
شبکه های عصبی عمیق (DNN) برای حل طیف وسیعی از وظایف، از یادگیری نظارت شده استاندارد (طبقه بندی تصویر با استفاده از ViT) تا فرا یادگیری، ضروری شده اند. متداول ترین الگوی مورد استفاده برای یادگیری DNN ها است به حداقل رساندن ریسک تجربی (ERM)، که هدف آن شناسایی شبکه ای است که میانگین تلفات در نقاط داده آموزشی را به حداقل می رساند. چندین الگوریتم، از جمله نزول گرادیان تصادفی (SGD)، Adam و Adagrad، برای حل ERM پیشنهاد شدهاند. با این حال، یک اشکال ERM این است که تمام نمونهها را به یک اندازه وزن میکند، اغلب نمونههای کمیاب و دشوارتر را نادیده میگیرد و بر نمونههای سادهتر و فراوان تمرکز میکند. این منجر به عملکرد کمتر از حد مطلوب در دادههای دیده نشده میشود، به خصوص زمانی که دادههای آموزشی کمیاب هستند.
برای غلبه بر این چالش، کارهای اخیر تکنیک های وزن دهی مجدد داده ها را برای بهبود عملکرد ERM توسعه داده اند. با این حال، این رویکردها بر وظایف یادگیری خاص (مانند طبقه بندی) تمرکز می کنند و/یا نیاز به یادگیری یک مدل متا اضافی دارند که وزن هر نقطه داده را پیش بینی می کند. وجود یک مدل اضافی به طور قابل توجهی پیچیدگی آموزش را افزایش می دهد و آنها را در عمل غیرقابل تحمل می کند.
در “نزول گرادیان با وزن مجدد تصادفی از طریق بهینه سازی قوی توزیعی” ما یک نوع الگوریتم کلاسیک SGD را معرفی می کنیم که نقاط داده را در طول هر مرحله بهینه سازی بر اساس دشواری آنها وزن مجدد می کند. Stochastic Re-weighted Gradient Descent (RGD) یک الگوریتم سبک وزن است که با یک عبارت بسته ساده ارائه می شود و می تواند برای حل هر کار یادگیری تنها با استفاده از دو خط کد استفاده شود. در هر مرحله از فرآیند یادگیری، RGD به سادگی یک نقطه داده را به عنوان نمایی از دست دادن آن وزن می کند. ما به طور تجربی نشان میدهیم که الگوریتم وزندهی مجدد RGD عملکرد الگوریتمهای یادگیری متعدد را در وظایف مختلف، از یادگیری تحت نظارت گرفته تا فرا یادگیری، بهبود میبخشد. قابلتوجه، ما پیشرفتهایی را نسبت به روشهای پیشرفته در طبقهبندی DomainBed و Tabular نشان میدهیم. علاوه بر این، الگوریتم RGD همچنین عملکرد BERT را با استفاده از معیارهای GLUE و ViT در ImageNet-1K افزایش میدهد.
بهینه سازی قوی توزیعی
بهینهسازی قوی توزیعی (DRO) رویکردی است که فرض میکند یک تغییر توزیع داده در بدترین حالت ممکن است رخ دهد، که میتواند به عملکرد یک مدل آسیب برساند. اگر یک مدل بر شناسایی چند ویژگی جعلی برای پیشبینی تمرکز کرده باشد، این تغییرات توزیع داده در «بدترین حالت» میتواند منجر به طبقهبندی اشتباه نمونهها و در نتیجه کاهش عملکرد شود. DRO اتلاف نمونهها را در توزیع «بدترین حالت» بهینه میکند، و مدل را در برابر اختلالات قوی میکند (به عنوان مثال، حذف بخش کوچکی از نقاط از یک مجموعه داده، وزن جزئی به بالا/پایین نقاط داده، و غیره) در توزیع دادهها. . در چارچوب طبقهبندی، این مدل را مجبور میکند تا تأکید کمتری بر ویژگیهای نویزدار و تأکید بیشتر بر ویژگیهای مفید و پیشبینیکننده داشته باشد. در نتیجه، مدلهایی که با استفاده از DRO بهینه شدهاند، ضمانتهای تعمیم بهتر و عملکرد قویتری در نمونههای دیده نشده دارند.
