روشهای یادگیری تقویتی عمیق فعلی (RL) میتوانند عوامل مصنوعی متخصصی را آموزش دهند که در تصمیمگیری در مورد وظایف مختلف فردی در محیطهای خاص مانند Go یا StarCraft برتری داشته باشند. با این حال، پیشرفت اندکی برای گسترش این نتایج به عوامل کلی که نه تنها قادر به انجام بسیاری از وظایف مختلف هستند، بلکه در محیطهای مختلف با تجسمهای بالقوه متمایز نیز انجام شده است.
با نگاهی به پیشرفتهای اخیر در زمینههای پردازش زبان طبیعی، بینایی و مدلهای مولد (مانند PalM، Imagen، و Flamingo)، میبینیم که پیشرفتها در ساخت مدلهای همه منظوره اغلب با بزرگنمایی مدلهای مبتنی بر ترانسفورماتور و آموزش به دست میآیند. آنها بر روی مجموعه داده های بزرگ و متنوع معنایی. طبیعی است که تعجب کنیم، آیا می توان از یک استراتژی مشابه در ساخت عوامل عمومی برای تصمیم گیری متوالی استفاده کرد؟ آیا چنین مدلهایی میتوانند تطبیق سریع با وظایف جدید، مشابه PalM و Flamingo را نیز فراهم کنند؟
به عنوان گام اولیه برای پاسخ به این پرسشها، در مقاله اخیر خود «تبدیلکنندههای تصمیمگیری چند بازی»، چگونگی ساخت یک عامل عمومی برای اجرای همزمان بسیاری از بازیهای ویدیویی را بررسی میکنیم. مدل ما عاملی را آموزش می دهد که می تواند 41 بازی Atari را به طور همزمان با عملکرد نزدیک به انسان اجرا کند و همچنین می تواند به سرعت با بازی های جدید از طریق تنظیم دقیق سازگار شود. این رویکرد به طور قابل توجهی بر روی چند جایگزین موجود برای یادگیری عوامل چند بازی، مانند یادگیری تفاوت زمانی (TD) یا شبیه سازی رفتاری (BC) بهبود می بخشد.
 |
| یک مبدل تصمیم چند بازی (MGDT) می تواند چندین بازی را در سطح مطلوبی از شایستگی از زمان آموزش در طیف وسیعی از مسیرها که همه سطوح تخصص را در بر می گیرد، انجام دهد. |
برای بازگشت بهینه سازی نکنید، فقط بهینه سازی را بخواهید
در یادگیری تقویتی، جایزه به سیگنال های تشویقی مربوط به تکمیل یک کار اشاره دارد و برگشت اشاره دارد به انباشته پاداش در دوره ای از تعاملات بین یک عامل و محیط اطرافش. عوامل یادگیری تقویت عمیق سنتی (DQN، SimPLe، Dreamer، و غیره) آموزش دیده اند بهینه سازی تصمیمات برای دستیابی به بازده بهینه. در هر مرحله زمانی، یک عامل محیط را مشاهده میکند (بعضیها نیز فعل و انفعالاتی را که در گذشته اتفاق افتاده در نظر میگیرند) و تصمیم میگیرد که چه اقدامی برای کمک به خود برای دستیابی به میزان بازده بالاتر در تعاملات آینده انجام دهد.
در این کار، ما از ترانسفورماتورهای تصمیم به عنوان رویکرد اصلی خود برای آموزش یک عامل RL استفاده می کنیم. ترانسفورماتور تصمیم یک مدل توالی است که با در نظر گرفتن فعل و انفعالات گذشته بین یک عامل و محیط اطراف، و (مهمتر از همه) یک مورد دلخواه، اقدامات آینده را پیش بینی می کند. برگشت در تعاملات آینده به دست آید. ترانسفورماتور تصمیم به جای یادگیری خط مشی برای دستیابی به میزان بازدهی بالا مانند یادگیری تقویتی سنتی، تجربیات متنوعی را ترسیم می کند، از سطح متخصص تا سطح مبتدی، تا میزان بازگشت متناظر آنها در طول آموزش. ایده این است که آموزش یک نماینده بر روی طیف وسیعی از تجربیات (از سطح مبتدی تا متخصص) مدل را در معرض طیف وسیع تری از تغییرات در گیم پلی قرار می دهد، که به نوبه خود به آن کمک می کند قوانین مفیدی از گیم پلی استخراج کند که به آن اجازه می دهد تحت هر شرایطی موفق شود. بنابراین در طول استنتاج، ترانسفورماتور تصمیم می تواند به هر مقدار بازگشتی در محدوده ای که در طول آموزش دیده است، از جمله بازده بهینه دست یابد.
