در این راهنما، با ارائه مثالهای پایتون برای توضیح نحوه به کارگیری این مفهوم، آمار خلاصهای را برای علم داده معرفی میکنیم.
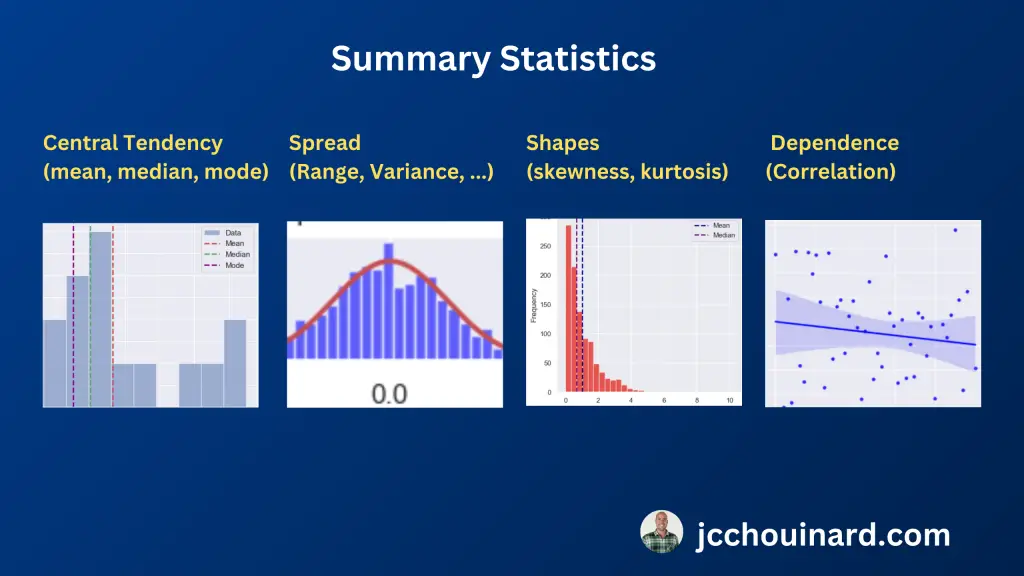
آمار خلاصه چیست؟
استاتیک خلاصه در آمار توصیفی برای خلاصه کردن و توصیف مشاهدات در یک مجموعه داده استفاده می شود.
خلاصه اقدامات آماری
آمار خلاصه معمولاً برای اکتشاف داده ها استفاده می شود تا مقادیر زیادی از داده ها را به ساده ترین الگوهای آنها منتقل کند.
آمار خلاصه شامل اقداماتی مانند:
- میانگین (متوسط)
- میانه (مقدار متوسط)،
- حالت (متداول ترین مقدار)،
- انحراف معیار (اندازه گیری پراکندگی داده ها)،
- چارک (تقسیم داده ها به چهار قسمت مساوی).
نمونه های آماری خلاصه
آمار خلاصه مشاهدات یک مجموعه داده را با مشاهده موارد زیر خلاصه و توصیف می کند:
- اقدامات گرایش مرکزی: میانگین، میانه، حالت
- اندازه گیری اشکال توزیع ها: چولگی، کشیدگی
- معیارهای تغییرپذیری (گسترش، پراکندگی): واریانس، انحراف معیار
- معیارهای وابستگی آماری: همبستگی
1. معیارهای گرایش مرکزی در آمار خلاصه
در آمار، از معیارهای گرایش مرکزی برای خلاصه کردن داده ها با یافتن مکان مرکز داده ها استفاده می شود. 3 معیار مرکز عبارتند از منظور داشتن را میانه و حالت.
- منظور داشتن: مقدار متوسط یک مجموعه داده
- میانه: مقدار متوسط در یک مجموعه داده
- حالت: بیشترین مقدار در یک مجموعه داده وجود دارد.
در اینجا دستورالعمل های کلی وجود دارد که به شما کمک می کند معیار مناسبی برای گرایش مرکزی را انتخاب کنید.
- میانگین: حساس تر به موارد پرت. برای داده های متقارن (به طور معمول توزیع شده) بهتر است.
- رسانه: حساسیت کمتری نسبت به موارد پرت. برای داده های غیر متقارن (کج) بهتر است.
- حالت: برای داده های طبقه بندی مناسب تر است
برای کسب اطلاعات بیشتر در مورد این موضوع، آموزش ما را در مورد سنجش گرایش مرکزی بخوانید.