با الهام از این نتایج، ما الگوریتم RGD را به عنوان تکنیکی برای حل هدف DRO توسعه میدهیم. به طور خاص، ما بر روی DRO مبتنی بر واگرایی Kullback-Leibler تمرکز میکنیم، جایی که فرد اغتشاشاتی را برای ایجاد توزیعهایی که نزدیک به توزیع داده اصلی در متریک واگرایی KL هستند، اضافه میکند و یک مدل را قادر میسازد تا در تمام اختلالات ممکن به خوبی عمل کند.
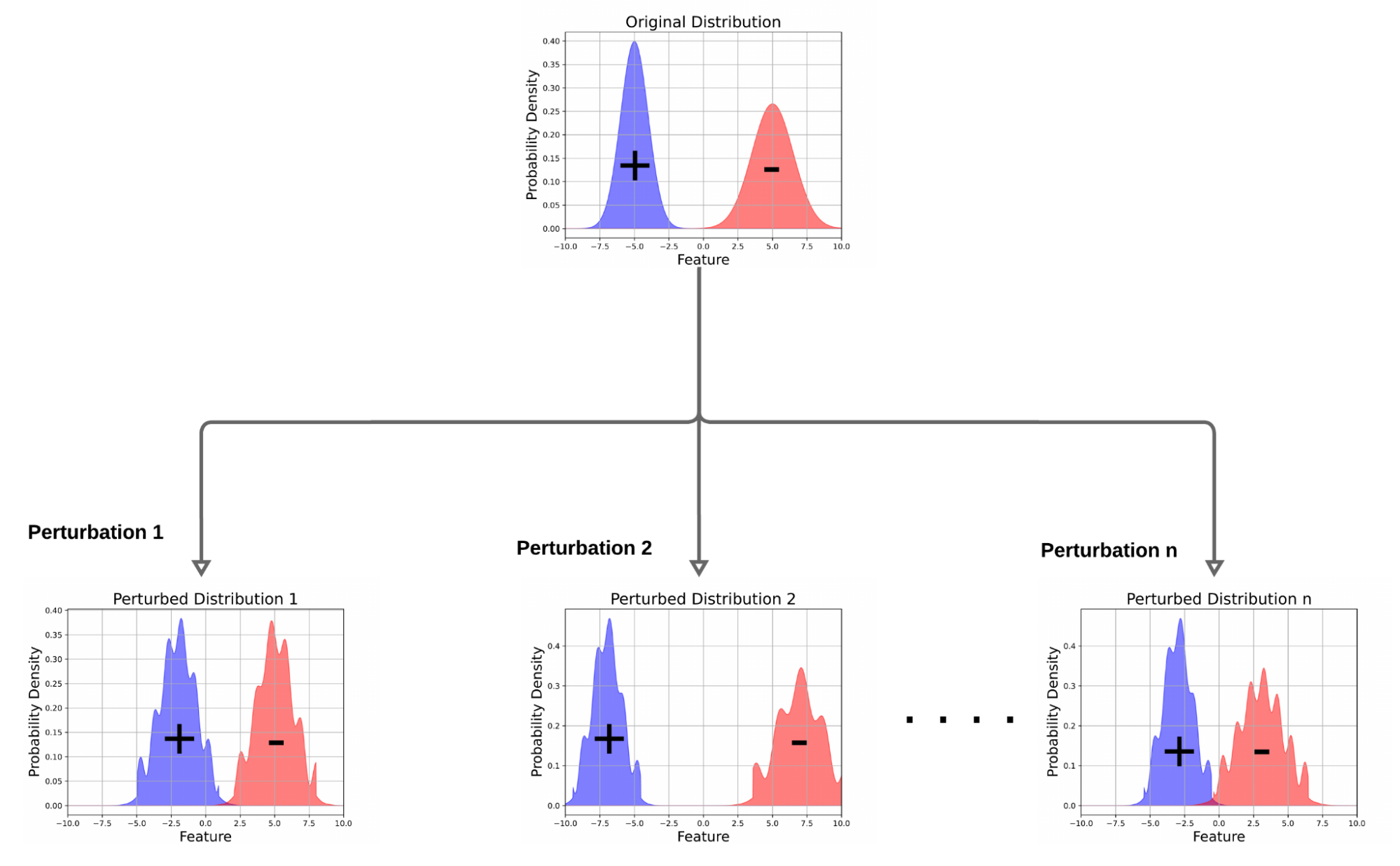 |
| شکل DRO را نشان می دهد. برخلاف ERM که مدلی را می آموزد که ضرر مورد انتظار را نسبت به توزیع داده اصلی به حداقل می رساند، DRO مدلی را می آموزد که در چندین نسخه آشفته توزیع داده اصلی به خوبی عمل می کند. |
نزول شیب وزنی مجدد تصادفی
یک زیرمجموعه تصادفی از نمونه ها را در نظر بگیرید (به نام یک دسته کوچک)، که در آن هر نقطه داده دارای یک تلفات مرتبط است. Lمن. الگوریتمهای سنتی مانند SGD به همه نمونهها در دسته کوچک اهمیت یکسانی میدهند و پارامترهای مدل را با نزول در امتداد گرادیانهای میانگین از دست دادن آن نمونهها بهروزرسانی میکنند. با RGD، هر نمونه را در مینی بچ دوباره وزن می کنیم و به نقاطی که مدل دشوارتر تشخیص می دهد اهمیت بیشتری می دهیم. به طور دقیق، از اتلاف به عنوان یک پروکسی برای محاسبه سختی یک نقطه استفاده می کنیم و آن را با نمایی از دست دادن آن دوباره وزن می کنیم. در نهایت، پارامترهای مدل را با نزول در امتداد میانگین وزنی گرادیان نمونه ها به روز می کنیم.
