

@jfpettitیعقوب پتیت
محقق ML ، وبلاگ نویسی در مورد یادگیری تقویت ، یادگیری ماشین و هوش مصنوعی.
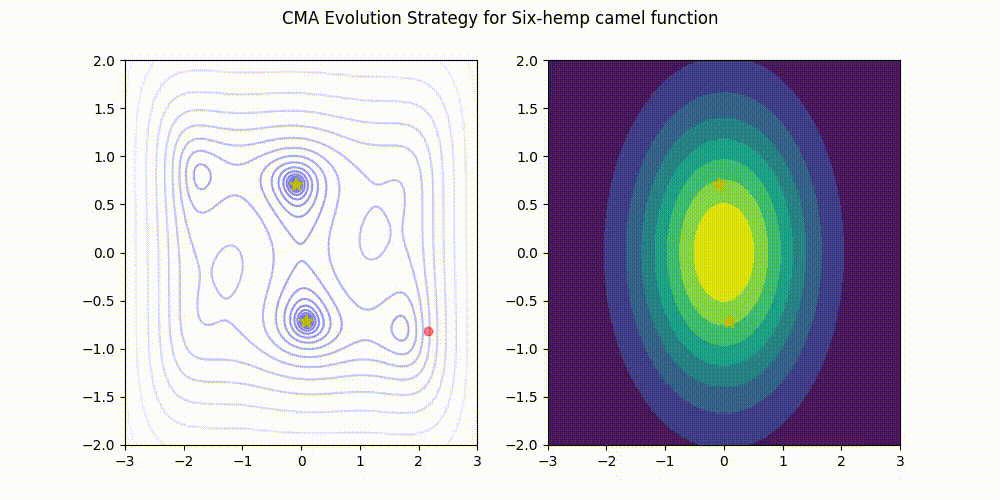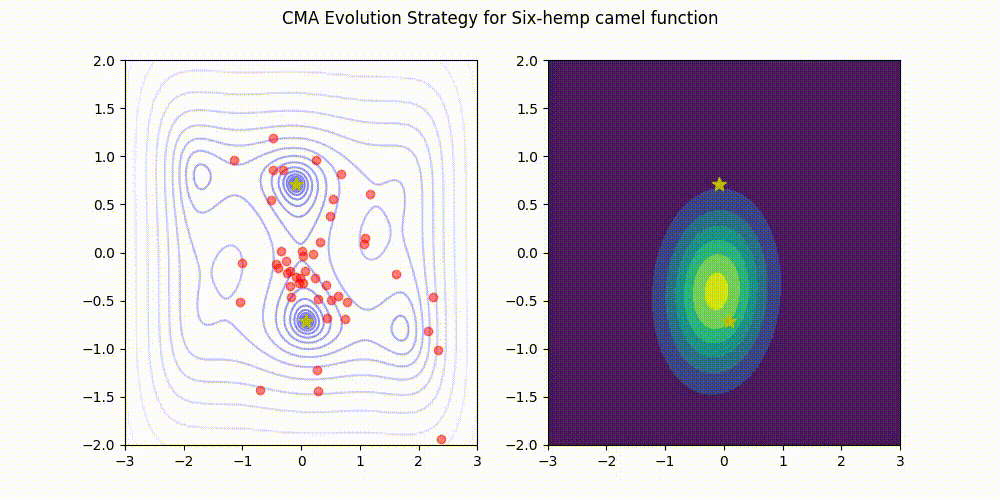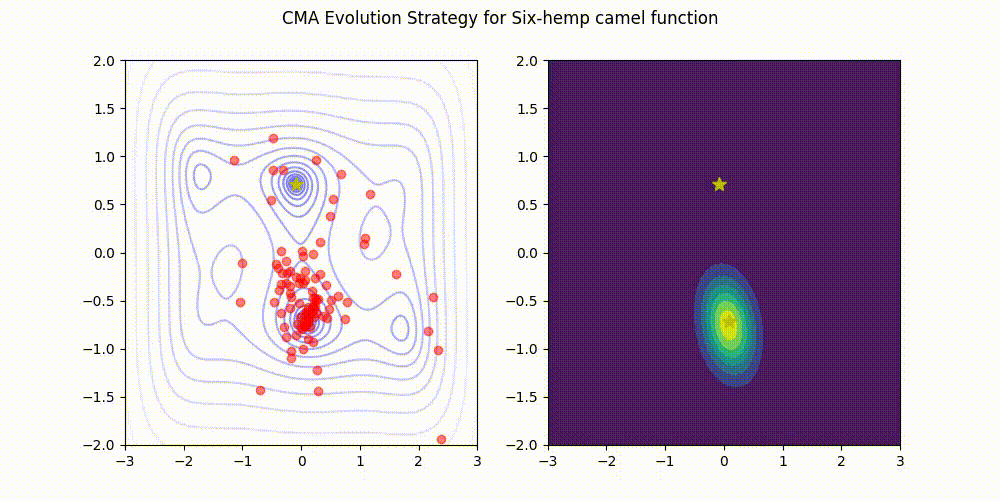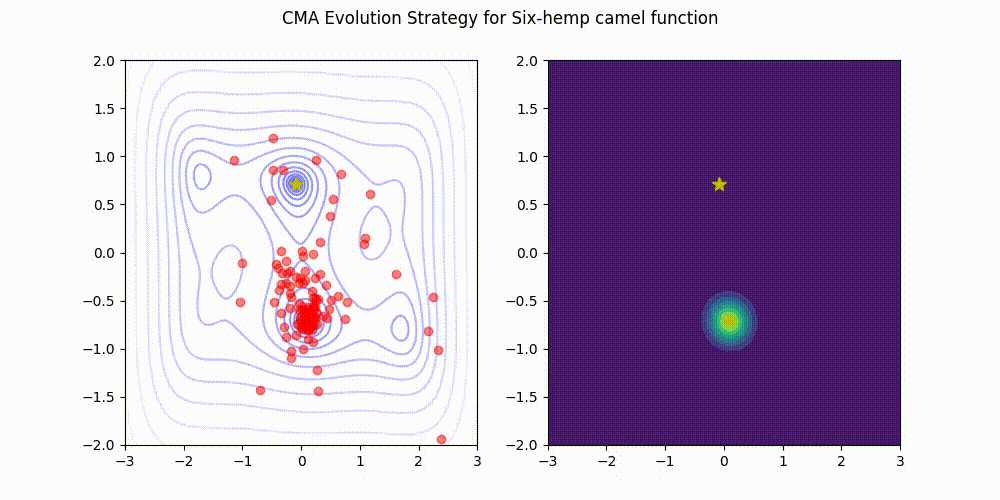
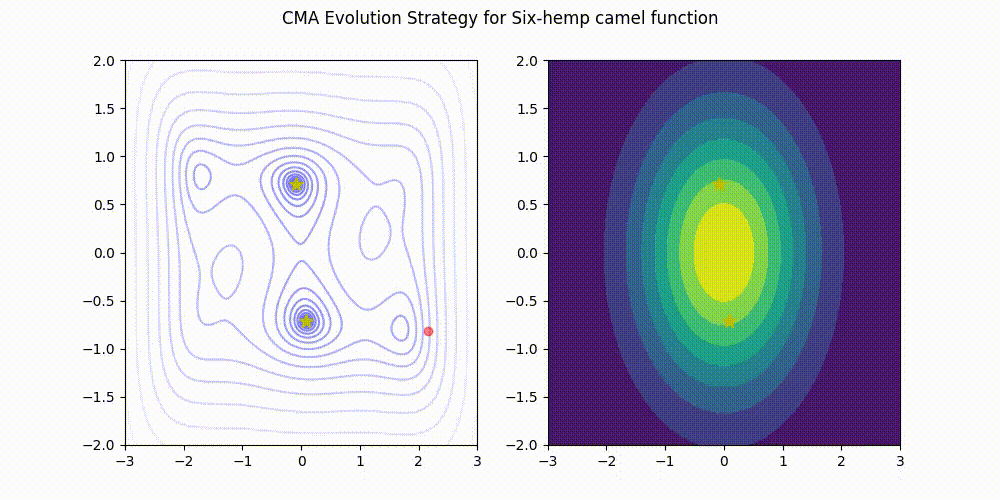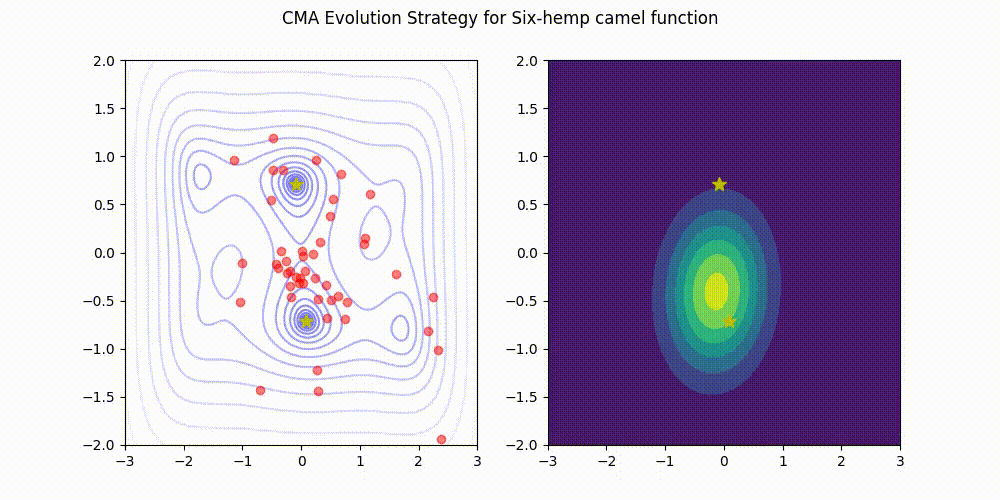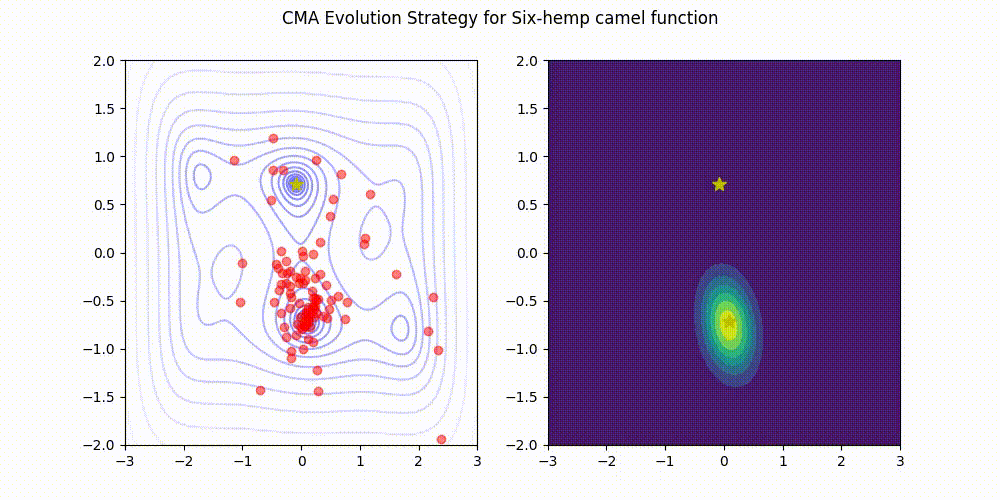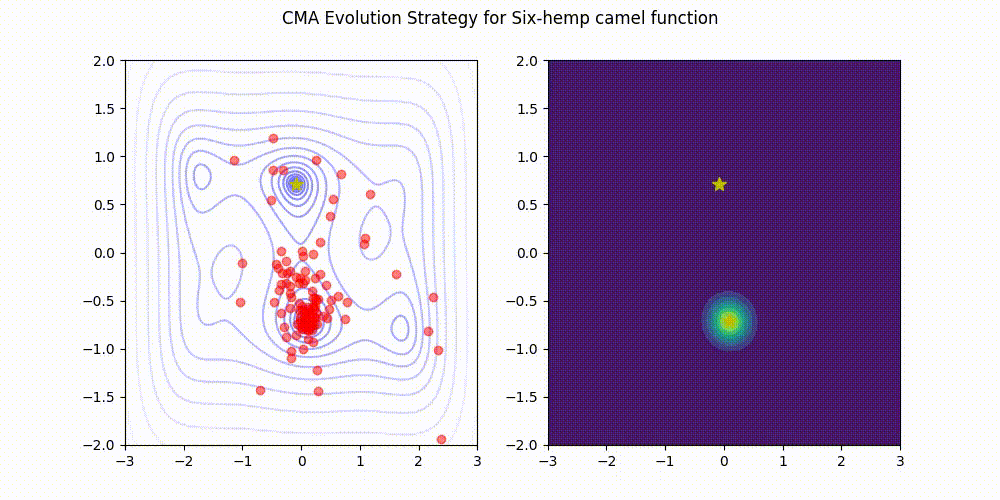
تمام اعتبار تصویر به نگهدارندگان کتابخانه CMA-ES در GitHub. منبع تصویر
پیوند به کد در GitHub
