در این راهنما یکی از آمارهای خلاصه را معرفی می کنیم: اندازه گیری های متغیر. ما همچنین نمونههایی از پایتون را برای نشان دادن نحوه اعمال این مفهوم در اختیار شما قرار میدهیم.
معیارهای تغییرپذیری (گسترش) در آمار چیست؟
معیارهای تغییرپذیری که به عنوان معیارهای گسترش نیز شناخته می شوند، هستند. آمار خلاصه ای که برای درک تغییرپذیری داده ها استفاده می شود که چقدر نقاط داده به هم نزدیک یا پراکنده هستند).
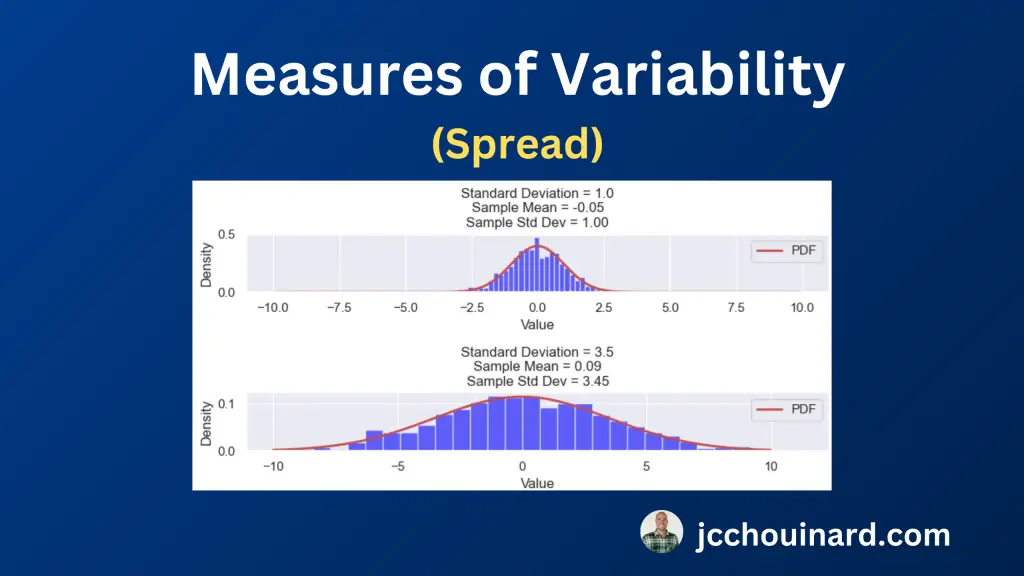
8 معیار تغییرپذیری در آمار خلاصه عبارتند از: دامنه، محدوده بین چارکی (IQR)، واریانس، انحراف معیار، ضریب تغییرات (CV)، میانگین انحراف مطلق، مربع میانگین ریشه (RMS) و محدوده صدک. .
- دامنه: تفاوت بین مقادیر حداکثر و حداقل در یک مجموعه داده
- محدوده بین چارکی (IQR): تفاوت بین چارک سوم و اول (Q3 و Q1). تمرکز بر 50 درصد میانی برای کاهش تأثیر عوامل پرت.
- واریانس: میانگین فاصله هر نقطه داده از میانگین
- انحراف معیار: ریشه مربع واریانس
- ضریب تغییرات (CV): نسبت درصد انحراف معیار به میانگین
- میانگین انحراف مطلق: میانگین اختلاف مطلق بین نقاط داده و میانگین
- ریشه میانگین مربع (RMS): جذر میانگین مقادیر مجذور.
- محدوده صدک: محدوده بین صدک های خاص برای ارائه بینش به مرکز داده ها کمتر تحت تاثیر مقادیر شدید.