اما، چگونه میدانید که بازدهی در یک محیط معین هم بهینه و هم پایدار است؟ کاربردهای قبلی Decision Transformers متکی به تعاریف سفارشی شده از بازده مورد نظر برای هر کار جداگانه بود، که مستلزم تعریف دستی یک محدوده معقول و آموزنده از مقادیر اسکالر بود که سیگنالهای قابل تفسیر مناسب برای هر بازی خاص هستند – وظیفهای که بیاهمیت و نسبتاً مقیاسپذیر نیست. . برای پرداختن به این موضوع، ما در عوض توزیع مقادیر بازگشت را بر اساس تعاملات گذشته با محیط در طول آموزش مدل می کنیم. در زمان استنتاج، ما به سادگی یک سوگیری بهینه را اضافه می کنیم که احتمال ایجاد اقدامات مرتبط با بازده بالاتر را افزایش می دهد.
برای ثبت جامعتر الگوهای مکانی-زمانی تعاملات عامل-محیط، ما همچنین معماری ترانسفورماتور تصمیم را تغییر دادیم تا وصلههای تصویر را به جای نمایش تصویر جهانی در نظر بگیریم. وصلهها به مدل اجازه میدهند تا روی پویایی محلی تمرکز کند، که به مدلسازی اطلاعات خاص بازی در جزئیات بیشتر کمک میکند.
این قطعات در کنار هم به ما ستون فقرات Multi-Game Decision Transformers را می دهند:
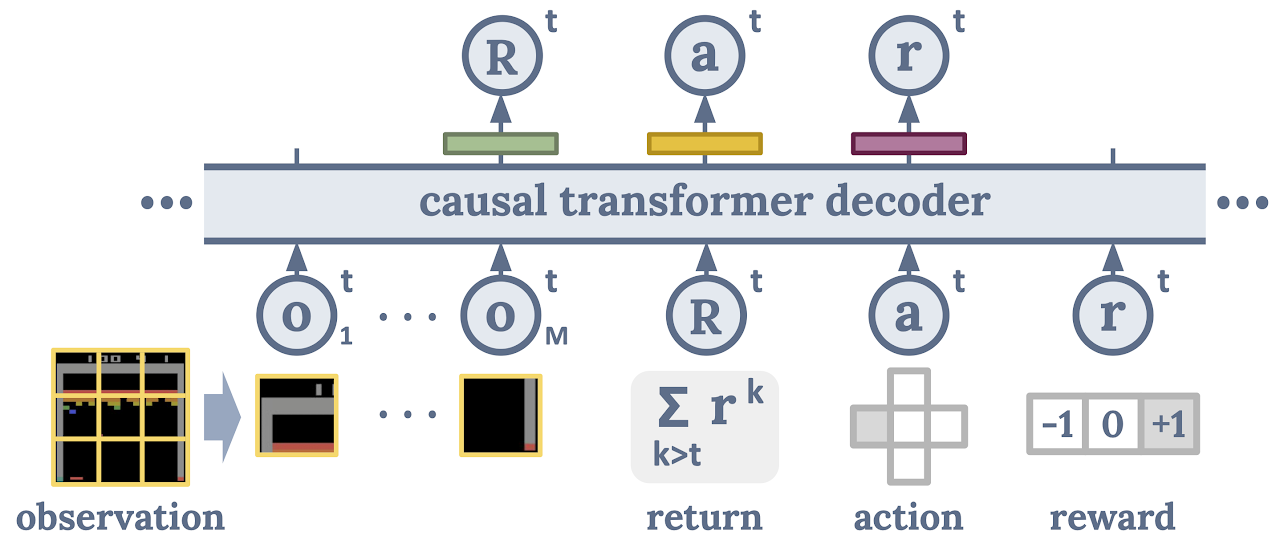 |
| هر تصویر مشاهده ای به مجموعه ای از م تکه های پیکسلی که مشخص می شوند O. برگشت آر، عمل آ، و پاداش r این وصله های تصویر را در هر دنباله علی ورودی دنبال می کند. یک ترانسفورماتور تصمیم برای پیشبینی ورودی بعدی (به جز وصلههای تصویر) برای ایجاد علیت آموزش دیده است. |
