ساخت مدل هایی که مجموعه متنوعی از وظایف را حل می کنند به یک پارادایم غالب در حوزه بینایی و زبان تبدیل شده است. در پردازش زبان طبیعی، مدل های بزرگ از پیش آموزش دیده، مانند PaLM، GPT-3 و Gopher، یادگیری صفر شات قابل توجهی از وظایف زبانی جدید را نشان داده اند. به طور مشابه، در بینایی کامپیوتر، مدل هایی مانند CLIP و Flamingo عملکرد قوی در طبقه بندی شات صفر و تشخیص اشیا نشان داده اند. گام بعدی طبیعی استفاده از چنین ابزارهایی برای ساخت عواملی است که می توانند وظایف تصمیم گیری مختلف را در بسیاری از محیط ها تکمیل کنند.
با این حال، آموزش چنین عواملی با چالش ذاتی تنوع محیطی مواجه است، زیرا محیط های مختلف با فضاهای عمل حالت متمایز عمل می کنند (به عنوان مثال، فضای مشترک و کنترل های مداوم در MuJoCo اساساً با فضای تصویر و اقدامات گسسته در Atari متفاوت است). این تنوع محیطی مانع به اشتراک گذاری دانش، یادگیری و تعمیم در بین وظایف و محیط ها می شود. بعلاوه، ایجاد توابع پاداش در میان محیطها دشوار است، زیرا وظایف مختلف عموماً مفاهیم متفاوتی از موفقیت دارند.
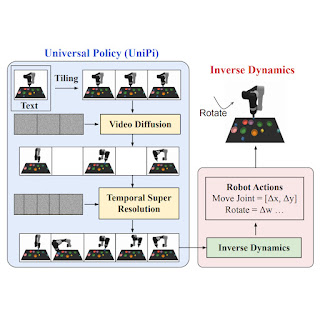
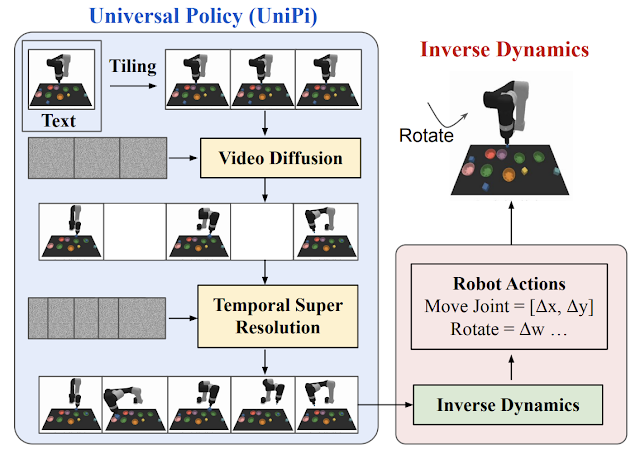
در «یادگیری سیاستهای جهانی از طریق تولید ویدیوی هدایتشده با متن»، ما یک خطمشی جهانی (UniPi) را پیشنهاد میکنیم که به تنوع محیطی و چالشهای تعیین پاداش میپردازد. UniPi از متن برای بیان شرح وظایف و ویدیو (یعنی توالی تصویر) به عنوان یک رابط جهانی برای انتقال کنش و رفتار مشاهده در محیط های مختلف استفاده می کند. با توجه به یک قاب تصویر ورودی جفت شده با متنی که هدف فعلی را توصیف می کند (یعنی مرحله سطح بالا بعدی)، UniPi از یک تولید کننده ویدیوی جدید (برنامه ریز مسیر) برای تولید ویدیو با تکه هایی از اینکه مسیر یک عامل برای رسیدن به آن هدف چگونه باید باشد استفاده می کند. . ویدئوی تولید شده به یک مدل دینامیک معکوس داده میشود که اقدامات کنترلی سطح پایین زیرین را استخراج میکند، که سپس در شبیهسازی یا توسط یک عامل ربات واقعی اجرا میشوند. ما نشان میدهیم که UniPi استفاده از زبان و ویدیو را بهعنوان یک رابط کنترل جهانی برای تعمیم به اهداف و وظایف جدید در محیطهای مختلف فعال میکند.
