لینکدین داده های زیادی برای ارائه دارد. با این حال، برای داشتن این داده ها، یا باید آن را به صورت دستی استخراج کنید یا آن را خراش دهید.
انجام دستی خوب است، اما مستعد خطا، خسته کننده و مقیاس پذیر نیست. در این آموزش، ما از پایتون استفاده می کنیم و کارهای لینکدین را با استفاده از آن خراش می دهیم.
علاوه بر این، در این آموزش، توضیح خواهم داد که چگونه می توانید این روش را مقیاس بندی کنید، با دور زدن محدودیت های خراش دادن کارهای لینکدین با استفاده از پایتون. و بعداً، این داده ها را برای اهداف تجزیه و تحلیل در یک فایل CSV ذخیره می کنیم.
برای این آموزش، از LinkedIn Job Scraping API استفاده می کنیم که به ما کمک می کند تا داده های شغلی را از لینکدین بدون مسدود شدن خراش دهیم.
پایتون را نصب کنید و کتابخانه ها را دانلود کنید
ما از Python 3.x برای این آموزش استفاده خواهیم کرد. می توانید پایتون را نصب کنید یا از Google Colab استفاده کنید. نحوه نصب پایتون را ببینید. پس از این یک پوشه ایجاد کنید که اسکریپت های پایتون را در آن نگه دارید. من این پوشه را به عنوان نام گذاری می کنم jobs. در نوع ترمینال:
$ mkdir jobsسپس کتابخانه های زیر را دانلود کنید.
- درخواست ها: این برای ایجاد یک اتصال HTTP با LinkedIn Jobs Scraping API استفاده می شود.
- Pandas: برای تبدیل داده های JSON به فایل CSV استفاده می شود.
در نهایت، شما باید برای بسته رایگان Scrapingdog ثبت نام کنید. با بسته رایگان، 1000 اعتبار دریافت می کنید که برای اهداف آزمایشی کافی است. این آموزش، کمتر از 40 واحد خواهد داشت.
درک درخواست ها به لینکدین API
قبل از شروع خراش دادن مشاغل، ابتدا به مستندات نگاه می کنیم. ما می توانیم ببینیم که چهار وجود دارد ضروری پارامترهایی که باید هنگام درخواست GET ارسال شوند.
نحوه خراش دادن مشاغل لینکدین با پایتون
برای خراش دادن مشاغل لینکدین با پایتون، به یک کلید API سرویس پروکسی، یک geoid Linkedin و یک جستجوی شغلی برای پر کردن نوار جستجوی LinkedIn نیاز دارید.
برای این آموزش، ما می خواهیم کارهای ارائه شده توسط را خراش دهیم گوگل در ایالات متحده آمریکا، با استفاده از سرویس پروکسی Scraping Dog.
چگونه شناسه جغرافیایی مشاغل LinkedIn را پیدا کنیم
برای پیدا کردن GeoId در مشاغل LinkedIn، صفحه جستجوی مشاغل LinkedIn را باز کنید و پارامتر geoid داخل URL را بررسی کنید.

همانطور که می بینید geoId ایالات متحده آمریکا است 103644278. ژئوئید برای کانادا است 101174742.
خراش دادن اولین صفحه شغلی لینکدین شما
برای خراش دادن اولین صفحه مشاغل لینکدین خود، نقطه پایانی API را تعریف کنید و یک فرهنگ لغت پارامتری ایجاد کنید که حاوی کلید API، عبارت جستجوی شغل، geoid LinkedIn و شماره صفحه از نتایج صفحهبندی شده است. سپس، از درخواستهای پایتون برای واکشی API Scraping Dogs استفاده کنید.
import requests
# Define Scraping Dog API Key
api_key = 'you-API-key'
# Define the URL and parameters
url = "https://api.scrapingdog.com/linkedinjobs/"
geo_id = '101174742' #Canada. US: "103644278"
params = {
"api_key": api_key,
"field": "Google",
"geoid": geo_id,
"page": "1"
}
# Send a GET request with the parameters
response = requests.get(url, params=params)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Access the response content
google_jobs = response.json()
print(google_jobs)
else:
print("Request failed with status code:", response.status_code)
این کد همه مشاغل ارائه شده توسط Google در ایالات متحده را برمی گرداند. پس از اجرای این کد، این پاسخ را در کنسول خود خواهید یافت.