مروری بر معیارهای تغییرپذیری در پایتون
| نام | شرح | چه موقع باید استفاده کرد | تابع پایتون |
|---|---|---|---|
| دامنه | تفاوت بین حداکثر و حداقل | بررسی اجمالی سریع گسترش | max(data) - min(data) |
| محدوده بین چارکی (IQR) | محدوده داده های متوسط 50٪. | مقاوم در برابر موارد پرت. | np.quantile(data, 0.75) - np.quantile(data, 0.25) |
| واریانس | میانگین مجذور انحرافات | نسبت به موارد دورافتاده حساس است. | np.var(data) |
| انحراف معیار | جذر واریانس | قابل تفسیر، در واحدهای مشابه. | np.std(data) |
| ضریب تغییرات (CV) | انحراف معیار نسبت به میانگین. | مقایسه مجموعه داده ها با مقیاس های مختلف | (np.std(data) / np.mean(data)) * 100 |
| میانگین انحراف مطلق (MAD) | میانگین انحرافات مطلق | مقاوم در برابر موارد پرت. | np.mean(np.abs(data - np.mean(data))) |
| ریشه میانگین مربع (RMS) | جذر میانگین مقادیر مجذور. | در پردازش سیگنال استفاده می شود. | np.sqrt(np.mean(np.square(data))) |
| محدوده های صدک | محدوده بین صدک های خاص. | محدوده داده مرکزی را برجسته کنید. | numpy.percentile(data, q) - numpy.percentile(data, p) |
محدوده در آمار چیست؟
محدوده در آمار نشان دهنده تفاوت بین حداکثر و حداقل مقادیر یک مجموعه داده است.
نحوه محاسبه محدوده
محدوده با کم کردن مقدار حداقل از مقدار حداکثر محاسبه می شود.
range = max - minنحوه محاسبه محدوده در پایتون
برای محاسبه محدوده مقادیر در پایتون، از max() و min() تابع. توجه داشته باشید که range() تابع برای ایجاد محدوده استفاده می شود نه برای محاسبه آن.
values = range(1, 10) # create range
rg = max(values) - min(values) # calculate range
print('Values:', list(values))
print('Range:', rg)
Values: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Range: 8 محدوده بین ربعی (IQR) در آمار چیست؟
محدوده بین چارکی یا IQR در آمار خلاصه نشان دهنده تفاوت بین چارک سوم (Q3) و چارک اول (Q1) است. با تمرکز بر 50 درصد میانی داده ها، محدوده های بین ربعی امکان تحلیلی را فراهم می کند که کمتر تحت تأثیر مقادیر شدید قرار می گیرد.
