
نوامبر گذشته، ابتکار 1000 زبان را اعلام کردیم، تعهدی بلندپروازانه برای ساختن یک مدل یادگیری ماشینی (ML) که از هزار زبان پرتکلم دنیا پشتیبانی میکند و مشارکت بیشتری را برای میلیاردها نفر در سراسر جهان به ارمغان میآورد. با این حال، برخی از این زبانها توسط کمتر از بیست میلیون نفر صحبت میشوند، بنابراین یک چالش اصلی نحوه پشتیبانی از زبانهایی است که گویشوران نسبتاً کمی یا دادههای موجود محدودی برای آنها وجود دارد.
امروز، ما مشتاق هستیم که اطلاعات بیشتری را در مورد مدل گفتار جهانی (USM) به اشتراک بگذاریم، اولین گام حیاتی برای پشتیبانی از 1000 زبان. USM خانواده ای از پیشرفته ترین مدل های گفتار با پارامترهای 2B است که بر روی 12 میلیون ساعت گفتار و 28 میلیارد جمله متن آموزش داده شده است که بیش از 300 زبان را در بر می گیرد. USM، که برای استفاده در YouTube (مثلاً برای زیرنویسهای بسته) است، میتواند تشخیص خودکار گفتار (ASR) را نه تنها در زبانهای پرمخاطب مانند انگلیسی و ماندارین، بلکه در زبانهای فاقد منابع مانند آمهری، سبوانو، آسامی، انجام دهد. و آذربایجانی به نام چند. در «Google USM: مقیاس تشخیص خودکار گفتار فراتر از 100 زبان»، نشان میدهیم که استفاده از مجموعه دادههای چندزبانه بدون برچسب بزرگ برای آموزش از قبل رمزگذار مدل و تنظیم دقیق روی مجموعه کوچکتری از دادههای برچسبگذاری شده، ما را قادر میسازد تا موارد زیر را تشخیص دهیم. زبان ها. علاوه بر این، فرآیند آموزش مدل ما در سازگاری با زبانها و دادههای جدید مؤثر است.
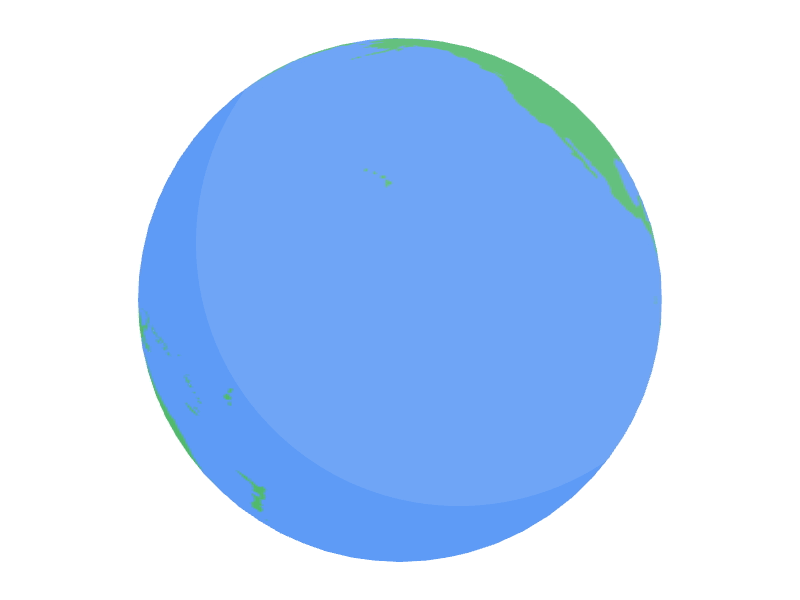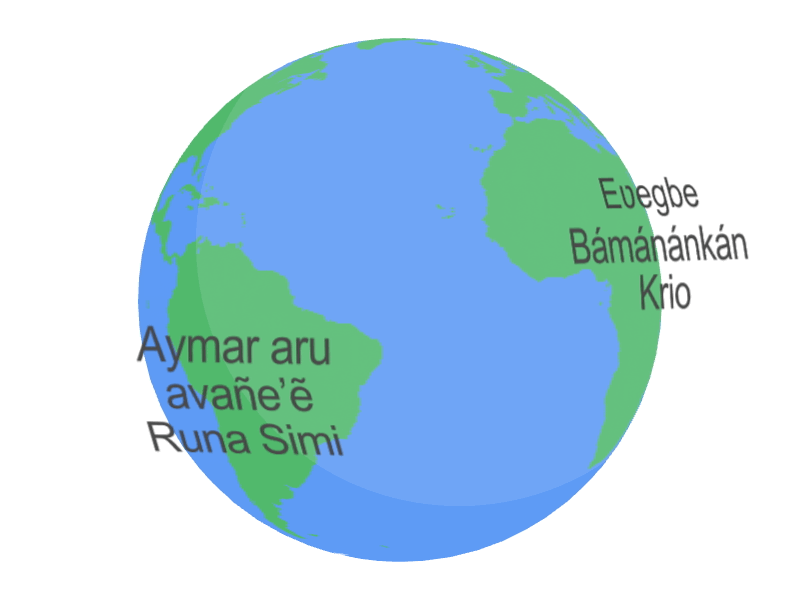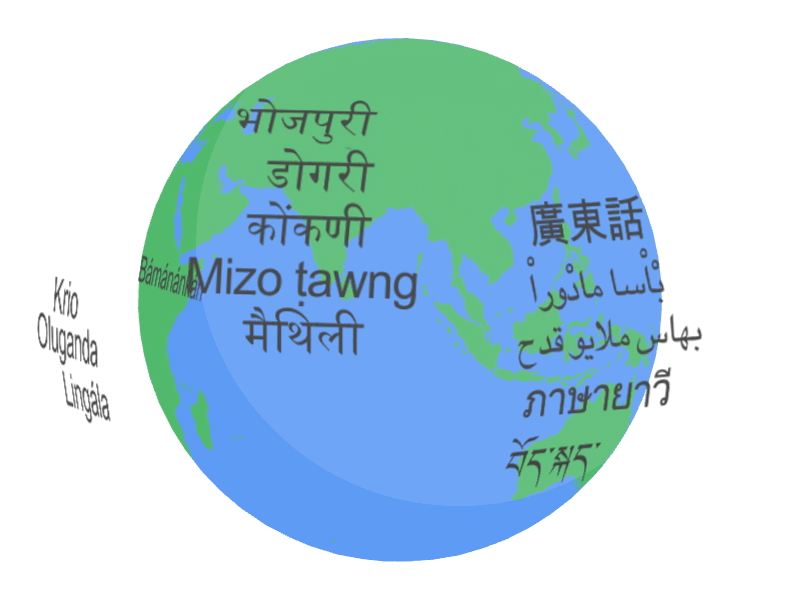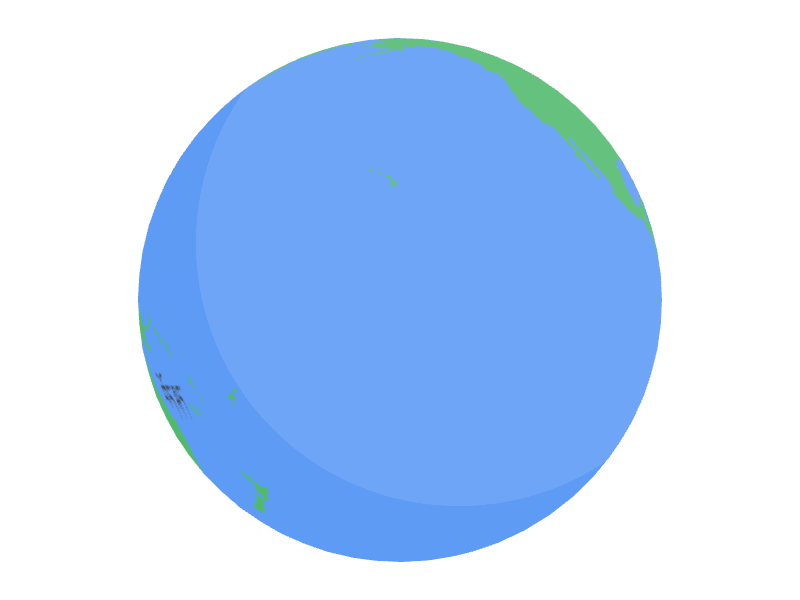 |
| نمونه ای از زبان هایی که USM پشتیبانی می کند. |
چالش های موجود در ASR فعلی
برای دستیابی به این هدف بلندپروازانه، باید به دو چالش مهم در ASR بپردازیم.