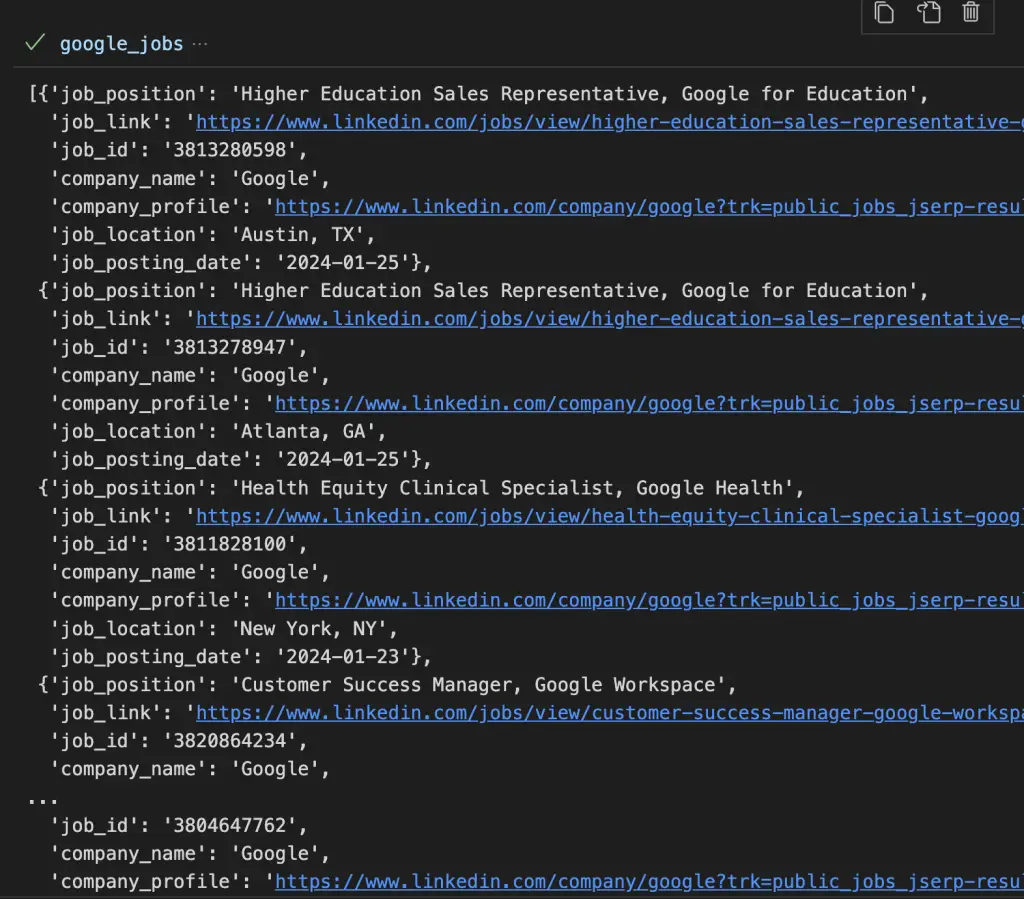
پاسخ API شامل فیلدهای زیر است:
- موقعیت شغلی،
- job_link،
- شناسه کار،
- نام شرکت،
- نمایه شرکت،
- محل کار
- job_posting_date.
واکشی یک عنوان شغلی خاص در LinkedId
لازم نیست همیشه نام شرکت را پاس کنید. شما حتی می توانید عنوان شغلی را به عنوان مقدار ارسال کنید رشته پارامتر.
import requests
api_key = 'you-API-key'
url = "https://api.scrapingdog.com/linkedinjobs/"
geo_id = '101174742'
params = {
"api_key": api_key,
"field": "Product Manager", # job title here
"geoid": geo_id,
"page": "1"
}
# Send a GET request with the parameters
response = requests.get(url, params=params)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Access the response content
pm_jobs = response.json()
print(pm_jobs)
else:
print("Request failed with status code:", response.status_code)
برای هر شماره صفحه، حداکثر عدد را دریافت خواهید کرد 25 شغل. حال، سوال این است که چگونه می توان این راه حل را برای جمع آوری تمام مشاغل از API مقیاس کرد.
چگونه مشاغل لینکدین را در مقیاس استخراج کنیم
برای استخراج تمام مشاغل در Linkedin در مقیاس برای یک شناسه جغرافیایی و عبارت جستجوی خاص، یک بی نهایت اجرا خواهیم کرد. while حلقه در این مثال، با دنبال کردن این مراحل، تمام مشاغل مربوط به مشاغل Google در ایالات متحده آمریکا را که در مشاغل Linkedin یافت می شوند استخراج می کنیم:
- یک تابع برای ذخیره داده های LinkedIn ایجاد کنید
- یک حلقه while بی نهایت برای خراش دادن هر صفحه جستجو ایجاد کنید
- داده های لینکدین را استخراج و ذخیره کنید
1. یک تابع برای ذخیره داده های لینکدین ایجاد کنید
اولین قدم ایجاد تابعی است که داده ها را ذخیره می کند. بنابراین، اگر چیزی خراب شود، شما همچنان دادههای ذخیره شده برای هر حلقه را خواهید داشت.