به بیان ساده، محدوده بین چارکی، ارتفاع جعبه در یک باکس پلات است.

برای درک IQR باید مفهوم چندک را معرفی کنیم.
چندک (درصد) در آمار چیست؟
چندک ها که به آن صدک نیز می گویند، زمانی رخ می دهد که داده ها را به قسمت های مساوی تقسیم کنیم. به عنوان مثال، وقتی چندک ها را به 4 قسمت مساوی تقسیم می کنیم، آن ها را صدا می کنیم یک چهارم.
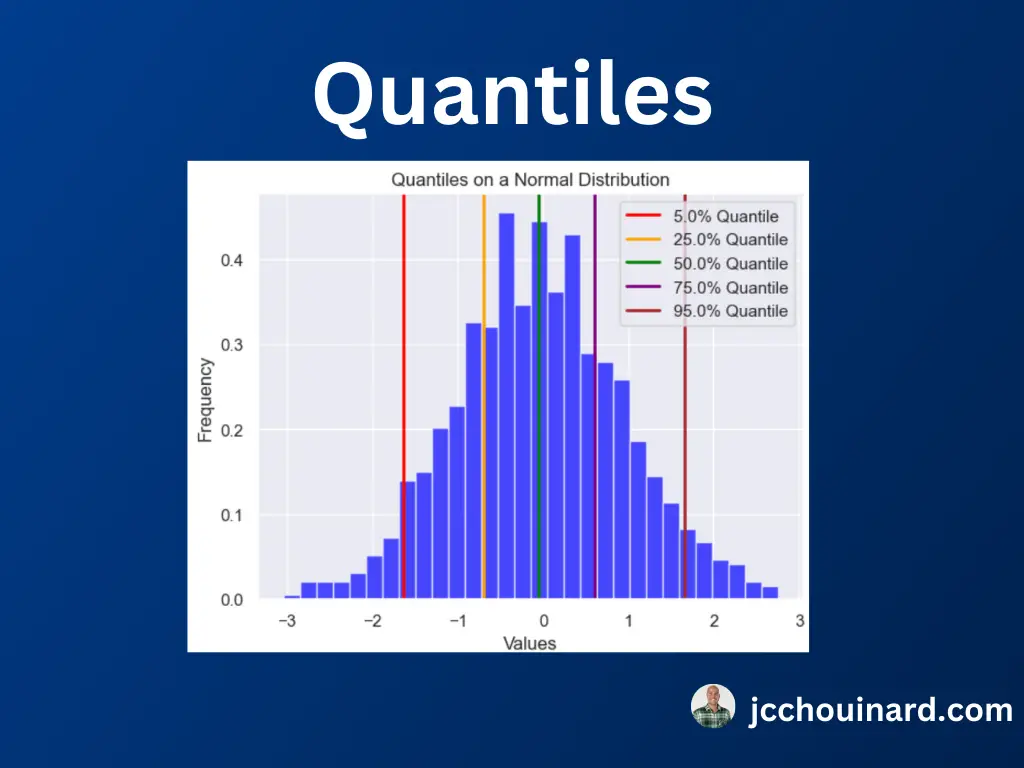
ما می توانیم استفاده کنیم np.quantile() عملکردی در پایتون برای تقسیم داده ها به قسمت های مساوی.
import numpy as np
# Example numerical dataset
data = np.array(range(1,10))
# Calculate the median (50th percentile)
median = np.quantile(data, 0.5)
print("Median (50th percentile):", median)
np.median(data) == np.quantile(data, 0.5)
Median (50th percentile): 5.0
Trueمیتوانید ببینید که چگونه در کد بالا، چندکها به 50% تقسیم میشوند، مانند محاسبه مقدار میانه.
همچنین می توانید صدک های 25، 75 و 90 مجموعه داده خود را محاسبه کنید.
# Calculate the 25th percentile (1st quartile)
q1 = np.quantile(data, 0.25)
print("25th Percentile (1st Quartile):", q1)
# Calculate the 75th percentile (3rd quartile)
q3 = np.quantile(data, 0.75)
print("75th Percentile (3rd Quartile):", q3)
# Calculate a custom quantile (e.g., the 90th percentile)
custom_quantile = np.quantile(data, 0.9)
print("90th Percentile (Custom Quantile):", custom_quantile)
# Calculate all quartiles at once
quartiles = np.quantile(data, [0,0.25,0.5,0.75,1])
print("Quartiles:", quartiles)
25th Percentile (1st Quartile): 3.0
75th Percentile (3rd Quartile): 7.0
90th Percentile (Custom Quantile): 8.2
Quartiles: [1. 3. 5. 7. 9.]Quantile ها را با یک Box Plot در پایتون تجسم کنید
بهترین راه برای تجسم چندک ها در پایتون، ایجاد یک نمودار جعبه ای از داده های خود است.