با توجه به ملاحظات پایداری، در آزمایشهای خود، افت را قبل از محاسبه نمایی آن، قطع و مقیاس میکنیم. به طور خاص، ما از دست دادن را در برخی از آستانه ها کاهش می دهیم تیو آن را با یک عدد اسکالر که با آستانه نسبت معکوس دارد ضرب کنید. یکی از جنبه های مهم RGD سادگی آن است زیرا برای محاسبه وزن نقاط داده به یک مدل متا تکیه نمی کند. علاوه بر این، می توان آن را با دو خط کد پیاده سازی کرد و با هر بهینه ساز محبوب (مانند SGD، Adam و Adagrad) ترکیب کرد.
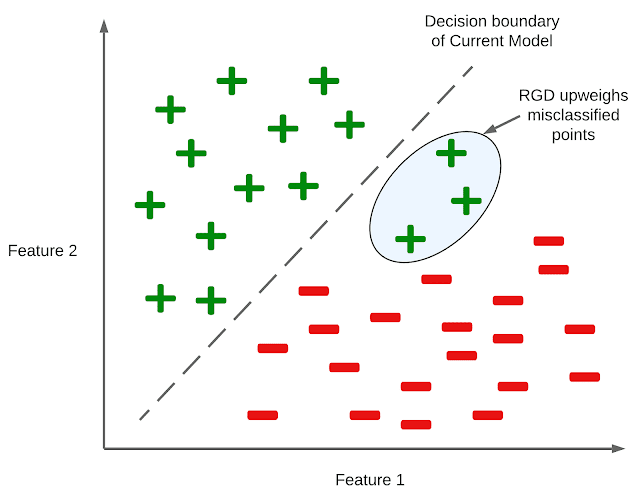 |
| شکلی که ایده بصری پشت RGD را در یک تنظیم طبقه بندی باینری نشان می دهد. ویژگی 1 و ویژگی 2 ویژگی هایی هستند که مدل برای پیش بینی برچسب نقطه داده در دسترس است. RGD نقاط داده را با تلفات بالا که توسط مدل به اشتباه طبقه بندی شده اند، افزایش می دهد. |
نتایج
ما نتایج تجربی مقایسه RGD را با تکنیکهای پیشرفته در یادگیری تحت نظارت استاندارد و انطباق دامنه ارائه میکنیم (برای نتایج مربوط به فرا یادگیری به مقاله مراجعه کنید). در تمام آزمایشهایمان، سطح برش و نرخ یادگیری بهینهساز را با استفاده از مجموعه اعتبارسنجی نگهداشتهشده تنظیم میکنیم.
