امروز، در مورد نحوه انجام کار یاد خواهید گرفت خراش دادن وب با BeautifulSoup. شما یاد خواهید گرفت که چگونه از کتابخانه درخواست ها برای واکشی صفحات وب و از کتابخانه BeautifulSoup برای تجزیه HTML در پایتون استفاده کنید.
در این آموزش یاد خواهید گرفت:
- اصول اولیه خراش دادن و تجزیه وب
- نحوه نصب BeautifulSoup
- چگونه یک فایل HTML محلی را تجزیه کنیم
- از Requests و BeautifulSoup برای خراش دادن و تجزیه صفحات وب استفاده کنید
- روش هایی که برای یافتن عناصر درون HTML نیاز دارید
- فیلترهایی که می توانید برای بهبود تطابق در داخل HTML استفاده کنید
Web Scraping چیست؟
خراش دادن وب فرآیند استفاده از یک ربات برای استخراج داده ها از یک وب سایت و صادرات آن به یک قالب قابل هضم است. یک وب اسکراپر کد HTML را از یک صفحه وب استخراج می کند، که سپس برای استخراج اطلاعات ارزشمند تجزیه می شود.
سوپ زیبا چیست؟
سوپ زیبا یک کتابخانه تجزیه در پایتون است که برای خراش دادن اطلاعات از HTML یا XML استفاده می شود. تجزیه کننده BeautifulSoup اصطلاحات پایتون را برای جستجو و اصلاح درخت تجزیه فراهم می کند.
به زبان ساده، BeautifulSoup کتابخانه ای است که به شما امکان می دهد HTML را به روشی قابل استفاده قالب بندی کنید و عناصر را از آن استخراج کنید.
تجزیه در Web Scraping چیست؟
تجزیه در وب اسکرپینگ فرآیند تبدیل داده های بدون ساختار به یک قالب ساختاریافته (به عنوان مثال درخت تجزیه) است که خواندن، استفاده و استخراج داده ها از آن آسان تر است.
اساساً تجزیه به معنای تقسیم یک سند در تکه های قابل استفاده است.
شروع با BeautifulSoup
نحوه نصب BeautifulSoup
از pip برای نصب BeautifulSoup در پایتون استفاده کنید.
$ pip install beautifulsoup4
تجزیه ساده با سوپ زیبا
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>I am learning <span>BeautifulSoup</span></p>")
soup.find('span')
<span>BeautifulSoup</span>
بهترین روش های اسکراپینگ وب
- از وب سایت های اسباب بازی برای تمرین استفاده کنید
- از API ها به جای وب اسکرپینگ استفاده کنید
- ابتدا بررسی کنید که آیا داده ها در جای دیگری در دسترس هستند (مثلاً خزیدن مشترک)
- به robots.txt احترام بگذارید
- سرعت خراشیدن خود را کاهش دهید
- درخواست های خود را کش کنید
چگونه HTML را با BeautifulSoup تجزیه کنیم
مراحل زیر را برای تجزیه HTML در BeautifulSoup دنبال کنید:
- BeautifulSoup را نصب کنید
برای نصب BeautifulSoup از pip استفاده کنید
$ pip install beautifulsoup4 - کتابخانه BeautifulSoup را در پایتون وارد کنید
برای وارد کردن BeautifulSoup در پایتون، کلاس BeautifulSoup را از کتابخانه bs4 وارد کنید.
from bs4 import BeautifulSoup - HTML را تجزیه کنید
برای تجزیه HTML، شی BeautifulSoup را ایجاد کنید و HTML را به عنوان آرگومان مورد نیاز اضافه کنید. شی سوپ یک نسخه تجزیه شده از HTML خواهد بود.
soup = BeautifulSoup("<p>your HTML</p>") - از روش های شی BeautifulSoup برای استخراج اطلاعات از HTML استفاده کنید
کتابخانه BeautifulSoup روشهای داخلی زیادی برای استخراج دادهها از HTML دارد. برای استخراج عناصر خاص از HTML تجزیه شده از متدهایی مانند ()soup.find یا ()soup.find_all استفاده کنید.
تجزیه اولین HTML خود با BeautifulSoup
اولین یادگیری این آموزش BeautifulSoup، تجزیه این HTML ساده خواهد بود.