آموزش ترانسفورماتور تصمیم گیری چند بازی برای اجرای همزمان 41 بازی
ما یک نماینده Decision Transformer را با مجموعه ای بزرگ (~1B) و گیم پلی از 41 بازی Atari آموزش می دهیم. در آزمایشهای ما، این عامل، که ما آن را تبدیلکننده تصمیمگیری چند بازی (MGDT) مینامیم، به وضوح از روشهای یادگیری تقویتی و شبیهسازی رفتاری موجود – تقریباً 2 برابر – در یادگیری بازی 41 بازی به طور همزمان بهتر عمل میکند و تقریباً تواناییهای سطح انسانی را انجام میدهد. 100% در شکل زیر با سطح گیم پلی انسان مطابقت دارد). این نتایج هنگام مقایسه روشهای آموزشی در هر دو تنظیمات که در آن یک خطمشی باید از مجموعه دادههای ثابت (آفلاین) و همچنین مواردی که میتوان دادههای جدید را از تعامل با محیط جمعآوری کرد (آنلاین) یاد گرفت، باقی میماند.
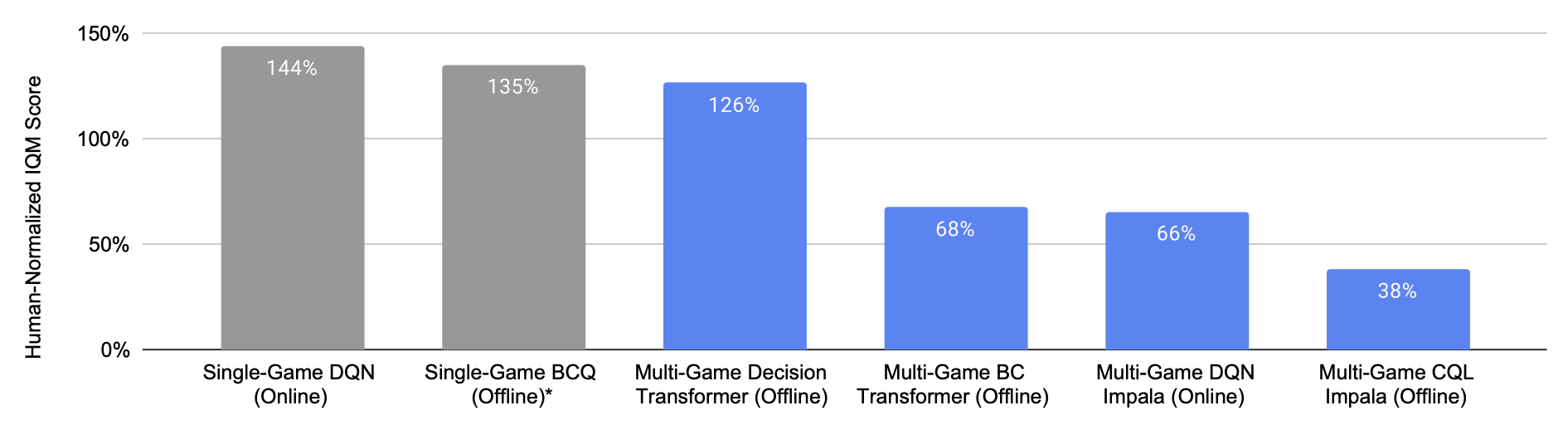 |
| هر نوار یک امتیاز ترکیبی در 41 بازی است که 100٪ عملکرد در سطح انسانی را نشان می دهد. هر نوار آبی از مدلی است که روی 41 بازی به طور همزمان آموزش دیده است، در حالی که هر نوار خاکستری از 41 نماینده متخصص است. Multi-Game Decision Transformer به عملکردی در سطح انسانی دست می یابد، به طور قابل توجهی بهتر از سایر عوامل چند بازی، حتی قابل مقایسه با عوامل متخصص. |
این نتیجه نشان می دهد که ترانسفورماتورهای تصمیم برای عوامل چند وظیفه ای، چند محیطی و چند تجسمی مناسب هستند.