اخیراً ، من نیاز به جستجو برای سیاست های پیش پا افتاده در یک محیط داشتم. این سیاست ها چیزهای ساده ای بودند ، مانند همیشه با همان اقدام یا هر عملی دیگر ک برای بهینه سازی هرچه بیشتر این سیاستهای پیش پا افتاده ، من به چارچوب Optuna متوسل شدم. اما وقتی در اسناد و مدارک آنها فرو می رفتم ، متوجه شدم که آنها مجموعه خوبی از بهینه سازها را پیدا کرده اند و من تعجب کردم: اگر به دنبال سیاست های نه چندان پیش پا افتاده باشم ، چه می کنم؟
آیا می توانم همه پارامترهای یک لایه شبکه عصبی کوچک را جستجو کنم و عملکرد خوبی داشته باشم؟ پاسخ ، خواهیم دید ، بله است … در بعضی از محیط ها.
راه اندازی
من تصمیم گرفتم آن را ساده نگه دارم و دو سیاست را امتحان کنم: یکی من “سیاست متراکم گوسی” و دیگری “سیاست متراکم” می نامم. من فکر می کنم این نام ها از نظر فنی درست هستند اما همچنین می توانند بسیار مات به نظر برسند ، بنابراین منظورم را توضیح می دهم. در صورت علاقه کد من را در این لینک بررسی کنید.
سیاست ها
هر دو خط مشی مشابه شبکه عصبی 1 لایه است: ما با گرفتن نقطه محصول ورودی با آرایه ای از … خروجی را محاسبه می کنیم.