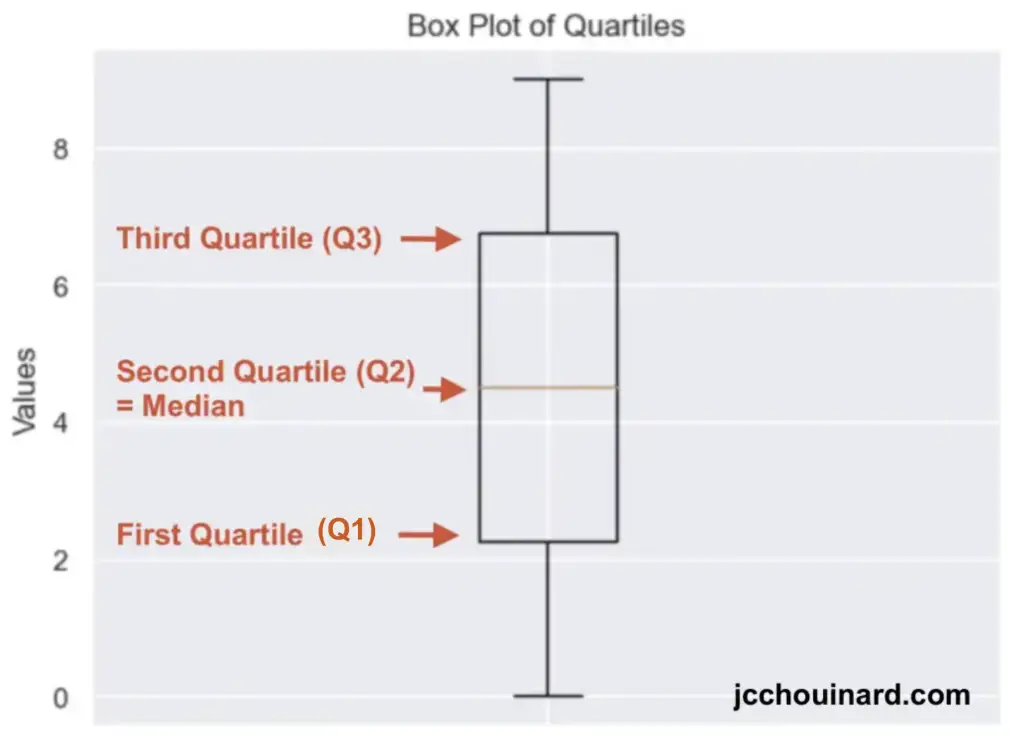
import matplotlib.pyplot as plt
import numpy as np
# Example numerical dataset
data = np.array(range(10))
# Create a box plot
plt.boxplot(data)
# Add labels and a title
plt.xlabel("Dataset")
plt.ylabel("Values")
plt.title("Box Plot of Quartiles")
# Show the plot
plt.show()
نحوه محاسبه محدوده بین چارکی
محدوده بین چارکی با کم کردن داده های چارک 1 از داده های چارک 3 محاسبه می شود.
IQR = Q3(data) - Q1(data)نحوه محاسبه محدوده بین ربع در پایتون
محدوده های بین چارکی (IQR) را می توان با استفاده از پایتون محاسبه کرد np.quantiles() برای کم کردن چندک اول از سوم، یا با استفاده از iqr() تابع از scipy.stats مدول.
با np.quantile
np.quantile(data, 0.75) - np.quantile(data, 0.25)با Scipy.stats
from scipy.stats import iqr
iqr(range(1,10))
4.0واریانس در آمار چیست؟
واریانس در آمار معیاری برای اندازه گیری پراکندگی یا تغییرپذیری یک مجموعه داده است.
واریانس میزان تفاوت نقاط داده فردی در یک مجموعه داده با میانگین (متوسط) مجموعه داده را کمی نشان می دهد.
به بیان ساده، واریانس نشان می دهد که نقاط داده در اطراف میانگین چقدر پراکنده یا پراکنده هستند.