یک کار همزمان، “یک عامل عمومی”، نتیجه مشابهی را نشان میدهد و نشان میدهد که مدلهای توالی مبتنی بر ترانسفورماتور بزرگ میتوانند رفتارهای متخصص را در بسیاری از محیطهای دیگر به خوبی به خاطر بسپارند. علاوه بر این، کار آنها و کار ما یافتههای مکمل خوبی دارد: آنها نشان میدهند که میتوان در محیطهای مختلف فراتر از بازیهای آتاری تمرین کرد، در حالی که ما نشان میدهیم که آموزش در طیف وسیعی از تجربیات ممکن و مفید است.
علاوه بر عملکرد نشاندادهشده در بالا، از نظر تجربی دریافتیم که MGDT آموزشدیده بر اساس تجربیات مختلف بهتر از MDGT است که فقط بر روی نمایشهای سطح متخصص یا رفتارهای نمایشی شبیهسازی ساده آموزش داده میشود.
افزایش اندازه مدل چند بازی برای دستیابی به عملکرد بهتر
مسلماً مقیاس به نیروی محرکه اصلی در بسیاری از پیشرفتهای اخیر یادگیری ماشین تبدیل شده است و معمولاً با افزایش تعداد پارامترها در یک مدل مبتنی بر ترانسفورماتور به دست میآید. مشاهدات ما در مورد Transformers تصمیم چند بازی مشابه است: عملکرد به طور