 |
| سیاست های ویدیویی تولید شده توسط UniPi. |
 |
| UniPi ممکن است برای تنظیمات چند وظیفه ای پایین دستی که به تعمیم زبان ترکیبی، برنامه ریزی افق بلند یا دانش در مقیاس اینترنت نیاز دارند، اعمال شود. در مثال پایین، UniPi تصویر بازوی ربات سفید را از اینترنت می گیرد و بر اساس توضیحات متنی هدف، قطعه های ویدئویی تولید می کند. |
پیاده سازی UniPi
برای تولید یک طرح معتبر و قابل اجرا، یک مدل متن به ویدئو باید یک پلان ویدئویی محدود را با شروع تصویر مشاهدهشده فعلی ترکیب کند. ما دریافتیم که با ارائه اولین فریم هر ویدیو به عنوان زمینه شرطی سازی صریح، محدود کردن صریح مدل سنتز ویدیو در طول آموزش (بر خلاف محدود کردن ویدیوها در زمان نمونهبرداری) مؤثرتر است.
در سطح بالا، UniPi دارای چهار مؤلفه اصلی است: 1) تولید ویدیوی سازگار با کاشی کاری فریم اول، 2) برنامه ریزی سلسله مراتبی از طریق وضوح فوق العاده زمانی، 3) ترکیب رفتار انعطاف پذیر، و 4) انطباق اقدام خاص. پیاده سازی و مزایای هر جزء را در زیر به تفصیل توضیح می دهیم.
تولید ویدئو از طریق کاشی کاری
مدلهای تبدیل متن به ویدیوی موجود مانند Imagen معمولاً فیلمهایی را تولید میکنند که در آن وضعیت محیط زیربنایی در طول مدت زمان تغییر قابل توجهی میکند. برای ساختن یک برنامه ریز مسیر دقیق، مهم است که محیط در تمام نقاط زمانی ثابت بماند. ما با ارائه تصویر مشاهده شده به عنوان زمینه اضافی هنگام حذف نویز هر فریم در ویدیوی سنتز شده، سازگاری محیط را در سنتز ویدیوی شرطی اعمال می کنیم. برای دستیابی به شرطیسازی زمینه، UniPi مستقیماً هر فریم میانی نمونهبرداری شده از نویز را با تصویر مشاهدهشده شرطی در سراسر مراحل نمونهگیری به هم پیوند میدهد، که به عنوان یک سیگنال قوی برای حفظ وضعیت محیط زیربنایی در طول زمان عمل میکند.
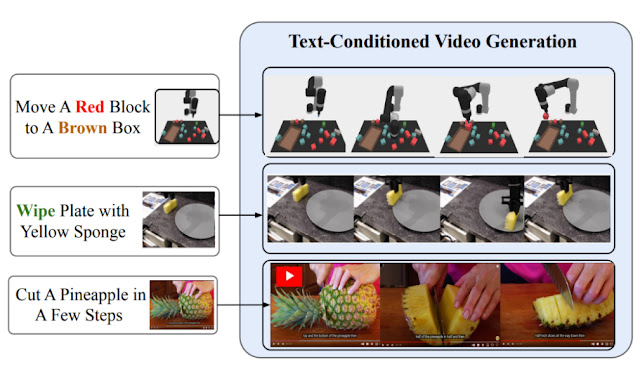 |
| تولید ویدئوی مشروط متنی، UniPi را قادر میسازد تا سیاستهای هدف کلی را در طیف گستردهای از منابع داده (روباتهای شبیهسازیشده، واقعی و YouTube) آموزش دهد. |
برنامه ریزی سلسله مراتبی
هنگام ساختن طرحها در محیطهای با ابعاد بالا با افقهای زمانی طولانی، ایجاد مستقیم مجموعهای از اقدامات برای رسیدن به یک حالت هدف به سرعت به دلیل رشد تصاعدی فضای جستجوی زیربنایی با طولانیتر شدن طرح، غیرقابل حل میشود. روش های برنامه ریزی اغلب این موضوع را با اعمال یک سلسله مراتب طبیعی در برنامه ریزی دور می زند. به طور خاص، روشهای برنامهریزی ابتدا طرحهای درشتی را میسازند (قابهای کلیدی میانی که در طول زمان پخش میشوند) که بر روی حالات و اقدامات کمبعد عمل میکنند، که سپس به طرحهایی در فضاهای حالت و عمل زیربنایی تبدیل میشوند.