2. اندازهگیریهای شکلهای توزیع در آمار خلاصه
داده ها ممکن است به روش های مختلف توزیع شوند. گاهی اوقات متقارن است (مثلاً توزیع نرمال)، گاهی اوقات غیر متقارن (مثلاً به سمت راست/چپ انحرافی) و گاهی باریکتر و تندتر از دیگران است (مثلاً کشیدگی).
برای شناسایی این اشکال مختلف توزیع، آماردانان عمدتاً از دو نوع مختلف آمار خلاصه استفاده می کنند:
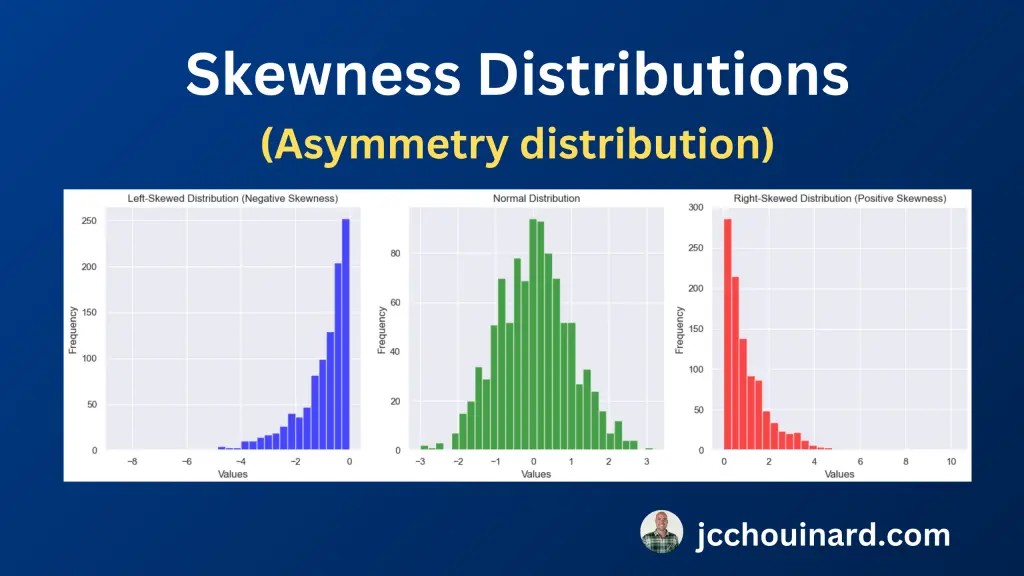
- چولگی: اندازه گیری عدم تقارن یک توزیع
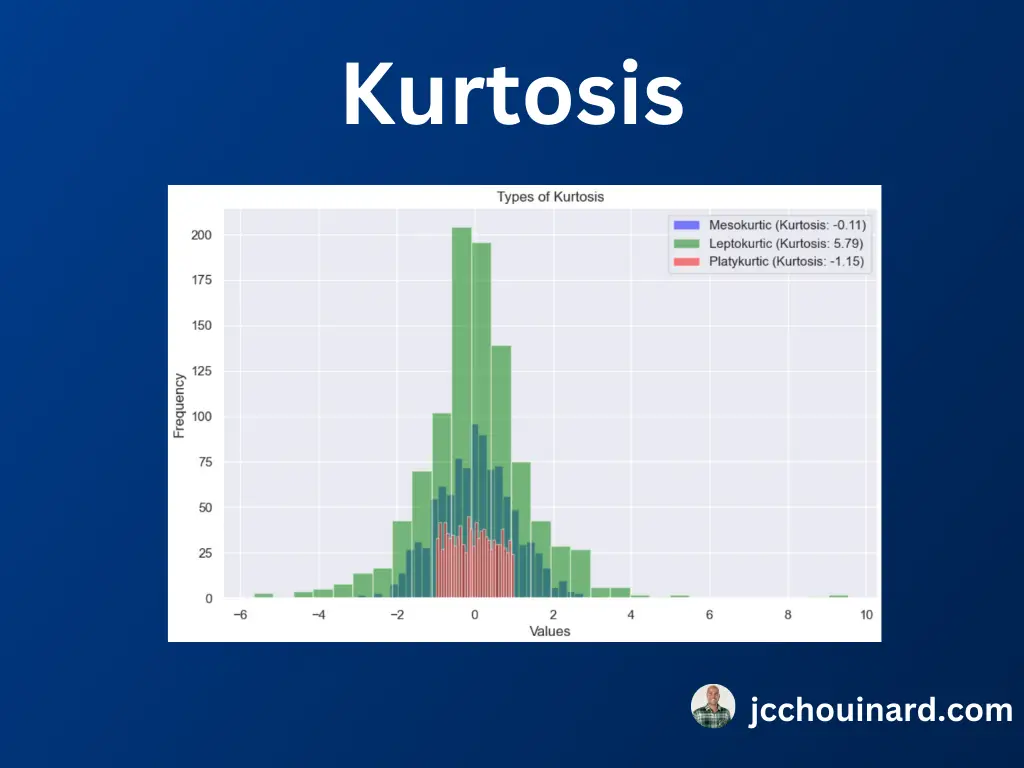
- کورتوز: اندازه گیری دنباله دار بودن یک توزیع
هنگام ارزیابی چولگی در داده ها، عدم تقارن توزیع و نرمال بودن، چولگی چپ یا راست بودن آن را ارزیابی می کنیم.