نمونه HTML برای تجزیه
html = '''
<html>
<head>
<title>Simple SEO Title</title>
<meta name="description" content="Meta Description with less than 300 characters.">
<meta name="robots" content="noindex, nofollow">
<link rel="alternate" href="https://www.example.com/en" hreflang="en-ca">
<link rel="canonical" href="https://www.example.com/fr">
</head>
<body>
<header>
<div class="nav">
<ul>
<li class="home"><a href="#">Home</a></li>
<li class="blog"><a class="active" href="#">Blog</a></li>
<li class="about"><a href="#">About</a></li>
<li class="contact"><a href="#">Contact</a></li>
</ul>
</div>
</header>
<div class="body">
<h1>Blog</h1>
<p>Lorem ipsum dolor <a href="#">Anchor Text Link</a> sit amet consectetur adipisicing elit. Ipsum vel laudantium a voluptas labore. Dolorum modi doloremque, dolore molestias quos nam a laboriosam neque asperiores fugit sed aut optio earum!</p>
<h2>Subtitle</h2>
<p>Lorem ipsum dolor sit amet consectetur adipisicing elit. Ipsum vel laudantium a voluptas labore. Dolorum modi doloremque, dolore molestias quos nam a <a href="#" rel="nofollow">Nofollow link</a> laboriosam neque asperiores fugit sed aut optio earum!</p>
</div>
</body>
</html>'''
متغیر HTML که به تازگی ایجاد کردیم مشابه خروجی است که هنگام خراش دادن یک صفحه وب به دست می آوریم. این HTML است، اما به عنوان متن ذخیره می شود.
این خیلی مفید نیست زیرا جستجو در آن دشوار است.
می توانید از عبارات منظم برای تجزیه محتوای متن استفاده کنید، اما راه بهتری در دسترس است: تجزیه با BeautifulSoup.
تجزیه HTML
برای تجزیه HTML با BeautifulSoup، یک سازنده BeautifulSoup را با اضافه کردن HTML برای تجزیه به عنوان یک آرگومان مورد نیاز، و نام تجزیه کننده به عنوان یک آرگومان اختیاری، نمونه سازی کنید.
# Parsing an HTML File
from bs4 import BeautifulSoup
import requests
soup = BeautifulSoup(html, 'html.parser')
این HTML تجزیه شده را به یک شی BeautifulSoup برمی گرداند.
سپس هر عنصر HTML (تگ عنوان در این مورد) را از شی BeautifulSoup با soup.find() روش.
print(soup.find('title'))
<title>Simple SEO Title</title>
یک فایل HTML محلی را با BeautifulSoup تجزیه کنید
اگر یک فایل HTML در جایی در رایانه خود ذخیره کرده اید، می توانید یک فایل HTML محلی را با BeautifulSoup نیز تجزیه کنید.
# Parsing an HTML File
from bs4 import BeautifulSoup
import requests
with open('/path/to/file.html') as f:
soup = BeautifulSoup(f, 'html.parser')
print(soup)
تجزیه یک صفحه وب با BeautifulSoup
برای تجزیه یک صفحه وب با BeautifulSoup، HTML صفحه را با استفاده از کتابخانه درخواست های Python واکشی کنید. شما می توانید به روش های مختلف به HTML صفحه دسترسی داشته باشید: درخواست های HTTP، برنامه های کاربردی مبتنی بر مرورگر، دانلود دستی از مرورگر وب.
تا کنون، نحوه تجزیه یک فایل HTML محلی را که واقعاً در حال خراش دادن وب نیست، دیدهایم.
اکنون یک صفحه وب را برای استخراج HTML آن و سپس تجزیه محتوا با BeautifulSoup واکشی می کنیم.