یادگیری تحت نظارت
ما RGD را بر روی چندین وظیفه یادگیری تحت نظارت، از جمله زبان، بینایی، و طبقه بندی جدولی ارزیابی می کنیم. برای طبقهبندی زبان، ما RGD را به مدل BERT آموزشدیده در معیار ارزیابی درک عمومی زبان (GLUE) اعمال میکنیم و نشان میدهیم که RGD با انحراف استاندارد 0.42 درصد از خط پایه BERT 1.94% بهتر عمل میکند. برای ارزیابی عملکرد RGD در طبقهبندی بینایی، ما RGD را به مدل ViT-S آموزشدیده بر روی مجموعه داده ImageNet-1K اعمال میکنیم و نشان میدهیم که RGD با انحراف استاندارد 0.23% از خط پایه ViT-S 1.01% بهتر عمل میکند. علاوه بر این، آزمونهای فرضیه را برای تأیید اینکه این نتایج با مقدار p کمتر از 0.05 از نظر آماری معنیدار هستند، انجام میدهیم.
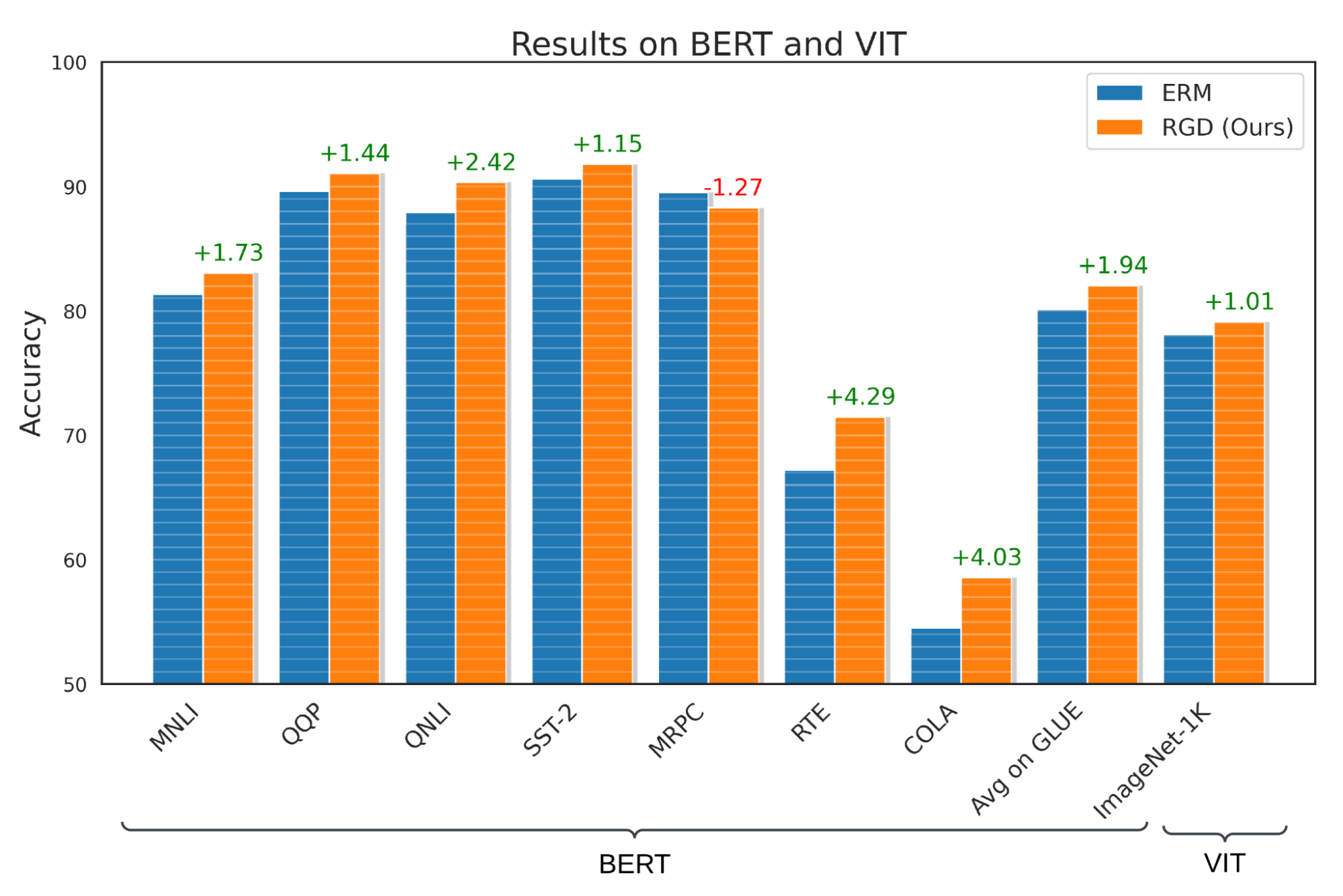 |
| عملکرد RGD در طبقه بندی زبان و بینایی با استفاده از معیارهای GLUE و Imagenet-1K. توجه داشته باشید که MNLI، QQP، QNLI، SST-2، MRPC، RTE و COLA مجموعه داده های متنوعی هستند که معیار GLUE را تشکیل می دهند. |