اول، عدم مقیاس پذیری با رویکردهای یادگیری نظارت شده مرسوم وجود دارد. یکی از چالشهای اساسی مقیاسبندی فناوریهای گفتاری به بسیاری از زبانها، دستیابی به دادههای کافی برای آموزش مدلهای با کیفیت بالا است. با روشهای مرسوم، دادههای صوتی باید یا به صورت دستی برچسبگذاری شوند، که زمانبر و پرهزینه است، یا از منابعی با رونویسیهای از پیش موجود جمعآوری شوند، که یافتن آنها برای زبانهایی که بازنمایی گستردهای ندارند، دشوارتر است. در مقابل، یادگیری خود نظارتی میتواند از دادههای فقط صوتی استفاده کند، که در مقادیر بسیار بیشتری در زبانها موجود است. این امر خود نظارتی را به رویکرد بهتری برای دستیابی به هدف ما در مقیاس دهی در صدها زبان تبدیل می کند.
چالش دیگر این است که مدل ها باید به شیوه ای محاسباتی کارآمد بهبود یابند در حالی که ما پوشش و کیفیت زبان را گسترش می دهیم. این امر مستلزم آن است که الگوریتم یادگیری انعطاف پذیر، کارآمد و قابل تعمیم باشد. به طور خاص، چنین الگوریتمی باید بتواند از مقادیر زیادی داده از منابع مختلف استفاده کند، به روز رسانی مدل را بدون نیاز به بازآموزی کامل فعال کند، و به زبان های جدید و موارد استفاده تعمیم دهد.
رویکرد ما: یادگیری خود نظارتی با تنظیم دقیق
USM از معماری رمزگذار-رمزگشای استاندارد استفاده می کند، جایی که رمزگشا می تواند CTC، RNN-T یا LAS باشد. برای رمزگذار، USM از Conformer یا ترانسفورماتور کانولوشن افزوده استفاده می کند. جزء کلیدی Conformer بلوک Conformer است که از ماژول های توجه، پیشخور و کانولوشن تشکیل شده است. طیفنگار log-mel سیگنال گفتار را به عنوان ورودی میگیرد و یک نمونهگیری فرعی کانولوشن انجام میدهد، پس از آن یک سری بلوک Conformer و یک لایه طرحریزی برای به دست آوردن جاسازیهای نهایی اعمال میشود.
خط لوله آموزشی ما با اولین گام یادگیری خود نظارتی بر روی صدای گفتاری که صدها زبان را پوشش می دهد شروع می شود. در مرحله دوم اختیاری، کیفیت و پوشش زبان مدل را می توان از طریق یک مرحله قبل از آموزش اضافی با داده های متنی بهبود بخشید. تصمیم برای ترکیب مرحله دوم بستگی به در دسترس بودن داده های متنی دارد. USM با این مرحله دوم اختیاری بهترین عملکرد را دارد. آخرین مرحله خط لوله آموزشی، تنظیم دقیق وظایف پایین دستی (مانند ASR یا ترجمه خودکار گفتار) با مقدار کمی از داده های نظارت شده است.
برای اولین قدم، ما از BEST-RQ استفاده میکنیم، که قبلاً نتایج پیشرفتهای را در کارهای چند زبانه نشان داده است و ثابت کرده است که هنگام استفاده از مقادیر بسیار زیاد دادههای صوتی بدون نظارت، کارآمد است.
در مرحله دوم (اختیاری)، از پیش آموزش نظارت شده چند هدفه برای ترکیب دانش از داده های متنی اضافی استفاده کردیم. این مدل یک ماژول رمزگذار اضافی را برای دریافت متن به عنوان ورودی و لایههای اضافی برای ترکیب خروجی رمزگذار گفتار و رمزگذار متن معرفی میکند و مدل را به طور مشترک روی گفتار بدون برچسب، گفتار برچسبگذاری شده و دادههای متن آموزش میدهد.
در آخرین مرحله، USM بر روی وظایف پایین دستی تنظیم شده است. خط لوله آموزشی کلی در زیر نشان داده شده است. با دانش به دست آمده در طول آموزش، مدل های USM تنها با مقدار کمی از داده های نظارت شده از وظایف پایین دستی به کیفیت خوبی دست می یابند.