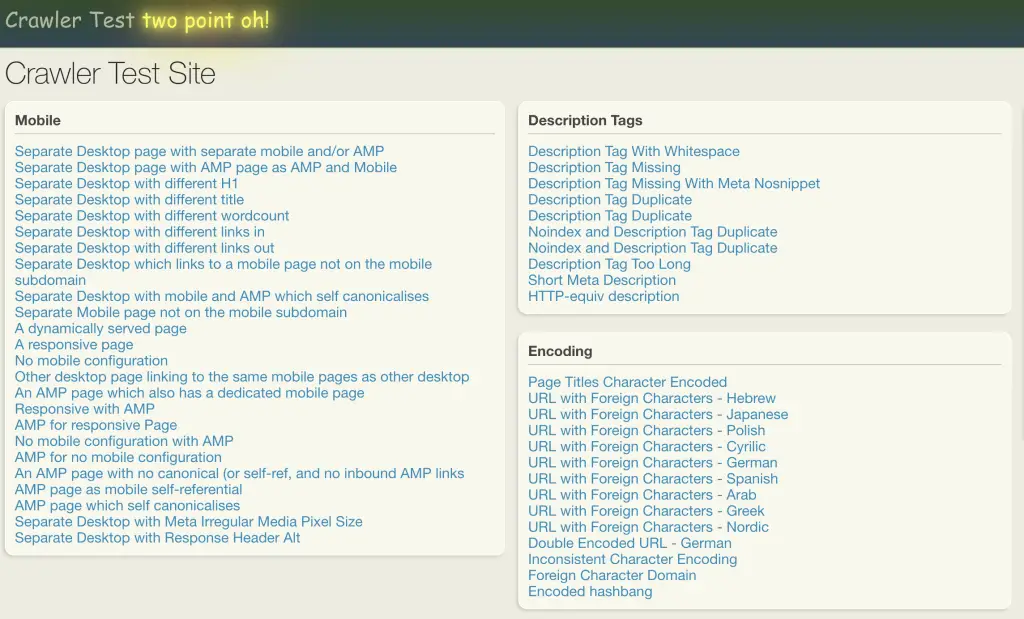
Scraping وب را در Crawler-test.com تمرین کنید
برای این آموزش، ما خراش دادن وب را با BeautifulSoup در یک وب سایت اسباب بازی که برای این منظور ایجاد شده است، تمرین می کنیم: crawler-test.com.

برای استخراج محتوا از یک صفحه وب، با استفاده از کتابخانه درخواستهای پایتون، یک درخواست HTTP به یک URL ایجاد کنید.
# Making an HTTP Request
import requests
url = 'https://crawler-test.com/'
response = requests.get(url)
print('Status code: ', response.status_code)
print('Text: ', response.text[:50])
تجزیه پاسخ با BeautifulSoup
برای تجزیه پاسخ با BeautifulSoup، HTML بازیابی شده را به عنوان آرگومان سازنده BeautifulSoup اضافه کنید.
هنگام واکشی یک صفحه وب با درخواست ها، شی پاسخ برگردانده می شود. از آن پاسخ، می توانید HTML صفحه را بازیابی کنید. آن HTML در یونیکد یا بایت (متن) ذخیره می شود.
قبلاً دیدهایم که چگونه این نمایش متنی HTML را با BeautifulSoup تجزیه کنیم. برای انجام این کار، تنها چیزی که نیاز داریم این است که answer.text را به کلاس BeautifulSoup منتقل کنیم.
from bs4 import BeautifulSoup
# Parse the HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Extract any HTML tag
soup.find('title')
<title>Crawler Test Site</title>
از BeautifulSoup’s استفاده کنید find() و find_all() روش هایی برای استخراج تگ های HTML از HTML تجزیه شده.
برخی از تگ های بسیار رایج HTML که می خواهید آنها را پاک کنید عبارتند از عنوان، h1 و پیوندها.
عناصر را بر اساس نام برچسب پیدا کنید
برای یافتن یک عنصر HTML با نام تگ آن در BeautifulSoup، نام تگ را به عنوان آرگومان به متد شی BeautifulSoup ارسال کنید.
در اینجا مثالی از نحوه استخراج این تگ ها با bs4 آورده شده است.
# Extracting HTML tags
title = soup.find('title')
h1 = soup.find('h1')
links = soup.find_all('a', href=True)
# Print the outputs
print('Title: ', title)
print('h1: ', h1)
print('Example link: ', links[1]['href'])
Title: <title>Crawler Test Site</title>
h1: <h1>Crawler Test Site</h1>
Example link: /mobile/separate_desktop
عناصر را با شناسه پیدا کنید
برای یافتن یک عنصر HTML با شناسه آن در BeautifulSoup، نام شناسه را به آن ارسال کنید id پارامتر متد find() شی سوپ.
<div id="header">
<a href="/" id="logo">Crawler Test <span class="neon-effect">two point oh!</span></a>
<div style="position:absolute;right:520px;top:-4px;"></div>
</div>
عناصر را بر اساس نام کلاس HTML پیدا کنید
برای پیدا کردن یک عنصر HTML بر اساس کلاس آن در BeautifulSoup، یک دیکشنری را به عنوان آرگومان شی سوپ ارسال کنید. find_all() روش.
soup.find_all('div', {'class': 'panel-header'})[0]
<div class="panel-header">
<h3>Mobile</h3>
</div>
سپس می توانید شی را حلقه کنید تا هر کاری که می خواهید انجام دهید.