مشابه برنامه ریزی، روش تولید ویدیوی مشروط ما یک سلسله مراتب زمانی طبیعی را نشان می دهد. UniPi ابتدا با نمونه برداری پراکنده از فیلم ها (“انتزاعات”) از رفتار عامل مورد نظر در امتداد محور زمان، ویدئوها را در سطحی درشت تولید می کند. سپس UniPi ویدیوها را برای نشان دادن رفتار معتبر در محیط با حل فوق العاده ویدیوها در طول زمان اصلاح می کند. در همین حال، وضوح فوق العاده درشت به ریز، سازگاری را از طریق درون یابی بین فریم ها بهبود می بخشد.
 |
| با توجه به مشاهده ورودی و دستورالعمل متنی، مجموعه ای از تصاویر را که رفتار عامل را نشان می دهد، برنامه ریزی می کنیم. تصاویر با استفاده از مدل دینامیک معکوس به کنش تبدیل می شوند. |
مدولاسیون رفتاری انعطاف پذیر
هنگام برنامهریزی دنبالهای از اقدامات برای یک هدف فرعی، میتوان به آسانی محدودیتهای خارجی را برای تعدیل یک برنامه تولید شده گنجاند. چنین انطباق زمان آزمون را می توان با ترکیب کردن ویژگی های احتمالی قبلی طرح مورد نظر برای تعیین محدودیت های مورد نظر در مسیر حرکت سنتز شده، که با UniPi نیز سازگار است، پیاده سازی کرد. به طور خاص، پیشین را میتوان با استفاده از طبقهبندیکننده آموختهشده روی تصاویر برای بهینهسازی یک کار خاص، یا به عنوان توزیع دلتای دیراک روی یک تصویر خاص برای هدایت یک طرح به سمت مجموعهای از حالتها مشخص کرد. برای آموزش مدل تولید ویدئوی مشروط متن، از الگوریتم انتشار ویدئو استفاده میکنیم، جایی که ویژگیهای زبان از پیش آموزشدیده از مبدل انتقال متن به متن (T5) کدگذاری میشوند.
انطباق اقدام ویژه کار
با توجه به مجموعهای از ویدیوهای ترکیبشده، ما یک مدل دینامیک معکوس مختص کار کوچک را آموزش میدهیم تا فریمها را به مجموعهای از اقدامات کنترلی سطح پایین ترجمه کنیم. این مستقل از برنامه ریز است و می تواند روی یک مجموعه داده جداگانه، کوچکتر و بالقوه کمتر از حد بهینه تولید شده توسط یک شبیه ساز انجام شود.
با توجه به چارچوب ورودی و توصیف متن هدف فعلی، مدل دینامیک معکوس فریمهای تصویر را ترکیب میکند و یک توالی کنش کنترلی ایجاد میکند که اقدامات آینده مربوطه را پیشبینی میکند. سپس یک عامل اقدامات کنترلی سطح پایین استنباط شده را از طریق کنترل حلقه بسته اجرا می کند.
قابلیت ها و ارزیابی UniPi
ما میزان موفقیت کار را بر روی اهداف مبتنی بر زبان جدید اندازهگیری میکنیم و متوجه میشویم که UniPi به خوبی به ترکیبهای دیده شده و جدید از اعلانهای زبان تعمیم مییابد، در مقایسه با خطوط پایه مانند Transformer BC، Trajectory Transformer (TT) و Diffuser.