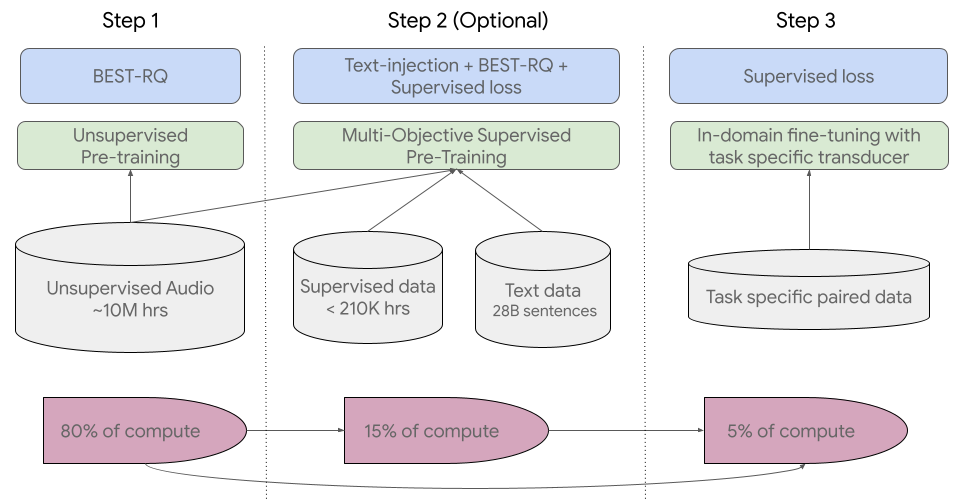 |
| خط لوله آموزشی کلی USM. |
نتایج کلیدی
عملکرد در چندین زبان در زیرنویسهای YouTube
رمزگذار ما بیش از 300 زبان را از طریق قبل از آموزش ترکیب می کند. ما کارآمدی رمزگذار از پیش آموزشدیده را از طریق تنظیم دقیق دادههای گفتاری چند زبانه YouTube Caption نشان میدهیم. داده های YouTube تحت نظارت شامل 73 زبان است و به طور متوسط کمتر از سه هزار ساعت داده در هر زبان دارد. با وجود دادههای محدود نظارت شده، این مدل به طور متوسط در 73 زبان به کمتر از 30 درصد نرخ خطای کلمه (WER؛ کمتر بهتر است) دست مییابد، نقطه عطفی که قبلاً هرگز به آن دست نیافتهایم. برای en-US، USM دارای 6 درصد WER نسبی کمتر در مقایسه با مدل فعلی داخلی است. در نهایت، ما با مدل بزرگ اخیرا منتشر شده، Whisper (large-v2) مقایسه میکنیم که با بیش از 400 هزار ساعت داده برچسبگذاری شده آموزش داده شده است. برای مقایسه، ما فقط از 18 زبانی استفاده می کنیم که Whisper می تواند با موفقیت کمتر از 40٪ WER رمزگشایی کند. مدل ما به طور متوسط 32.7% WER کمتری نسبت به Whisper برای این 18 زبان دارد.
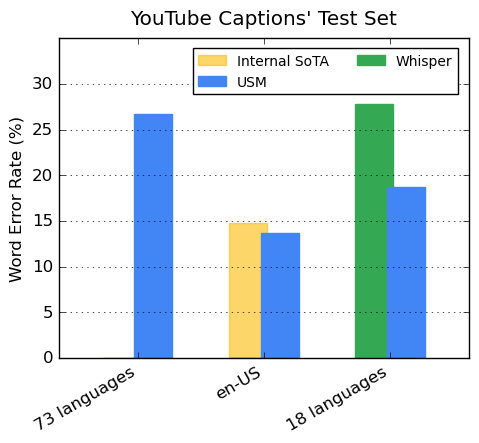 |
| USM از همه 73 زبان موجود در مجموعه آزمایشی شرحهای YouTube پشتیبانی میکند و از Whisper در زبانهایی که میتواند با کمتر از 40٪ WER پشتیبانی کند، بهتر است. WER پایین تر بهتر است. |
تعمیم به وظایف ASR پایین دست
در مجموعه دادههای در دسترس عموم، مدل ما WER کمتری را در مقایسه با Whisper on CORAAL (انگلیسی بومی آفریقایی آمریکایی)، SpeechStew (en-US) و FLEURS (102 زبان) نشان میدهد. مدل ما WER کمتری را با و بدون آموزش روی دادههای درون دامنه به دست میآورد. مقایسه در FLEURS زیرمجموعه زبانها (62) را گزارش میکند که با زبانهای پشتیبانی شده توسط مدل Whisper همپوشانی دارند. برای FLEURS، USM بدون دادههای درون دامنه دارای 65.8 درصد WER نسبی کمتر در مقایسه با Whisper است و دارای 67.8 درصد WER نسبی کمتر با دادههای درون دامنه است.