# Find Elements by Class
boxes = soup.find_all('div', {'class': 'panel'})
box_names = []
for box in boxes:
title = box.find('h3')
box_names.append(title.text)
box_names[:5]
['Mobile', 'Description Tags', 'Encoding', 'Titles', 'Robots Protocol']
برای استخراج متن از یک عنصر HTML با استفاده از BeautifulSoup، از .text ویژگی روی شی سوپ اگر شیء یک لیست است (مثلاً با استفاده از find_all) از یک حلقه for برای تکرار هر عنصر استفاده کنید و از ویژگی text در هر عنصر استفاده کنید.
logo = soup.find('a', {'id': 'logo'})
logo.text
'Crawler Test two point oh!'
برای استخراج برچسب های HTML با استفاده از ویژگی های آنها، یک فرهنگ لغت را به آن ارسال کنید attrs پارامتر در متد find()
ویژگی های مثال عبارتند از name ویژگی مورد استفاده در توضیحات متا یا the href ویژگی مورد استفاده در یک هایپرلینک
برخی از عناصر HTML از شما می خواهند که عناصر را با استفاده از ویژگی آنها دریافت کنید.
در زیر، ما توضیحات متا و ویژگی های نام متا روبات ها را تجزیه می کنیم.
# Parsing using HTML tag attributes
description = soup.find('meta', attrs={'name':'description'})
meta_robots = soup.find('meta', attrs={'name':'robots'})
print('description: ',description)
print('meta robots: ',meta_robots)
description: <meta content="Default description XIbwNE7SSUJciq0/Jyty" name="description"/>
meta robots: None
در اینجا، عنصر متا روبات ها در دسترس نبود، و بنابراین بازگشت None.
بیایید ببینیم چگونه از برچسب های در دسترس مراقبت کنیم.
در زیر، توضیحات، رباتهای متا و تگهای متعارف را از صفحه وب حذف میکنیم. اگر آنها در دسترس نباشند، یک رشته خالی را برمی گردانیم.
# Conditional parsing
canonical = soup.find('link', {'rel': 'canonical'})
# Extract if attribute ifound
description = description['content'] if description else ''
meta_robots = meta_robots['content'] if meta_robots else ''
canonical = canonical['href'] if canonical else ''
# Print output
print('description: ', description)
print('meta_robots: ', meta_robots)
print('canonical: ', canonical)
description: Default description XIbwNE7SSUJciq0/Jyty
meta_robots:
canonical: برای استخراج تمام پیوندهای یک صفحه وب با BeautifulSoup، از soup.find_all() روش با "a" برچسب به عنوان آرگومان آن را تنظیم کنید href پارامتر به True.
soup.find_all('a', href=True)
استخراج پیوندها در یک صفحه وب مرتبط ترین چیزی است که باید در اسکراپینگ وب بدانید.
اکنون، ما یاد خواهیم گرفت که چگونه این کار را انجام دهیم.
علاوه بر این، ما یاد خواهیم گرفت که چگونه از روش urljoin از urllib برای غلبه بر یکی از رایج ترین چالش های ساخت یک خزنده وب استفاده کنیم: مراقبت از URL های نسبی و مطلق.
# Extract all links on the page
from urllib.parse import urlparse, urljoin
url = 'https://crawler-test.com/'
# Parse URL
parsed_url = urlparse(url)
domain = parsed_url.scheme + '://' + parsed_url.netloc
print('Domain root is: ', domain)
# Get href from all links
links = []
for link in soup.find_all('a', href=True):
# join domain to path
full_url = urljoin(domain, link['href'])
links.append(full_url)
# Print output
print('Top 5 links are :\n', links[:5])
Domain root is: https://crawler-test.com
Top 5 links are :
['https://crawler-test.com/', 'https://crawler-test.com/mobile/separate_desktop', 'https://crawler-test.com/mobile/desktop_with_AMP_as_mobile', 'https://crawler-test.com/mobile/separate_desktop_with_different_h1', 'https://crawler-test.com/mobile/separate_desktop_with_different_title']
برای استخراج یک عنصر در قسمت خاصی از صفحه (مثلاً با استفاده از id آن)، نتیجه یک ()soup.find را به متغیر دیگری اختصاص دهید و از یکی از متدهای داخلی bs4 روی آن شی استفاده کنید.