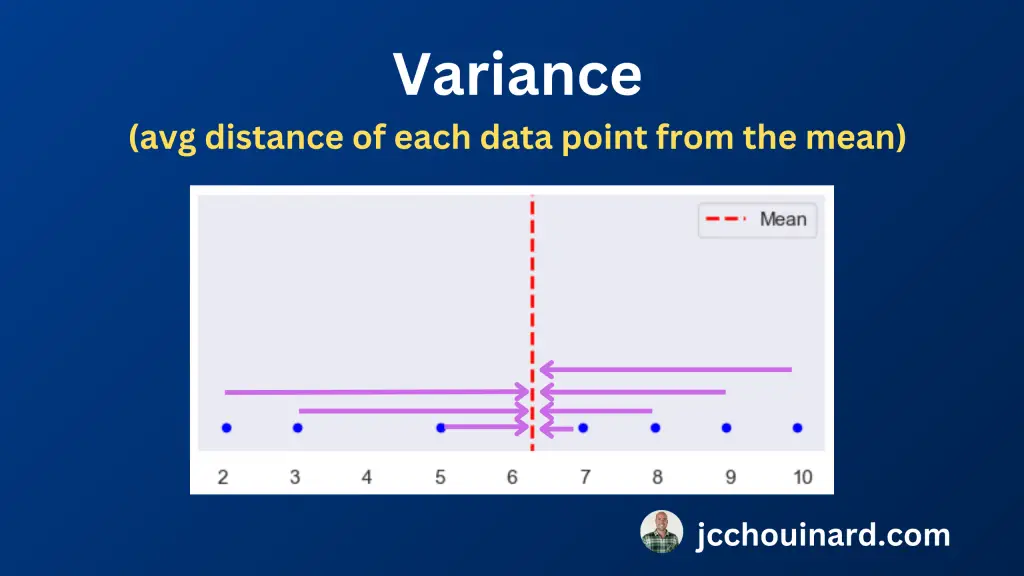
در نمودار پراکنده، ما به راحتی می توانیم پراکندگی داده ها را با اصلاح واریانس تجسم کنیم.
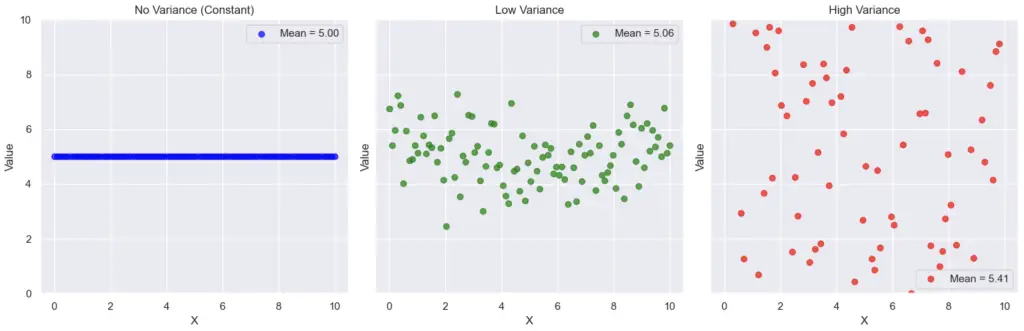
نحوه محاسبه واریانس
برای محاسبه واریانس، میانگین را از هر نقطه داده کم کنید، فاصله ها را مربع کنید، تمام مقادیر را مجذور کنید و بر تعداد نقاط داده منهای 1 تقسیم کنید.
فرمول واریانس

نحوه محاسبه واریانس در پایتون
برای محاسبه واریانس در پایتون، از عبارت استفاده کنید var() تابع از numpy یا مجموع مجذور فاصله ها را از میانگین محاسبه کرده و بر تعداد مقادیر منهای 1 تقسیم کنید.
واریانس را با پایتون Numpy محاسبه کنید
برای محاسبه واریانس در پایتون با Numpy، استفاده کنید var() عملکرد با ddof آرگومان بر روی 1 تنظیم شده است ddof آرگومان برای تعیین فرمول مورد استفاده در هنگام کار با نمونه داده استفاده می شود.
# Variance with np.var()
import numpy as np
data_points = [1,2,3,4,5]
np.var(data_points, ddof=1)
واریانس را به صورت دستی با پایتون محاسبه کنید
برای محاسبه دستی واریانس در پایتون مراحل زیر را دنبال کنید:
- فاصله ها را از میانگین محاسبه کنید
- مربع فاصله ها
- مجذور فواصل را جمع کنید
- تعداد نقاط داده را پیدا کنید
- مجموع مجذور فواصل را بر n-1 تقسیم کنید
import numpy as np
data_points = [1,2,3,4,5]
# 1. Calculate distances from the mean
distances = data_points - np.mean(data_points)
print('1. Mean distances:', distances)
# 2. Square the distances
sqr_distances = distances ** 2
print('2. Squared distances:', sqr_distances)
# 3. Sum the squared distances
summed_distances = sum(sqr_distances)
print('3. Sum of the squared distances:', summed_distances)
# 4. Find Number of data points
n = len(data_points)
print('4. Number of data points:', n)
# 5. Divide the sum of the squared distances by n-1
variance = summed_distances / (n - 1)
print('5. Variance:', variance)
