یادگیری گروهی یک تکنیک یادگیری تحت نظارت است که در یادگیری ماشین برای بهبود عملکرد کلی با ترکیب پیشبینیهای چند مدل استفاده میشود.
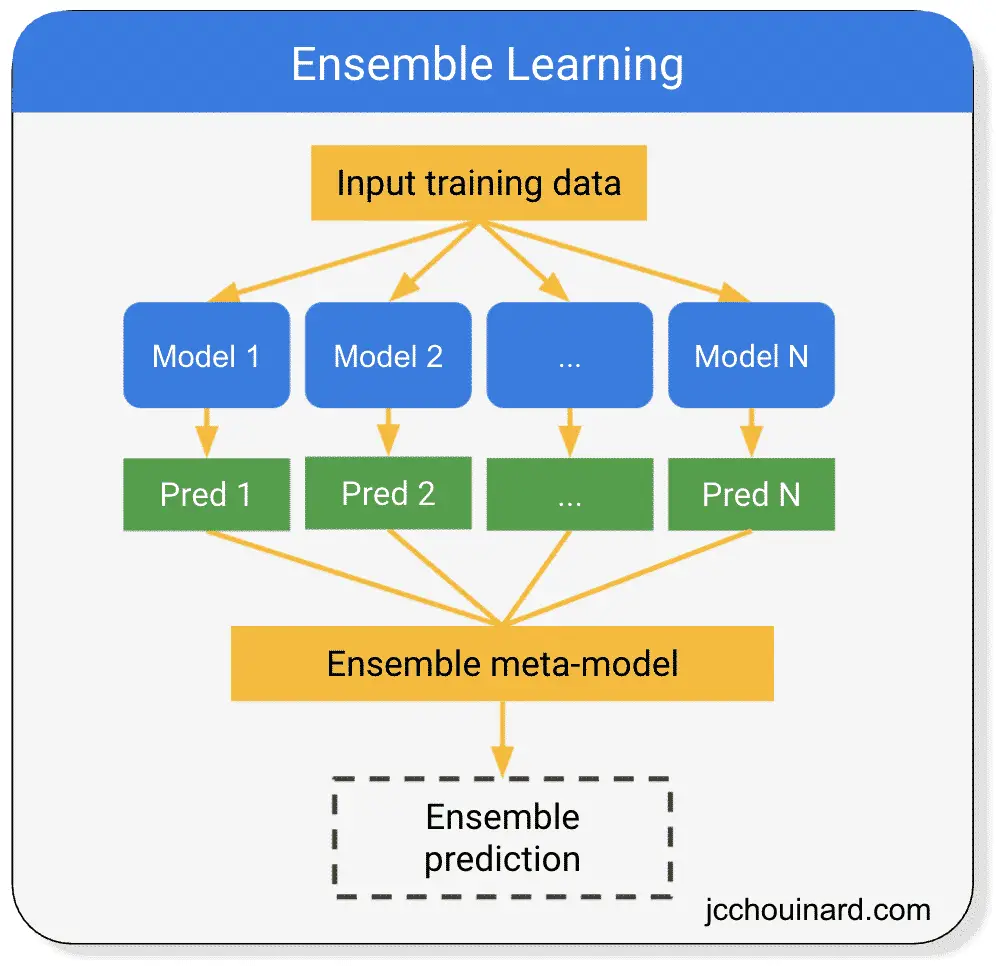
هر مدل می تواند یک طبقه بندی متفاوت باشد:
آموزش گروهی چگونه کار می کند؟
یادگیری گروهی بر اساس اصل “عقل جمعیت” کار می کند. با ترکیب چندین مدل، میتوانیم دقت پیشبینیها را بهبود ببخشیم.

انواع روش های گروه
- رای دادن
- تجمع بوت استرپ (بگینگ)
- جنگل های تصادفی
- افزایش
- تعمیم انباشته (ترکیب)
رای دادن
رای دادن یک الگوریتم یادگیری ماشین مجموعه ای است که شامل پیش بینی است که میانگین (رگرسیون) یا مجموع (طبقه بندی) چندین مدل یادگیری ماشین است.

- همان مجموعه های آموزشی
- الگوریتم های مختلف
sklearn.ensemble:VotingRegressor،VotingClassifier
نمونه ای از طبقه بندی کننده رأی در پایتون (Sklearn)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create individual classifiers
logistic_classifier = LogisticRegression(random_state=42)
tree_classifier = DecisionTreeClassifier(random_state=42)
svm_classifier = SVC(random_state=42)
# Create a VotingClassifier with majority rule
voting_classifier = VotingClassifier(
estimators=[
('logistic', logistic_classifier),
('tree', tree_classifier),
('svm', svm_classifier)],
voting='hard' # 'hard' for majority vote, 'soft' for weighted vote
)
# Fit the ensemble classifier to the training data
voting_classifier.fit(X_train, y_train)
# Make predictions on the test data
y_pred = voting_classifier.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
Bootstrap Aggregation (Bagging)
کوله بری، یا تجمع بوت استرپ، یک روش مجموعه ای است که واریانس مدل های فردی را با برازش درخت تصمیم بر روی نمونه های مختلف بوت استرپ یک مجموعه آموزشی کاهش می دهد.