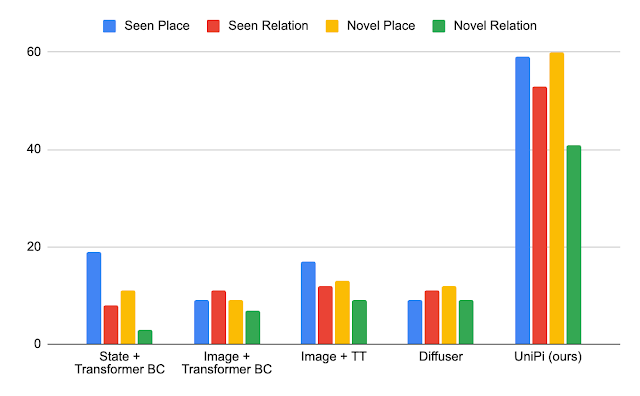 |
| UniPi به خوبی به ترکیبات دیده شده و جدید از دستورهای زبان در وظایف Place (مثلاً «محل X در Y») و Relation (مثلاً «محل X در سمت چپ Y») تعمیم میدهد. |
در زیر، ویدیوهای تولید شده در ترکیبات دیده نشده از اهداف را نشان می دهیم. UniPi قادر است مجموعه متنوعی از رفتارها را ترکیب کند که اهداف فرعی زبان را برآورده کند:
 |
| ویدیوهایی برای اهداف زبانی دیده نشده در زمان آزمون ایجاد شده است. |
انتقال چند محیطی
ما میزان موفقیت تکلیف UniPi و خطوط پایه را بر روی کارهای جدیدی که در طول آموزش دیده نمیشوند، اندازهگیری میکنیم. UniPi دوباره با یک حاشیه بزرگ از خطوط پایه بهتر عمل می کند:
 |
| UniPi زمانی که در مجموعه ای از محیط های چند وظیفه ای مختلف آموزش داده می شود، به خوبی به محیط های جدید تعمیم می یابد. |
در زیر، ویدیوهای تولید شده را در مورد کارهای دیده نشده نشان می دهیم. UniPi قادر است مجموعهای از رفتارهای متنوعی را که وظایف زبانی نادیده را برآورده میکنند ترکیب کند:
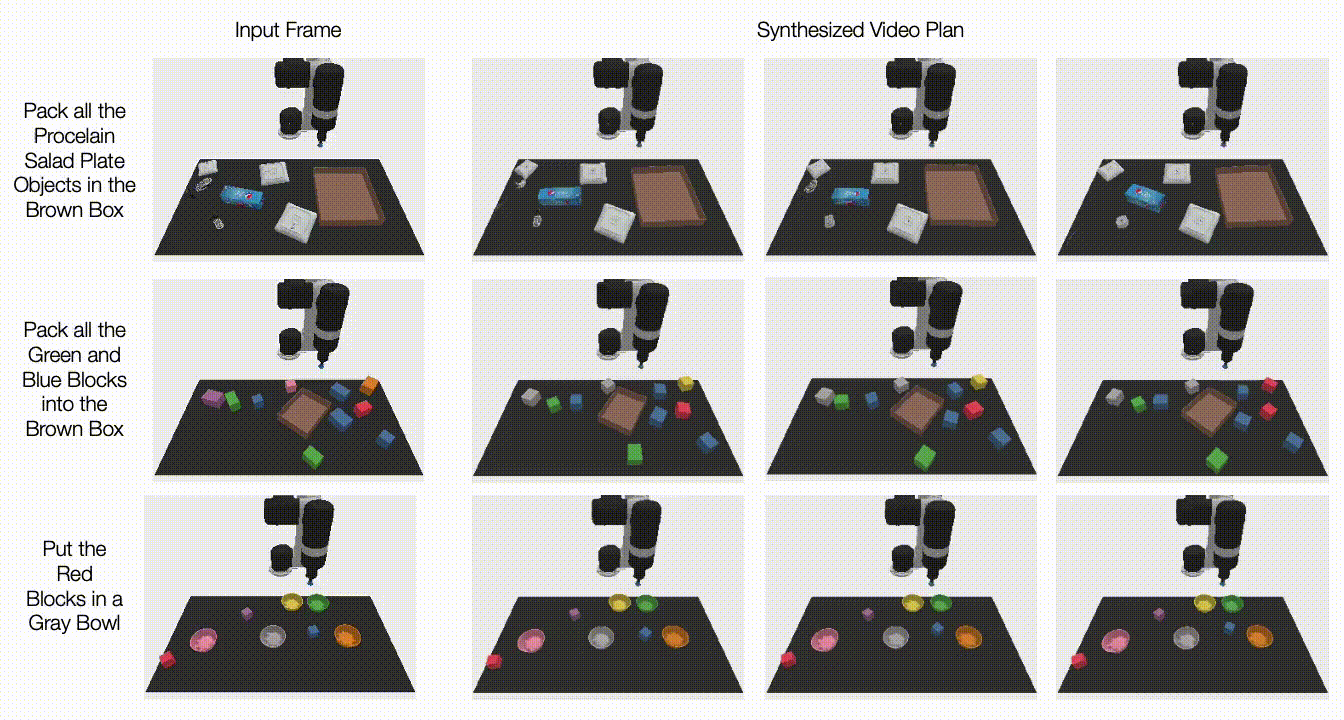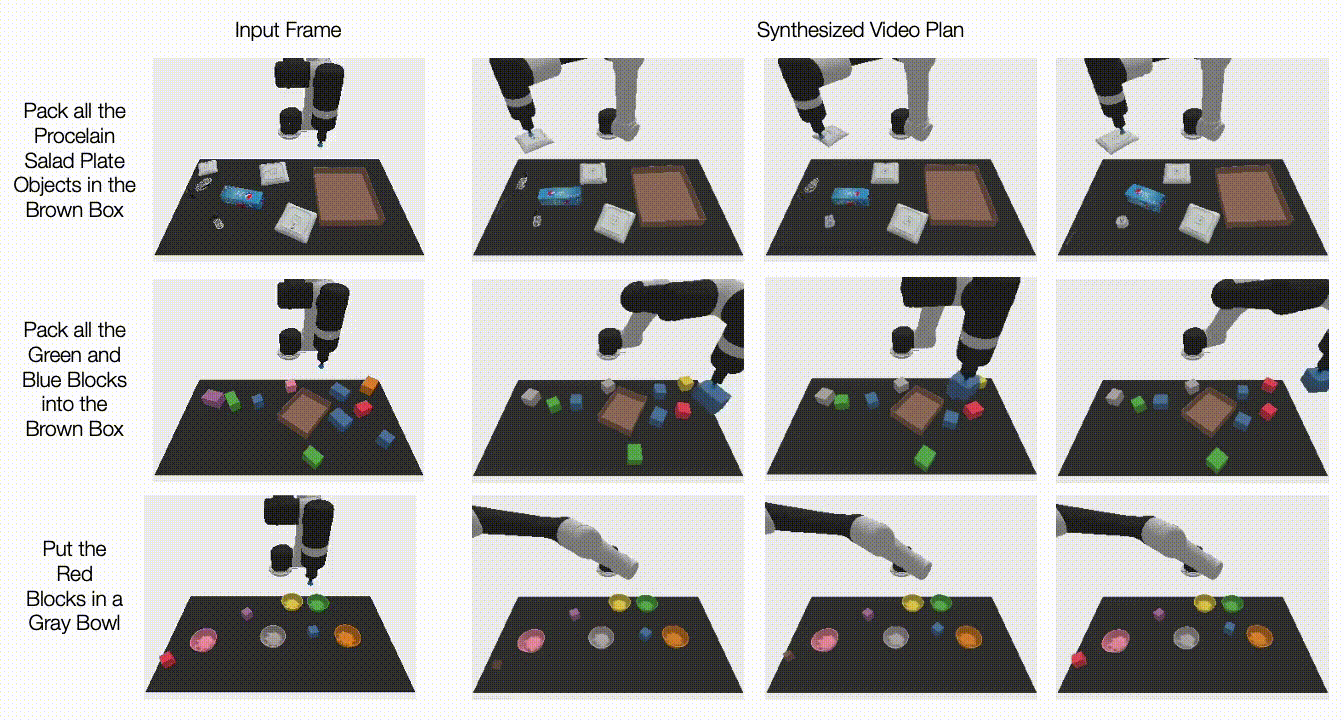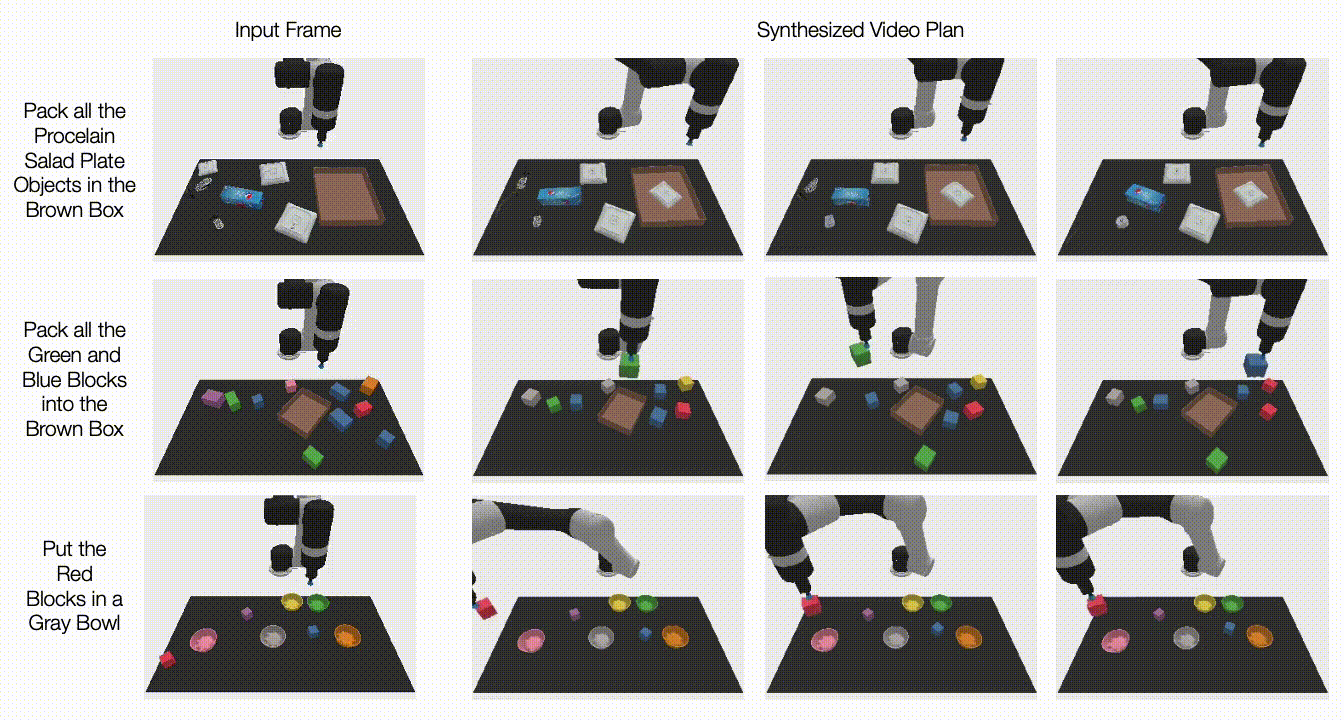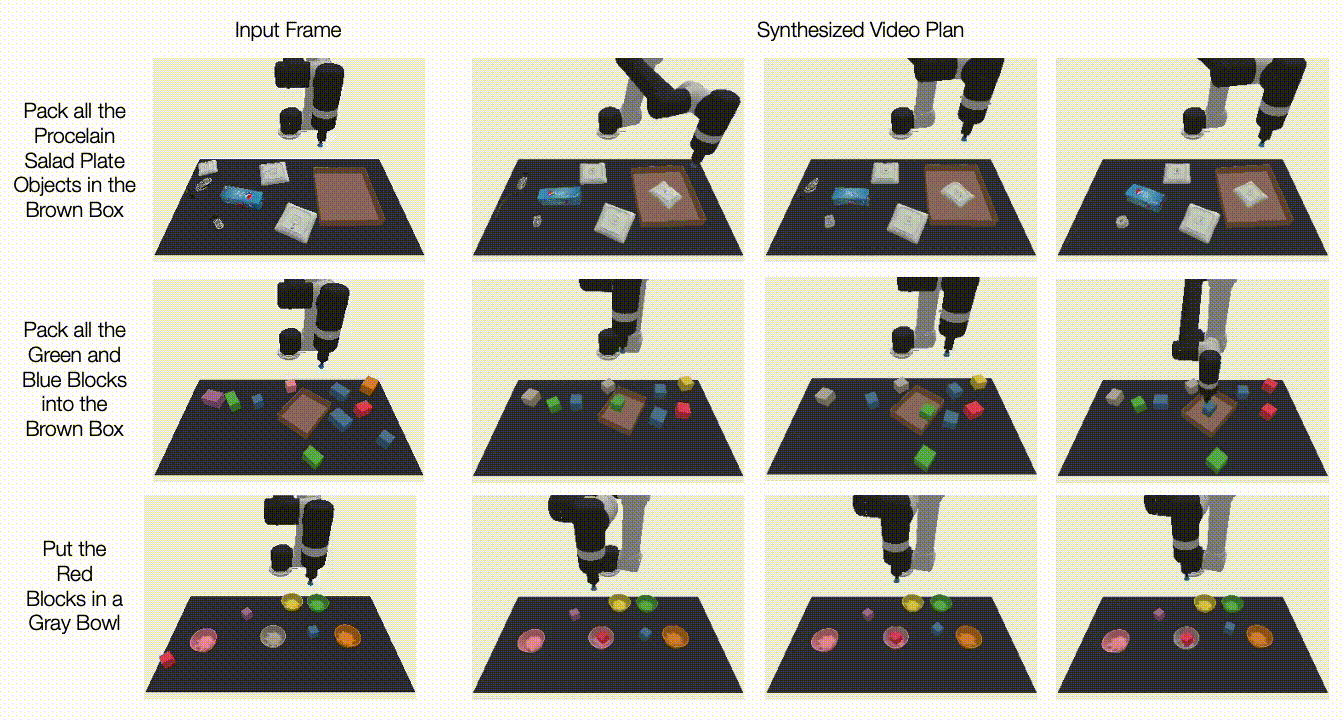 |
| برنامههای ویدیویی برای کارهای مختلف آزمایشی جدید در تنظیمات چند وظیفهای ایجاد میشود. |
انتقال دنیای واقعی
در زیر، ویدیوهای تولید شده را با دستورالعملهای زبانی در مورد تصاویر واقعی دیده نشده بیشتر نشان میدهیم. رویکرد ما قادر به ترکیب مجموعه ای متنوع از رفتارهای مختلف است که دستورالعمل های زبان را برآورده می کند:
 |
استفاده از پیشآموزش اینترنتی، UniPi را قادر میسازد تا ویدیوهای کارهایی را که در طول آموزش دیده نمیشوند، ترکیب کند. در مقابل، مدلی که از ابتدا آموزش داده شده است، به اشتباه برنامه هایی از وظایف مختلف تولید می کند:
 |
برای ارزیابی کیفیت ویدیوهای تولید شده توسط UniPi در زمانی که از قبل بر روی دادههای غیر روباتی آموزش داده شدهاند، از معیارهای فاصله اولیه Fréchet (FID) و Fréchet Video