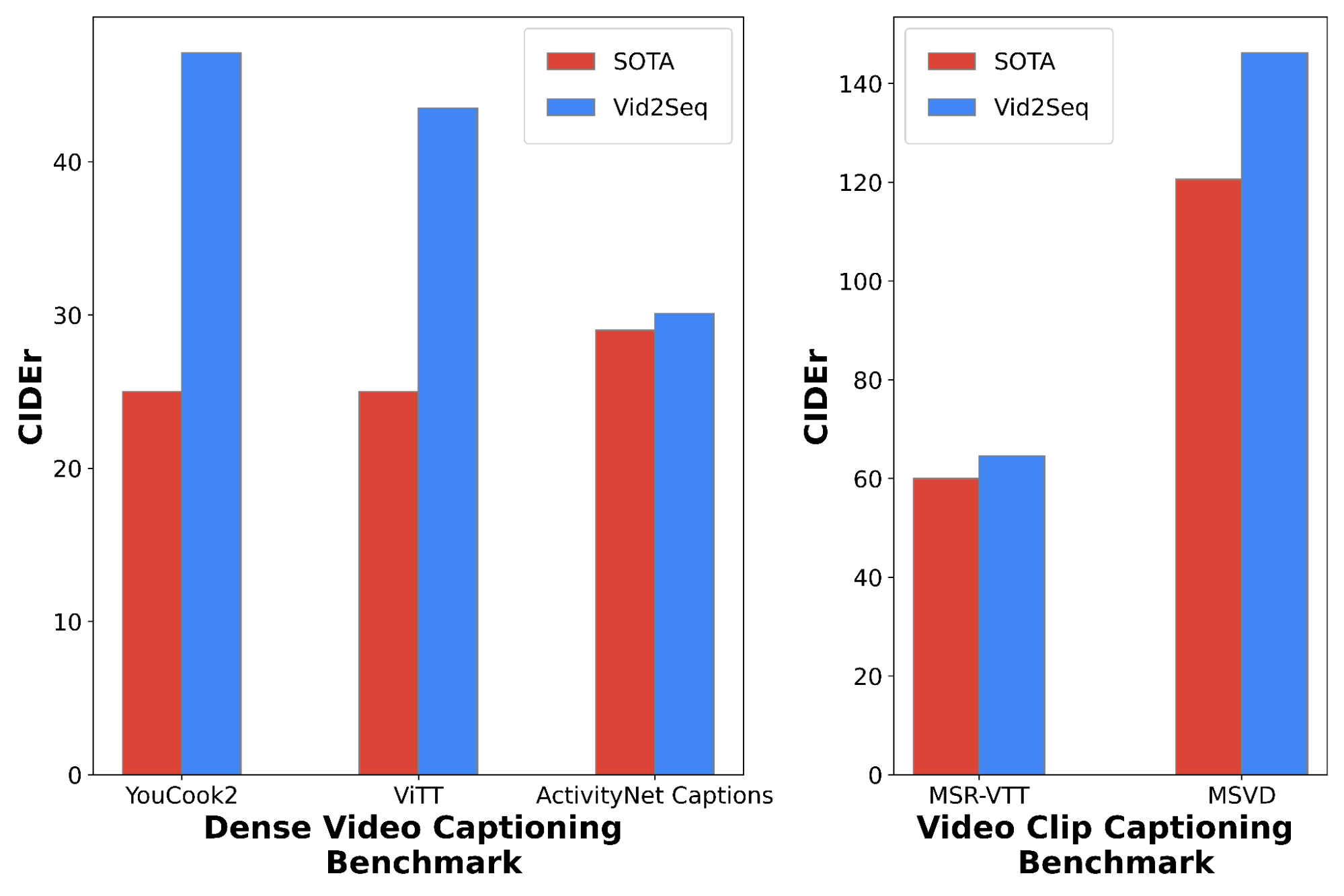 |
| مقایسه با روش های پیشرفته برای زیرنویس ویدیویی متراکم (ترک کرد) و برای زیرنویس کلیپ (درست، در متریک CIDEr (بالاتر بهتر است). |
نتیجه
ما Vid2Seq را معرفی میکنیم، یک مدل زبان بصری جدید برای زیرنویسهای متراکم ویدیویی که به سادگی تمام مرزهای رویداد و شرحها را به عنوان یک دنباله از نشانهها پیشبینی میکند. Vid2Seq میتواند به طور موثری روی ویدیوهای روایتشده بدون برچسب در مقیاس از قبل آموزش داده شود و در معیارهای مختلف زیرنویس ویدئویی متراکم پایین دست، به نتایج پیشرفتهای دست یابد. از مقاله بیشتر بیاموزید و کد را اینجا بگیرید.
سپاسگزاریها
این تحقیق توسط Antoine Yang، Arsha Nagrani، Paul Hongsuck Seo، Antoine Miech، Jordi Pont-Tuset، Ivan Laptev، Josef Sivic و Cordelia Schmid انجام شده است.