قابل پیش بینی با اندازه مدل بزرگتر افزایش می یابد. به طور خاص، به نظر می رسد عملکرد آن هنوز به سقف نرسیده است، و در مقایسه با سایر سیستم های یادگیری، دستاوردهای عملکرد با افزایش اندازه مدل قابل توجه تر است.
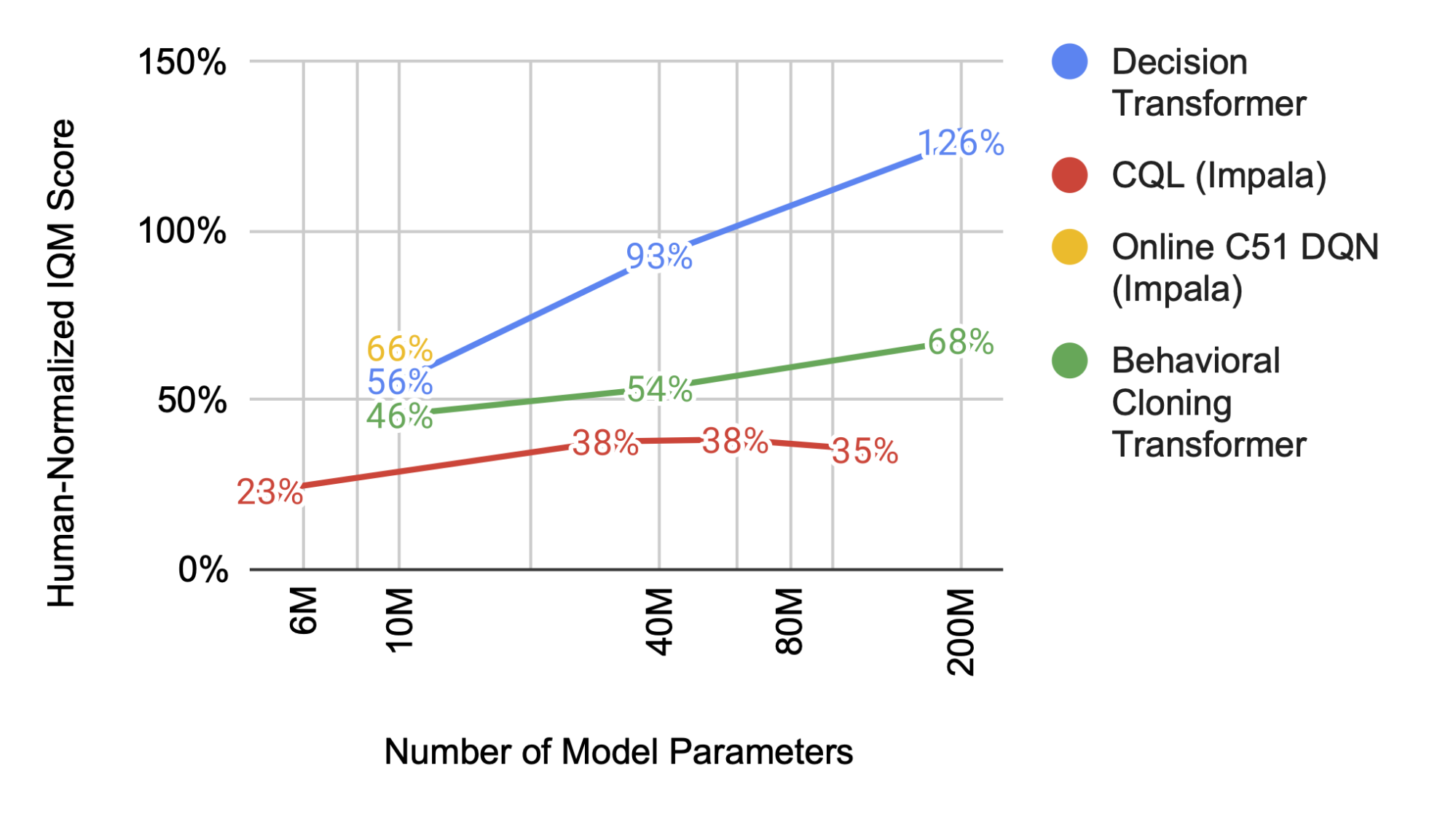 |
| عملکرد ترانسفورماتور تصمیم گیری چند بازی (نشان داده شده با خط آبی) با اندازه مدل بزرگتر به طور قابل پیش بینی افزایش می یابد، در حالی که مدل های دیگر اینطور نیستند. |
ترانسفورماتورهای تصمیم گیری چند بازی از پیش آموزش داده شده، یادگیرندگان سریع هستند
یکی دیگر از مزایای MGDT ها این است که آنها می توانند یاد بگیرند که چگونه یک بازی جدید را از چند نمایش گیم پلی (که لازم نیست همه آنها در سطح متخصص باشند) بازی کنند. از این نظر، MGDT ها را می توان مدل های از پیش آموزش دیده ای در نظر گرفت که می توانند به سرعت بر روی داده های کوچک گیم پلی جدید تنظیم شوند. در مقایسه با سایر روشهای رایج پیشآموزشی، به وضوح مزایای ثابتی در کسب امتیازات بالاتر نشان میدهد.