Distance (FVD) استفاده میکنیم. ما از نمرات پیشآموزشی زبان-تصویر متضاد (CLIPScores) برای اندازهگیری تراز زبان-تصویر استفاده کردیم. ما نشان میدهیم که UniPi از قبل آموزشدیده به نمرات FID و FVD بسیار بالاتر و CLIPScore بهتری در مقایسه با UniPi بدون پیشآموزش دست مییابد، و نشان میدهد که پیشآموزش روی دادههای غیر روباتی به تولید طرحهایی برای روباتها کمک میکند. ما امتیازات CLIPScore، FID، و VID را برای UniPi که بر روی دادههای Bridge آموزش دیدهاند، با و بدون پیشآموزش گزارش میکنیم:
| مدل (24×40) | CLIPScore ↑ | FID ↓ | FVD ↓ | ||||||||
| بدون پیش تمرین | 0.04 ± 24.43 | 0.56 ± 17.75 | 288.02 ± 10.45 | ||||||||
| از قبل آموزش دیده | 24.54 0.03 ± | 14.54 0.57 ± | 264.66 13.64 ± |
| استفاده از دادههای اینترنتی موجود، پیشبینیهای طرح ویدیویی را تحت تمام معیارهای در نظر گرفته بهبود میبخشد. |
آینده مدل های مولد در مقیاس بزرگ برای تصمیم گیری