برای طبقه بندی جدولی، ما از MET به عنوان خط پایه خود استفاده می کنیم و مجموعه داده های باینری و چند کلاسه مختلف را از مخزن یادگیری ماشین UC Irvine در نظر می گیریم. ما نشان میدهیم که بکارگیری RGD در چارچوب MET عملکرد آن را به ترتیب در طبقهبندی جدولی باینری و چند کلاسه به ترتیب 1.51% و 1.27% بهبود میبخشد و به عملکرد پیشرفته در این حوزه دست مییابد.
 |
 |
| عملکرد RGD برای طبقه بندی مجموعه داده های جدولی مختلف. |
تعمیم دامنه
برای ارزیابی قابلیتهای تعمیم RGD، از معیار استاندارد DomainBed استفاده میکنیم که معمولاً برای مطالعه عملکرد خارج از دامنه یک مدل استفاده میشود. ما RGD را به FRR اعمال میکنیم، رویکرد اخیری که معیارهای خارج از دامنه را بهبود میبخشد، و نشان میدهد که RGD با FRR به طور متوسط 0.7٪ بهتر از خط پایه FRR عمل میکند. علاوه بر این، با آزمونهای فرضیه تأیید میکنیم که اکثر نتایج معیار (به جز Office Home) با مقدار p کمتر از 0.05 از نظر آماری معنیدار هستند.
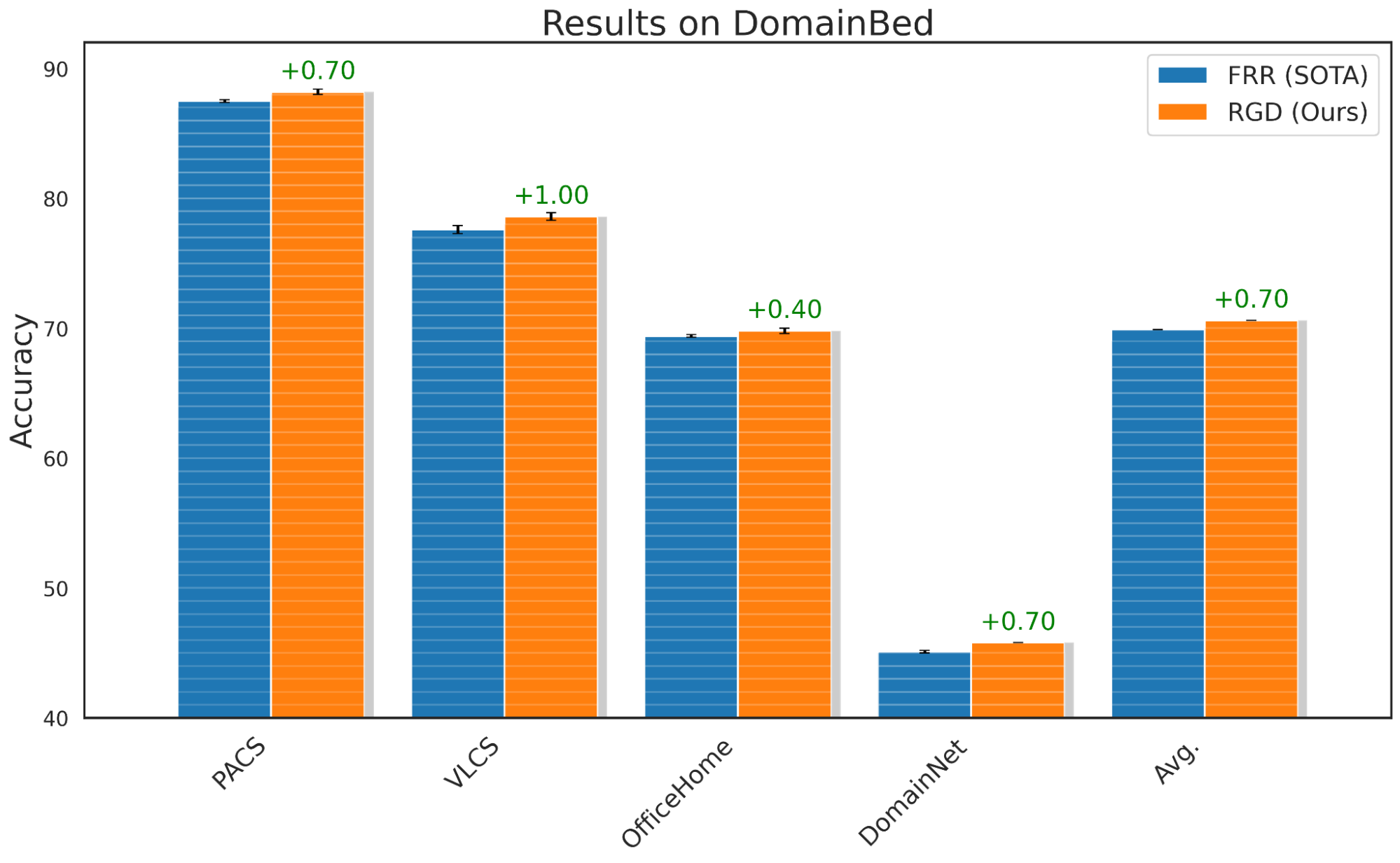 |