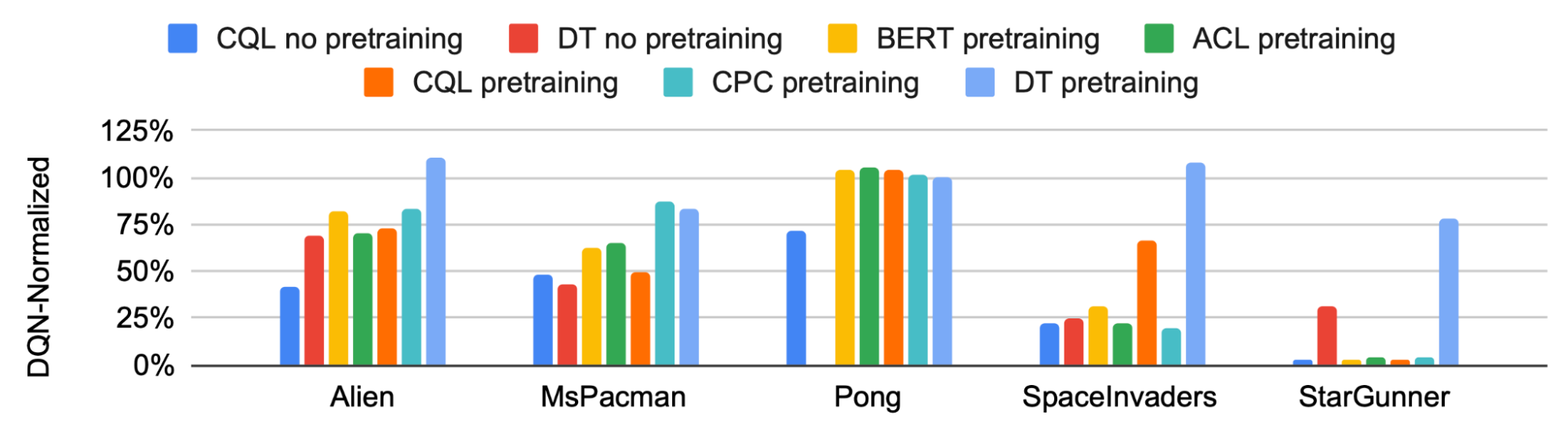 |
| پیشآموزش مبدل تصمیمگیری چند بازی (پیشآموزشی DT، نشاندادهشده به رنگ آبی روشن) مزایای ثابتی را نسبت به سایر مدلهای محبوب در سازگاری با وظایف جدید نشان میدهد. |
نماینده به کجا نگاه می کند؟
علاوه بر ارزیابی کمی، تجسم رفتار عامل بصیرتی (و سرگرم کننده) است. با بررسی سرهای توجه، متوجه میشویم که مدل MGDT به طور مداوم وزن را در میدان دید خود به مناطقی از تصاویر مشاهدهشده که حاوی موجودیتهای بازی معنیدار هستند، قرار میدهد. ما توجه مدل را هنگام پیشبینی اقدام بعدی برای بازیهای مختلف تجسم میکنیم و متوجه میشویم که به طور مداوم به نهادهایی مانند آواتار روی صفحه نمایش، فضای حرکت آزاد عامل، اشیاء غیر عامل و ویژگیهای کلیدی محیط توجه میکند. برای مثال، در یک محیط تعاملی، داشتن یک مدل جهان دقیق مستلزم دانستن چگونگی و زمان تمرکز بر روی اشیاء شناخته شده (مثلاً موانع فعلی) و همچنین انتظار و/یا برنامه ریزی برای ناشناخته های آینده است (مثلاً فضای منفی). این تخصیص متنوع توجه به بسیاری از اجزای کلیدی هر محیط در نهایت عملکرد را بهبود می بخشد.
 |
| در اینجا میتوانیم میزان وزنی را که مدل روی هر دارایی کلیدی صحنه بازی میگذارد، ببینیم. قرمز روشنتر نشاندهنده تاکید بیشتر روی آن تکه پیکسل است. |
آینده کارگزاران عمومی در مقیاس بزرگ
این کار گام مهمی در نشان دادن امکان آموزش عوامل همه منظوره در بسیاری از محیطها، تجسمها و سبکهای رفتاری است. ما مزایای افزایش مقیاس در عملکرد و پتانسیل را با مقیاس بندی بیشتر نشان داده ایم. به نظر میرسد این یافتهها به روایتی تعمیمدهنده مشابه با حوزههای دیگر مانند بینش و زبان اشاره میکنند که به پتانسیل بزرگ مقیاسبندی دادهها و اثربخشی یادگیری از تجربیات متنوع اشاره میکند.
ما مشتاقانه منتظر تحقیقات آینده برای توسعه عوامل عملکردی برای تنظیمات چند محیطی و چند تجسمی هستیم. کد و مدل چک پوینتهای ما در اینجا قابل دسترسی هستند.
سپاسگزاریها
مایلیم از همه نویسندگان باقیمانده مقاله از جمله ایگور مرداچ، اوفر ناچوم منجیائو یانگ، لیزا لی، دانیل فریمن، سرجیو گوآداراما، ایان فیشر، اریک جانگ، هنریک میکالوسکی تشکر کنیم.