- مجموعه های آموزشی مختلف
- همان الگوریتم
- دو مدل از
sklearn.ensemble:BaggingClassifier،BaggingRegressor
نمونه ای از دسته بندی کننده Bagging در پایتون (Sklearn)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a base classifier (Decision Tree)
base_classifier = DecisionTreeClassifier(random_state=42)
# Create a BaggingClassifier
bagging_classifier = BaggingClassifier(
base_estimator=base_classifier, # Base classifier to be used
n_estimators=10, # Number of base classifiers (decision trees)
random_state=42,
)
# Fit the bagging classifier to the training data
bagging_classifier.fit(X_train, y_train)
# Make predictions on the test data
y_pred = bagging_classifier.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
جنگل های تصادفی
جنگلهای تصادفی از درختهای تصمیم بهعنوان تخمینگر پایه برای پیشبینیها استفاده میکنند و با محاسبه رای اکثریت / میانگین پیشبینی درختهای تصمیم چندگانه، عملکرد مدلها را بهبود میبخشند.
جنگل تصادفی هم یک الگوریتم یادگیری نظارت شده و هم یک الگوریتم گروهی است.

- برآوردگر پایه یک درخت تصمیم است
- هر برآوردگر از نمونه بوت استرپ متفاوتی از مجموعه آموزشی استفاده می کند
- دو مدل از
sklearn.ensemble:RandomForestClassifier،RandomForestRegressor
نمونه ای از جنگل های تصادفی در پایتون (Sklearn)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a Random Forest Classifier
random_forest = RandomForestClassifier(n_estimators=100, random_state=42)
# Fit the model to the training data
random_forest.fit(X_train, y_train)
# Make predictions on the test data
y_pred = random_forest.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
افزایش
افزایش یک روش مجموعهای است که زبانآموزان ضعیف را به زبانآموزان قوی تبدیل میکند و هر پیشبینیکننده خطاهای پیشین خود را برطرف میکند.
تقویت را می توان در مسائل طبقه بندی و رگرسیون استفاده کرد.
تقویت الگوریتمهای یادگیری ماشینی توسط:
- نمونه سازی یک یادگیرنده ضعیف (مثلاً سبد خرید با
max_depthاز 1) - انجام یک پیش بینی و انتقال پیش بینی های اشتباه به پیش بینی کننده بعدی
- توجه بیشتر و بیشتر در هر تکرار به مشاهدات. داشتن خطاهای پیش بینی
- پیش بینی جدید تا رسیدن به حد مجاز یا دستیابی به دقت بالاتر.

الگوریتم های تقویت کننده چندگانه
- تقویت گرادیان: ماشین های تقویت گرادیان، درختان رگرسیون تقویت شده گرادیان
- آدابوست
- XGBoost
مثالی از تقویت با Adaboost در پایتون (Sklearn)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a base classifier (e.g., Decision Tree)
base_classifier = DecisionTreeClassifier(max_depth=1)
# Create an AdaBoost Classifier
adaboost_classifier = AdaBoostClassifier(
base_estimator=base_classifier,
n_estimators=50, # Number of weak learners (you can adjust this)
random_state=42
)
# Fit the model to the training data
adaboost_classifier.fit(X_train, y_train)
# Make predictions on the test data
y_pred = adaboost_classifier.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
تعمیم انباشته (ترکیب)
پشتهسازی، همچنین به عنوان شناخته شده است تعمیم انباشته، یک تکنیک مجموعه ای است که دقت مدل ها را با ترکیب پیش بینی های طبقه بندی چندگانه یا مدل های یادگیری ماشین رگرسیون بهبود می بخشد.
انباشته کردن الگوریتمهای یادگیری ماشینی بر اساس:
- استفاده از چندین مدل سطح اول برای پیش بینی در یک مجموعه آموزشی
- ترکیب (انباشته کردن) پیش بینی ها برای ایجاد یک مجموعه آموزشی جدید
- برازش و پیشبینی مدل سطح دوم بر روی مجموعه آموزشی تولید شده

- از جانب
sklearn.ensemble:StackingClassifier
مثالی از ترکیب در پایتون (Sklearn)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, StackingClassifier
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create individual classifiers
estimators = [
('logistic', LogisticRegression(random_state=42)),
('tree', DecisionTreeClassifier(random_state=42)),
('rf', RandomForestClassifier(random_state=42))
]
# Create the StackingClassifier
stacking_classifier = StackingClassifier(
estimators=estimators,
final_estimator=LogisticRegression() # You can choose any final estimator
)
# Fit the StackingClassifier to the training data
stacking_classifier.fit(X_train, y_train)
# Make predictions on the test data
y_pred = stacking_classifier.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Stacking Classifier Accuracy: {accuracy * 100:.2f}%")
منابع جالب از جامعه
نتیجه
این به معرفی الگوریتمهای یادگیری ماشین گروهی پایان میدهد. ما نحوه عملکرد یادگیری گروهی را پوشش دادهایم و مروری بر رایجترین مدلهای یادگیری ماشین ارائه کردهایم.
گام بعدی یادگیری نحوه استفاده از Scikit-learn برای آموزش هر مجموعه مدلهای یادگیری ماشین بر روی دادههای واقعی است.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.