| عملکرد RGD در معیار DomainBed برای تغییرات توزیعی. |
عدم تعادل و انصاف طبقاتی
برای نشان دادن اینکه مدلهایی که با استفاده از RGD آموختهاند، علیرغم عدم تعادل کلاس، عملکرد خوبی دارند، جایی که کلاسهای خاصی در مجموعه دادهها کمتر ارائه میشوند، عملکرد RGD را با ERM در CIFAR-10 با دم بلند مقایسه میکنیم. ما گزارش می دهیم که RGD دقت ERM پایه را به طور متوسط 2.55٪ با انحراف استاندارد 0.23٪ بهبود می بخشد. علاوه بر این، آزمونهای فرضیه را انجام میدهیم و تأیید میکنیم که این نتایج از نظر آماری با مقدار p کمتر از 0.05 معنیدار هستند.
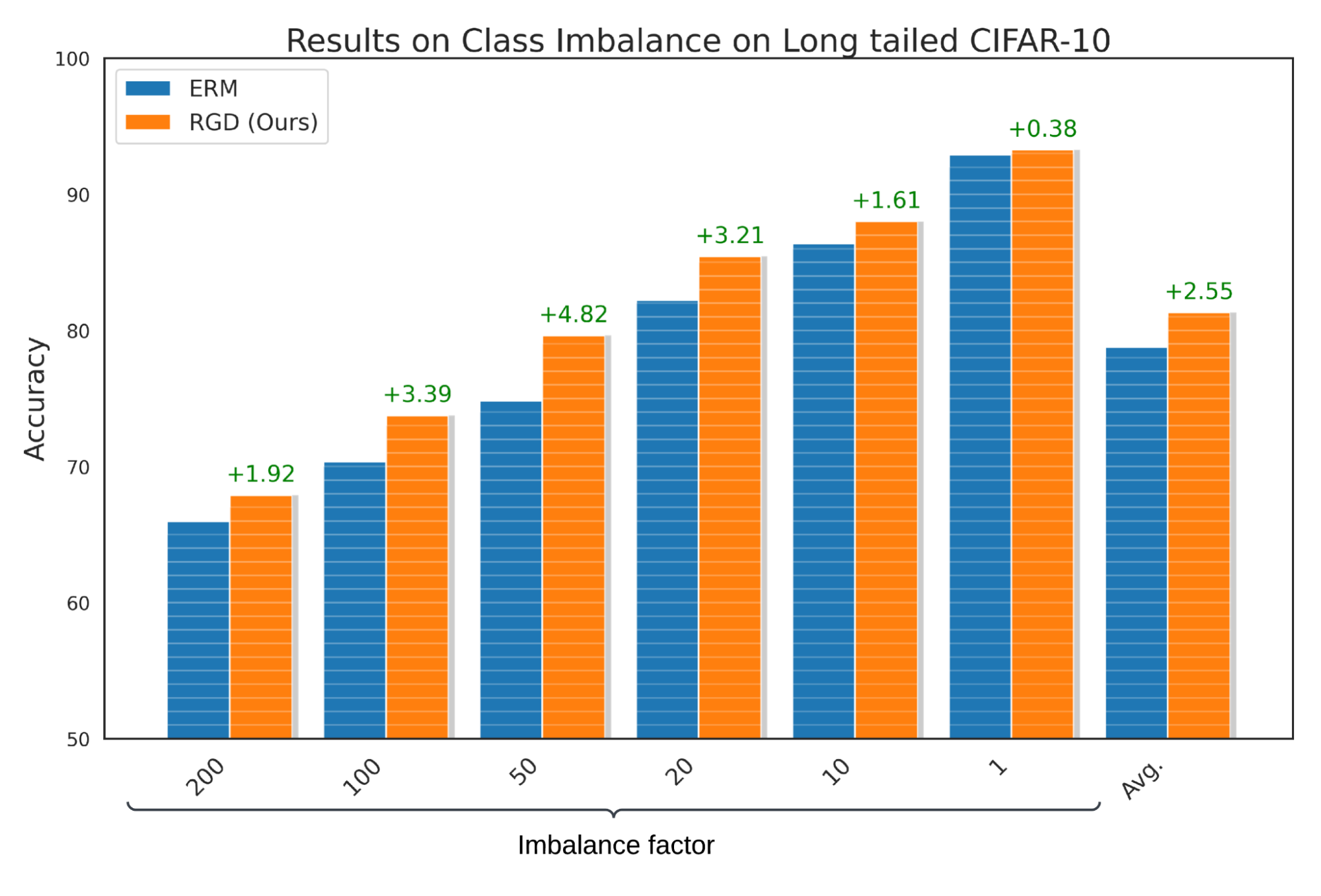 |
| عملکرد RGD در معیار دم بلند Cifar-10 برای دامنه عدم تعادل کلاس. |
محدودیت ها
الگوریتم RGD با استفاده از مجموعه دادههای تحقیقاتی محبوب، که قبلاً برای حذف خرابیها (مثلاً نویز و برچسبهای نادرست) تنظیم شده بودند، توسعه داده شد. بنابراین، RGD ممکن است در سناریوهایی که دادههای آموزشی دارای حجم بالایی از فساد هستند، بهبود عملکرد را ارائه نکند. یک رویکرد