# Get div that contains a specific ID
subset = soup.find('div', {'id': 'idname'})
# Find all p inside that div
subset.find_all('p')
مثال:
# Extract all links on the page
from urllib.parse import urljoin
domain = 'https://crawler-test.com/'
# Get div that contains a specific ID
menu = soup.find('div', {'id': 'header'})
# Find all links within the div
menu_links = menu.find_all('a', href=True)
# Print output
for link in menu_links[:5]:
print(link['href'])
print(urljoin(domain, link['href']) )
/
https://crawler-test.com/
برچسب های خاص HTML را با BeautifulSoup حذف کنید
برای حذف یک تگ HTML خاص از یک سند HTML با BeautifulSoup، از decompose() روش.
soup.tag_name.decompose()
مثال
# Prompt
wikipedia_text = '''
<p>In the United States, website owners can use three major <a href="/wiki/Cause_of_action" title="Cause of action">legal claims</a> to prevent undesired web scraping: (1) copyright infringement (compilation), (2) violation of the <a href="/wiki/Computer_Fraud_and_Abuse_Act" title="Computer Fraud and Abuse Act">Computer Fraud and Abuse Act</a> ("CFAA"), and (3) <a href="/wiki/Trespass_to_chattels" title="Trespass to chattels">trespass to chattel</a>.<sup id="cite_ref-6" class="reference"><a href="#cite_note-6">[6]</a></sup> However, the effectiveness of these claims relies upon meeting various criteria...</p>'''
# Parse HTML
wiki_soup = BeautifulSoup(wikipedia_text, 'html.parser')
# Get first paragraph
par = wiki_soup.find_all('p')[0]
# Get all links
par.find_all('a')
# Remove references tags from wikipedia
par.sup.decompose()
par.find_all('a')
عناصر را بر اساس محتوای متن پیدا کنید
برای یافتن عناصر در HTML با استفاده از محتوای متنی، متنی را که باید مطابق با مقدار آن باشد، اضافه کنید string پارامتر داخل find_all() روش.
# Getting Elements using Text
soup = BeautifulSoup(r.text, 'html.parser')
soup.find_all('a',string="Description Tag Too Long")
[<a href="/description_tags/description_over_max">Description Tag Too Long</a>]
مشکل این است که رشته باید دقیقا مطابقت داشته باشد. بنابراین، استفاده از یک رشته جزئی برای تطبیق با BeautifulSoup هیچ چیزی را باز نمیگرداند:
# Getting Elements using Partial String
soup.find_all('a',string="Description")
کار در مورد این مشکل تطبیق رشته استفاده از توابع کاربردی یا استفاده از عبارات منظم با عبارت است string پارامتر. در ادامه به این دو موقعیت خواهیم پرداخت.
یک تابع را به روش BeautifulSoup اعمال کنید
برای اعمال تابعی در متد BeautifulSoup، تابع را به پارامتر رشته اضافه کنید find_all() روش.
# Apply function to BeautifulSoup
def find_a_string(value):
return lambda text: value in text
soup.find_all(string=find_a_string('Description Tag'))
['Description Tags',
'Description Tag With Whitespace',
'Description Tag Missing',
'Description Tag Missing With Meta Nosnippet',
'Description Tag Duplicate',
'Description Tag Duplicate',
'Noindex and Description Tag Duplicate',
'Noindex and Description Tag Duplicate',
'Description Tag Too Long']
تجزیه صفحه HTML با عبارات منظم در BeautifulSoup
برای استفاده از عبارات منظم برای تجزیه یک صفحه HTML با BeautifulSoup، وارد کنید re ماژول، و اختصاص a re.compile() شیء به پارامتر رشته از find_all() روش.
from bs4 import BeautifulSoup
import re
# Parse using regex
soup = BeautifulSoup(r.text, 'html.parser')
soup.find_all(string=re.compile('Description Tag'))
['Description Tags',
'Description Tag With Whitespace',
'Description Tag Missing',
'Description Tag Missing With Meta Nosnippet',
'Description Tag Duplicate',
'Description Tag Duplicate',
'Noindex and Description Tag Duplicate',
'Noindex and Description Tag Duplicate',
'Description Tag Too Long']
نحوه استفاده از XPath با BeautifulSoup (lxml)
برای استفاده از XPath برای استخراج عناصر از یک سند HTML با BeautifulSoup، باید کتابخانه پایتون lxml را نصب کنید زیرا Beautiful از عبارات XPath پشتیبانی نمی کند.