- انحراف صفر: میانگین = میانه، توزیع نرمال
- انحراف چپ: منظور داشتن انحراف سمت راست: میانگین > میانه
هنگام ارزیابی کشش در داده ها، ما دنباله بودن توزیع و میزان افراطی بودن داده ها نسبت به موارد دورافتاده را ارزیابی می کنیم. سه نوع توزیع با کشش عبارتند از:
- لپتوکورتیک: دم های بزرگ، نقاط پرت شدیدتر، کشیدگی مثبت
- مزوکورتیک: دم متوسط، کشیدگی برابر با صفر
- Platykurtic: دم نازک، نقاط پرت کمتر، کشیدگی منفی
برای کسب اطلاعات بیشتر، مقاله ما را در مورد اندازه گیری اشکال و توزیع در آمار خلاصه بخوانید.
3. معیارهای متغیر (Spread) در آمار
برای درک توزیع داده ها، درک تغییرپذیری (یا گسترش) داده ها مهم است. تغییرپذیری نشان می دهد که نقاط داده چقدر نزدیک یا از هم فاصله دارند.
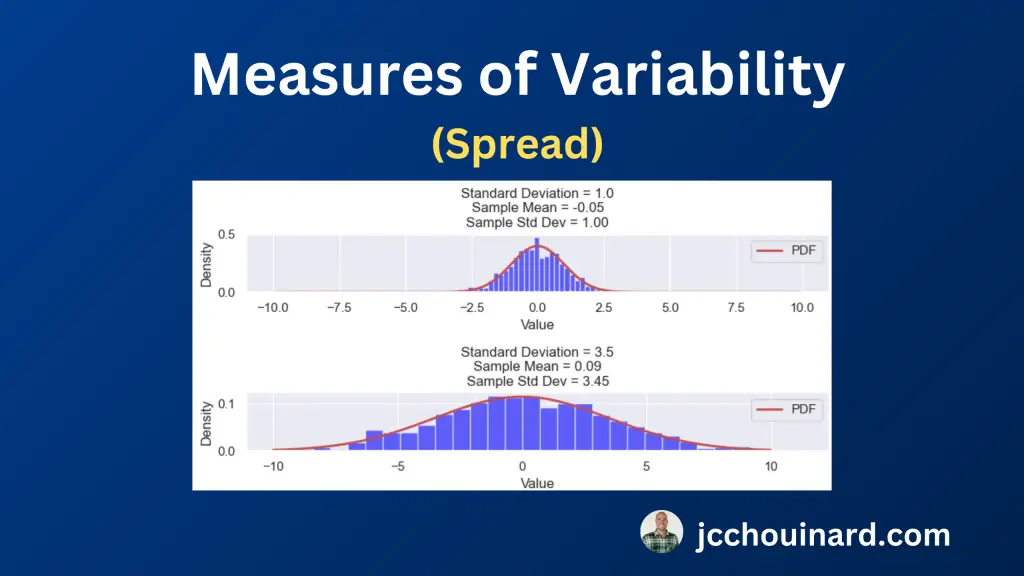
8 معیار تغییرپذیری در آمار خلاصه عبارتند از: دامنه، محدوده بین چارکی (IQR)، واریانس، انحراف معیار، ضریب تغییرات (CV)، میانگین انحراف مطلق، مربع میانگین ریشه (RMS) و محدوده صدک. .
- دامنه: تفاوت بین مقادیر حداکثر و حداقل در یک مجموعه داده
- محدوده بین چارکی (IQR): تفاوت بین چارک سوم و اول (Q3 و Q1). تمرکز بر 50 درصد میانی برای کاهش تأثیر عوامل پرت.