خروجی
1. Mean distances: [-2. -1. 0. 1. 2.]
2. Squared distances: [4. 1. 0. 1. 4.]
3. Sum of the squared distances: 10.0
4. Number of data points: 5
5. Variance: 2.5توجه داشته باشید که نماد S^2 نشان می دهد که چگونه نتیجه واریانس یک مقدار مربع است که می تواند برای محاسبه انحراف استاندارد از ریشه sqare استفاده شود.
انحراف معیار در آمار چیست؟
انحراف معیار در آمار، معیاری برای اندازه گیری گسترش یا تغییرپذیری یک مجموعه داده است که با استفاده از ریشه مربع واریانس محاسبه می شود.
به بیان ساده، انحراف معیار، ریشه مربع واریانس است.
مزیت انحراف استاندارد در مقایسه با واریانس این است که انحراف استاندارد در همان واحدهای نقاط داده شما (ثانیه، دقیقه، روز و غیره) است.
نحوه محاسبه انحراف استاندارد
برای محاسبه انحراف معیار، واریانس را محاسبه کرده و ریشه دوم واریانس را محاسبه کنید.
فرمول انحراف معیار

نحوه محاسبه انحراف استاندارد در پایتون
برای محاسبه انحراف استاندارد در پایتون، از عبارت استفاده کنید std() تابع از numpy یا استفاده کنید np.sqrt() تابع بر روی واریانس محاسبه شده
np.std(data_points)np.sqrt(np.var(data_points))فقط توجه داشته باشید که با استفاده از تابع np.std() تابع sqrt() بر روی تغییرات محاسبه شده از تقسیم با n محاسبه می شود نه n-1.
import numpy as np
data_points = [1,2,3,4,5]
# Standard deviation with np.std
print('std():',np.std(data_points))
# Standard deviation with np.sqrt(np.var()) n
variance = np.var(data_points)
print('np.sqrt(np.var()):',np.sqrt(variance))
# Standard deviation with np.std
print('std(ddof=1):',np.std(data_points, ddof=1))
# Standard deviation with np.sqrt(np.var()) n-1
variance = np.var(data_points, ddof=1)
print('np.sqrt(np.var(ddof=1)):',np.sqrt(variance))
خروجی
std(): 1.4142135623730951
np.sqrt(np.var()): 1.4142135623730951
std(ddof=1): 1.5811388300841898
np.sqrt(np.var(ddof=1)): 1.5811388300841898ضریب تغییرات (CV) در آمار چقدر است
ضریب تغییرات یا CV در آمار یک معیار نسبی از تنوع است که با نسبت درصد انحراف استاندارد و میانگین نشان داده می شود.
نحوه محاسبه ضریب تغییرات
برای محاسبه ضریب تغییرات (CV)، باید انحراف معیار و میانگین یک مجموعه داده را محاسبه کنید. سپس با محاسبه نسبت انحراف معیار به میانگین، ضریب تغییرات را بیابید.
cv = (std/mean) * 100نحوه محاسبه ضریب تغییرات در پایتون
برای محاسبه ضریب تغییرات در پایتون از عبارت استفاده کنید mean() و std() عملکرد از numpy کتابخانه، و سپس انحراف استاندارد را بر میانگین تقسیم کنید.
import numpy as np
# Sample data
data_points = [1, 2, 3, 4, 5]
# Calculate the mean (average) of the data
mean = np.mean(data_points)
# Calculate the standard deviation of the data
std_dev = np.std(data_points)
# Calculate the Coefficient of Variation (CV)
cv = (std_dev / mean) * 100
# Print the result
print(f"Coefficient of Variation (CV): {cv:.2f}%")
Coefficient of Variation (CV): 47.14%میانگین انحراف مطلق در آمار چیست؟
میانگین انحراف مطلق یا MAD در آمار، میانگین اختلاف مطلق بین نقاط داده و میانگین است. اغلب به عنوان جایگزینی برای انحراف استاندارد استفاده می شود زیرا نیازی به مربع انحراف ندارد.