from lxml import html
# Parse HTML with XPath
content = html.fromstring(r.content)
panels = content.xpath('//*[@class="panel-header"]')
# get text from tags
[panel.find('h3').text for panel in panels][:5]
والدین، فرزندان و خواهران و برادران یک عنصر HTML را پیدا کنید
BeautifulSoup یک درخت تجزیه را برمیگرداند که میتوانید از طریق هر یک از والدین، فرزند و خواهر و برادر در درخت حرکت کنید تا عناصر مورد نظر خود را پیدا کنید.
والد(های) یک عنصر HTML را پیدا کنید
برای پیدا کردن والد تک عنصر HTML، از عبارت استفاده کنید find_parent() روشی که عنصر مورد نظر و همچنین والد آن را در درخت HTML به شما نشان می دهد.
a_child = soup.find_all('a')[0]
a_child.find_parent()
<div id="header">
<a href="/" id="logo">Crawler Test <span class="neon-effect">two point oh!</span></a>
<div style="position:absolute;right:520px;top:-4px;"></div>
</div>
برای پیدا کردن تمام والدین یک عنصر HTML، از عبارت استفاده کنید find_parents() متد روی شی BeautifulSoup.
فرزند (فرزندان) یک عنصر HTML را پیدا کنید
برای پیدا کردن یک فرزند از یک عنصر HTML، از عبارت استفاده کنید findChild() روشی که فرزند عنصر در درخت HTML را به شما نشان می دهد.
a_child = soup.find_all('a')[0]
a_child.findChild()
<span class="neon-effect">two point oh!</span>
برای پیدا کردن تمام فرزندان یک عنصر HTML، از عبارت استفاده کنید fetchChildren() متد روی شی BeautifulSoup.
a_child.findChildren()
#or
list(a_child.children)
همه نوادگان عنصر HTML را پیدا کنید.
list(a_child.descendants)
خواهر و برادر (های) یک عنصر HTML را پیدا کنید
برای پیدا کردن خواهر و برادر بعدی بعد از یک عنصر HTML، از find_next_sibling() روشی که خواهر و برادر بعدی را در درخت HTML به شما نشان می دهد.
a_child = soup.find_all('a')[0]
a_child.find_next_sibling()
a_child.find_next_siblings()
<div style="position:absolute;right:520px;top:-4px;"></div>
جایی که این از آنجا می آید این است که اگر عنصر والد را بگیرید:
a_parent = soup.find('div',{'id':'header'})
a_parent
شما HTML عنصر را دریافت میکنید، و برادر بعدی تگ را دریافت میکنید، که div برجسته شده (و نتیجه نشان داده شده در قبل) است.
<div id="header">
<a href="/" id="logo">Crawler Test <span class="neon-effect">two point oh!</span></a>
<div style="position:absolute;right:520px;top:-4px;"></div>
</div>
به طور مشابه، می توانید خواهر و برادر قبلی را نیز پیدا کنید.
a_child. find_previous_sibling()
a_child. find_previous_siblings()
برای پیدا کردن تمام والدین یک عنصر HTML، از عبارت استفاده کنید find_parents() متد روی شی BeautifulSoup.
HTML شکسته را با BeautifulSoup رفع کنید
با BeautifulSoup، میتوانید HTML شکسته را بگیرید و قسمتهای گمشده را با استفاده از آن تکمیل کنید prettify() متد روی شی BeautifulSoup.
# Fix Broken HTML with BeautifulSoup
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Incomplete Broken <span>HTML<</p>")
print(soup.prettify())
<html>
<body>
<p>
Incomplete Broken
<span>
HTML
</span>
</p>
</body>
</html>
مقالات مرتبط با وب اسکرپینگ
نتیجه
ما همه چیزهایی را که احتمالاً میتوانید در مورد خراش دادن وب با BeautifulSoup بدانید، پوشش دادهایم. موفق باشید!

استراتژیست سئو در Tripadvisor، Seek سابق (ملبورن، استرالیا). متخصص در سئو فنی. در تلاش برای سئوی برنامهریزی شده برای سازمانهای بزرگ از طریق استفاده از پایتون، R و یادگیری ماشین.