- واریانس: میانگین فاصله هر نقطه داده از میانگین
- انحراف معیار: ریشه مربع واریانس
- ضریب تغییرات (CV): نسبت درصد انحراف معیار به میانگین
- میانگین انحراف مطلق: میانگین اختلاف مطلق بین نقاط داده و میانگین
- ریشه میانگین مربع (RMS): جذر میانگین مقادیر مجذور.
- محدوده صدک: محدوده بین صدک های خاص برای ارائه بینش به مرکز داده ها کمتر تحت تاثیر مقادیر شدید.
برای کسب اطلاعات بیشتر در مورد این موضوع، مقاله ما در مورد معیارهای تغییرپذیری در آمار را بخوانید.
4. معیارهای وابستگی آماری (همبستگی) در آمار خلاصه
8 معیار وابستگی آماری مورد استفاده برای ارزیابی همبستگی بین متغیرهای چندگانه عبارتند از:
- کوواریانس: چقدر دو متغیر تصادفی با هم تغییر می کنند
- ضریب همبستگی: رابطه خطی دو متغیر پیوسته
- همبستگی رتبه اسپیرمن: قدرت/جهت رابطه یکنواخت بین دو متغیر.
- کندالز تاو (τ): قدرت/جهت ارتباط ترتیبی بین دو متغیر.
- همبستگی نقطه ای-دوسری: رابطه بین متغیرهای پیوسته و باینری
- ضریب فی (φ): ارتباط بین دو متغیر باینری.
- جداول احتمالی / تست های مربع کای: ارتباط بین دو متغیر مقوله ای
- Cramer's V: ارتباط برای متغیرهای طبقه بندی شده بر اساس آمار کای اسکوئر
آموزش ما را در مورد این موضوع بخوانید تا متوجه شوید که معیارهای وابستگی آماری چیست، چگونه کار می کنند و چگونه از آنها در پایتون استفاده کنید.
آمار خلاصه در یادگیری ماشینی
آمار خلاصه جزء مهمی از پیش پردازش داده ها برای یادگیری ماشین است.
همانطور که دیدیم، آمارهای خلاصه توسط دانشمندان داده برای به دست آوردن بینشی در مورد تمایلات مرکزی، تغییرات و نقاط پرت مجموعه داده استفاده می شود.
با استفاده از این اطلاعات، دانشمند داده میتواند دادهها را از طریق مقیاسبندی دادهها، نرمالسازی و مدیریت مقادیر گمشده برای یادگیری ماشین آماده کند.
آمار خلاصه همچنین توسط الگوریتمهای یادگیری ماشینی محبوب مانند درختهای تصمیم، جنگلهای تصادفی، و نزدیکترین همسایهها برای تصمیمگیری تقسیمبندی و/یا تعیین اهمیت ویژگی استفاده میشود.
به عنوان مثال، الگوریتمهای درخت تصمیم از معیارهایی مانند ناخالصی جینی یا آنتروپی استفاده میکنند که برای ارزیابی تقسیمبندی ویژگیها به آمار خلاصه تکیه میکنند. در مدلهای رگرسیون، آمار خلاصه به شناسایی روابط بین متغیرها، کمک به انتخاب ویژگی و تفسیر مدل کمک میکند.
در هسته خود، آمار خلاصه به افزایش کیفیت داده ها و تسهیل آموزش مدل یادگیری ماشین کمک می کند.
نتیجه
در نتیجه، آمار خلاصه در پایتون نقش مهمی در درک داده ها دارد.
آمار خلاصه بینش هایی را برای دانشمندان و تحلیلگران داده در مورد گرایش مرکزی، گسترش و توزیع داده ها فراهم می کند.
آمار خلاصه متداول عبارتند از:
- معیارهای گرایش مرکزی (میانگین، میانه، حالت)،
- معیارهای تغییرپذیری (واریانس، انحراف معیار، محدوده)،
- اندازه گیری اشکال توزیع ها
- معیارهای وابستگی آماری (ضرایب همبستگی مانند r پیرسون، ρ اسپیرمن، و τ کندال).
پایتون دارای کتابخانه هایی مانند NumPy، پانداها و SciPy برای محاسبه و تجسم آمار خلاصه است.
درک آمار خلاصه برای اکتشاف داده ها، آزمایش فرضیه ها و ساخت مدل ضروری است و آن را به یک مهارت اساسی برای دانشمندان داده و تحلیلگرانی که با پایتون کار می کنند تبدیل می کند.

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. نویسنده در پایتون، بازیابی اطلاعات، سئو و یادگیری ماشین. نویسنده مهمان در SearchEngineJournal، SearchEngineLand و OnCrawl.