نحوه محاسبه میانگین انحراف مطلق
برای محاسبه میانگین انحراف مطلق، تفاوت بین هر نقطه داده و میانگین را محاسبه کنید. سپس مقادیر مطلق را بدست آورید. در نهایت، میانگین را محاسبه کنید.
mad = mean(absolute(data_points - mean(data_points)))نحوه محاسبه میانگین انحراف مطلق در پایتون
برای محاسبه میانگین انحراف مطلق (MAD) در پایتون، مقادیر مطلق را از تفریق میانگین از هر نقطه داده بدست آورید، سپس میانگین مقادیر مطلق را پیدا کنید.
import numpy as np
data_points = [1,2,3,4,5]
# 1. Calculate distances from the mean
distances = data_points - np.mean(data_points)
print('1. Mean distances:', distances)
# 2. Calculate the mean absolute deviation
mad = np.mean(np.abs(distances))
print('2. Mean absolute deviation:', mad)
1. Mean distances: [-2. -1. 0. 1. 2.]
2. Mean absolute deviation: 1.2میانگین مربع ریشه (RMS) در آمار چیست؟
ریشه میانگین مربع یا RMS در آمار نشان دهنده ریشه دوم میانگین مقادیر مجذور مورد استفاده برای اندازه گیری بزرگی تغییرات است.
نحوه محاسبه ریشه میانگین مربع
از نظر ریاضی، RMS را می توان به صورت زیر نشان داد:
RMS = sqrt((x₁² + x₂² + ... + xₙ²) / n)نحوه محاسبه ریشه میانگین مربع در پایتون
برای محاسبه ریشه میانگین مربع در پایتون،
- هر نقطه داده را در مجموعه داده خود مربع کنید.
- میانگین مقادیر مجذور را محاسبه کنید
- جذر را میانگین مقادیر مجذور آن بگیرید.
import numpy as np
# Sample data
data_points = [1, 2, 3, 4, 5]
# 1. Square each value
squared_data = [x**2 for x in data_points]
# 2. Find the mean of the squared values
mean_squared = np.mean(squared_data)
# 3. Take the square root
rms = np.sqrt(mean_squared)
print(f"Root Mean Square (RMS): {rms}")
Root Mean Square (RMS): 3.3166247903554محدوده صدک در آمار چیست؟
محدوده صدک یک آمار خلاصه است که با استفاده از محدوده بین صدک های خاص (به عنوان مثال صدک 10 و 90) استخراج شده است. محدودههای صدک بینشهایی را در مورد X% از دادهها ارائه میکنند، که کمتر تحتتاثیر نقاط پرت قرار میگیرد.
نحوه محاسبه محدوده صدک در پایتون
محاسبه محدوده های صدک در پایتون شبیه به محاسبه محدوده های بین چارکی است، اما با صدک های سفارشی مشخص شده است. شما می توانید این کار را با استفاده از percentile() عملکرد از numpy کتابخانه
# Calculate the first percentile (Q1)
q1 = np.percentile(sorted_data, 25)
# Calculate the third percentile (Q3)
q3 = np.percentile(sorted_data, 75)
# Calculate the percentile range
percentile_range = q3 - q1
موارد پرت
نقاط پرت در آمار، نقاط داده افراطی هستند که تفاوت قابل توجهی با سایرین دارند. آنها می توانند تأثیر زیادی بر معیارهای تغییرپذیری داشته باشند و باید توسط آماردانان و دانشمندان داده درک شوند و بر این اساس با آنها برخورد شود. آموزش ما را برای درک نحوه شناسایی نقاط پرت در یک مجموعه داده بررسی کنید.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. نویسنده در پایتون، بازیابی اطلاعات، سئو و یادگیری ماشین. نویسنده مهمان در SearchEngineJournal، SearchEngineLand و OnCrawl.