این یک Pandas DataFrame از دادههایی که برمیگردانیم ایجاد میکند. اگر فایلی از قبل وجود داشته باشد، آن را می خواند و داده ها را به فایل موجود اضافه می کند. اگر نه، یک مورد جدید ایجاد می کند.
import pandas as pd
import requests
import sys
def process_json_data(data, csv_filename="linkedin_jobs.csv"):
# Convert the list of dictionaries to a Pandas DataFrame
df = pd.DataFrame(data)
try:
# Try to read an existing CSV file
existing_df = pd.read_csv(csv_filename)
# Append the new data to the existing DataFrame
updated_df = pd.concat([existing_df, df], ignore_index=True)
# Save the updated DataFrame back to the CSV file
updated_df.to_csv(csv_filename, index=False)
print(f"Data appended to {csv_filename}")
except FileNotFoundError:
# If the CSV file does not exist, create a new one
df.to_csv(csv_filename, index=False)
print(f"Data saved to a new CSV file: {csv_filename}")
return df
2. یک حلقه while بی نهایت برای خراش دادن هر صفحه جستجو ایجاد کنید
اکنون یک حلقه while بی نهایت برای خراش دادن هر صفحه جستجو ایجاد می کنیم. این حلقه while اجرا می شود تا زمانی که طول آرایه داده به صفر برسد. از آنجا که ما نمی خواهیم تمام اعتبارات API شما را برای این آموزش خرج کنیم، من آن را اضافه می کنم sys.exit() خط تا انتها، پس از اولین حلقه متوقف شود. آن خط را بردارید تا تمام کارهای لینکدین را پاک کنید.
import sys
while True:
# We will add Python code here
# Stop after first loop,
sys.exit() # remove to fetch everything
3. داده های لینکدین را استخراج و ذخیره کنید
برای استخراج و ذخیره داده های LinkedIn، درخواست API و یک تابع ذخیره سازی Python را در داخل آن اضافه کنید while حلقه
import pandas as pd
import requests
import sys
# Example usage inside your loop
page = 0
full_list = []
while True:
l = []
page += 1
url = "https://api.scrapingdog.com/linkedinjobs/"
params = {
"api_key": api_key,
"field": "SEO",
"geoid": geo_id,
"page": str(page)
}
print('Running page:', page)
# Send a GET request with the parameters
response = requests.get(url, params=params)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Access the response content
data = response.json()
for item in data:
l.append(item)
if len(data) == 0:
break
# Store data to CSV
df = process_json_data(l)
full_list.extend(l)
else:
print("Request failed with status code:", response.status_code)
if page == 2:
sys.exit() # Comment out to run the entire loop
full_df = pd.DataFrame(full_list)
این کد تا زمانی که طول داده ها صفر شود به کار خود ادامه می دهد. دستور break حلقه while بی نهایت را متوقف می کند.
- در هر تکرار، API را برای یک صفحه جدید با 25 نتیجه واکشی می کند، تا زمانی که تمام صفحه خراشیده شود.
- پس از هر حلقه، یک Pandas DataFrame ایجاد می کند و داده ها را در یک فایل CSV ذخیره می کند. به این ترتیب هیچ پیشرفتی از بین نمی رود.
- یک لیست وجود دارد (
l) برای هر حلقه و یک لیست کامل (full_list) برای ذخیره تمام داده ها.
مزایای Scraping Jobs LinkedIn
مزایای حذف لیست های شغلی لینکدین این است که به توسعه دهندگان کمک می کند تا تابلوهای شغلی کارآمدتر و هدفمندتری ایجاد کنند که نیازهای خاص صنایع مختلف و جویندگان کار را برآورده کند. مجموعه دادههای شغلی نه تنها تجربه جستجوی شغل را برای افراد افزایش میدهد، بلکه به شرکتها پلتفرم ظریفتری برای یافتن استعدادهای مناسب ارائه میدهد.
مقیاس گذاری این عملیات از طریق یک API، ابزار پروژه خراش اولیه شما را گسترش می دهد و به شما امکان می دهد حجم بیشتری از داده ها را با کارایی بیشتر مدیریت کنید.
این مقیاس پذیری برای ایجاد یک هیئت شغلی جامع که در بازار کار همیشه در حال تحول در لینکدین جاری باشد، بسیار مهم است. یک رویکرد مبتنی بر API امکان بهروزرسانیهای بلادرنگ و ادغام با سایر ابزارهای نرمافزاری را فراهم میکند و هیئت مدیره کار شما را پویاتر میکند و به نیازهای جویندگان کار و کارفرمایان پاسخگوتر است.
در این وبلاگ، ما یاد گرفتیم که چگونه می توانید مشاغل LinkedIn را در مقیاس با استفاده از پایتون خراش دهید.
امیدوارم از آموزش خوشتون اومده باشه، به زودی آموزش های لینکدین بیشتری می نویسم.
خراشیدن مبارک!

Manthan Koolwal یک کهنه کار خراش دادن وب به مدت 8 سال است و خطوط لوله داده را برای شرکت های بزرگ ساخته است. بنیانگذار Scrapingdog، سرمایه گذاری SaaS خود، او پیشگام راه حل های ساده در این زمینه است.