بالقوه برای رسیدگی به چنین سناریوهایی استفاده از یک تکنیک حذف پرت در الگوریتم RGD است. این روش حذف نقاط پرت باید بتواند نقاط پرت را از دسته کوچک فیلتر کرده و نقاط باقیمانده را به الگوریتم ما ارسال کند.
نتیجه
نشان داده شده است که RGD در انواع وظایف، از جمله تعمیم خارج از دامنه، یادگیری نمایش جدولی و عدم تعادل کلاس موثر است. پیاده سازی آن ساده است و می تواند به طور یکپارچه در الگوریتم های موجود تنها با دو خط تغییر کد ادغام شود. به طور کلی، RGD یک تکنیک امیدوارکننده برای افزایش عملکرد DNN ها است و می تواند به افزایش مرزها در حوزه های مختلف کمک کند.
سپاسگزاریها
مقاله توصیف شده در این پست وبلاگ توسط رامنات کومار، آرون سای سوگالا، دیرج ناگاراج و کوشال ماجموندار نوشته شده است. ما صمیمانه از بازبینان ناشناس، Prateek Jain، Pradeep Shenoy، Anshul Nasery، Lovish Madaan، و اعضای متعهد متعدد تیم یادگیری ماشین و بهینهسازی در Google Research India برای بازخورد و مشارکت ارزشمندشان در این کار، صمیمانه تشکر میکنیم.