نتایج مثبت UniPi به جهت گستردهتر استفاده از مدلهای مولد و انبوه دادهها در اینترنت به عنوان ابزارهای قدرتمند برای یادگیری سیستمهای تصمیمگیری همهمنظوره اشاره دارد. UniPi تنها یک قدم به سوی آنچه که مدلهای مولد میتوانند در تصمیمگیری به ارمغان بیاورند است. نمونههای دیگر شامل استفاده از مدلهای پایه مولد برای ارائه شبیهسازهای فوتورئالیستی یا زبانی جهان است که در آن عوامل مصنوعی میتوانند به طور نامحدود آموزش ببینند. مدلهای مولد بهعنوان عامل همچنین میتوانند تعامل با محیطهای پیچیدهای مانند اینترنت را بیاموزند، به طوری که کارهای بسیار گستردهتر و پیچیدهتر در نهایت میتوانند خودکار شوند. ما مشتاقانه منتظر تحقیقات آینده در استفاده از مدلهای پایه در مقیاس اینترنت برای تنظیمات چند محیطی و چند تجسمی هستیم.
سپاسگزاریها
مایلیم از همه نویسندگان باقیمانده مقاله از جمله بو دای، هانجون دای، اوفیر ناچوم، جاشوا بی. تننبام، دیل شوورمانس، و پیتر آببل تشکر کنیم. مایلیم از جورج تاکر، داگلاس اک و وینسنت ونهوک برای بازخورد در مورد این پست و مقاله اصلی تشکر کنیم.