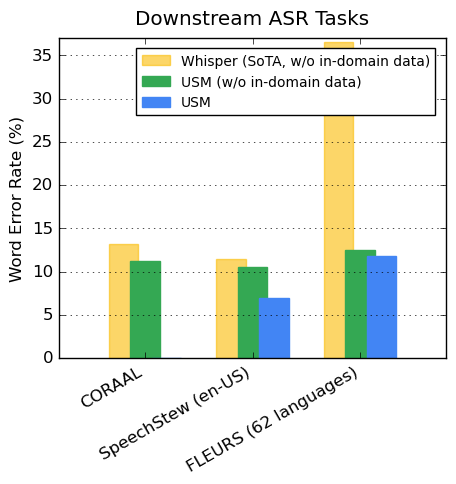 |
| مقایسه USM (با یا بدون داده های درون دامنه) و نتایج Whisper در معیارهای ASR. WER پایین تر بهتر است. |
عملکرد ترجمه خودکار گفتار (AST)
برای ترجمه گفتار، USM را روی مجموعه داده CoVoST تنظیم می کنیم. مدل ما، که شامل متن از طریق مرحله دوم خط لوله ما است، با داده های نظارت محدود به کیفیتی پیشرفته دست می یابد. برای ارزیابی وسعت عملکرد مدل، زبانها را از مجموعه داده CoVoST به بالا، متوسط و پایین بر اساس در دسترس بودن منابع تقسیم میکنیم و امتیاز BLEU (بالاتر بهتر) را برای هر بخش محاسبه میکنیم. همانطور که در زیر نشان داده شده است، USM از Whisper برای همه بخش ها بهتر است.
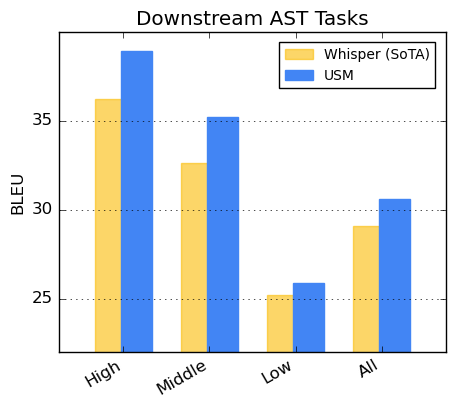 |
| امتیاز CoVoST BLEU. BLEU بالاتر بهتر است. |
به سوی 1000 زبان
توسعه USM تلاشی حیاتی در جهت تحقق مأموریت Google برای سازماندهی اطلاعات جهان و در دسترس قرار دادن آن در سطح جهانی است. ما بر این باوریم که معماری مدل پایه و خط لوله آموزشی USM پایهای را تشکیل میدهد که میتوانیم براساس آن مدلسازی گفتار را به 1000 زبان بعدی گسترش دهیم.
بیشتر بدانید
مقاله ما را اینجا بررسی کنید. محققان میتوانند از اینجا درخواست دسترسی به USM API کنند.
سپاسگزاریها
ما از همه نویسندگان برای همکاری در پروژه و مقاله، از جمله اندرو روزنبرگ، انکور باپنا تشکر می کنیم.، بووانا رامابهادران، بو لی، چونگ چنگ چیو، دانیل پارک، فرانسیس بیوفیس، هاگن سولتاو، گری وانگ، جینجر پرنگ، جیمز کین، جیسون ریسا، یوهان شالکویک، که هو، نانشین چن، پریسا هاگانی، پدرو مورنو منگیبار، روهیت پرابهاوالکار ، تارا سایناث، تروور استروهمن، ورا اکسلرود، وی هان، یونگهوی وو، یونگ کیانگ وانگ، یو ژانگ، ژهوای چن، و ژونگ منگ.
همچنین از الکسیس کونیو، مین ما، شیخار بهارادواج، سید دالمیا، جیاهوی یو، جیان چنگ، پل روبنشتاین، یه جیا، جاستین اسنایدر، وینسنت تسانگ، یوانژونگ ژو، تائو وانگ برای بحث های مفید تشکر می کنیم.
ما از بازخورد و حمایت ارزشمند الی کالینز، جف دین، سیسی هسیائو، زوبین قهرمانی قدردانی می کنیم. با تشکر ویژه از آستین تارانگو، لارا تومه، آمنا لطیف و جیسون پورتا برای راهنماییهایشان در مورد تمرینهای هوش مصنوعی مسئول. از الیزابت ادکیسون، جیمز کوکریل برای کمک به نامگذاری مدل، تام اسمال برای گرافیک متحرک، آبیشک باپنا برای پشتیبانی ویرایشی و اریکا موریرا برای مدیریت منابع تشکر میکنیم. ما از انوشا رامش برای بازخورد، راهنمایی و کمک در مورد استراتژی انتشار، و Calum Barnes و Salem Haykal برای همکاری ارزشمندشان تشکر می کنیم.