مدلهای یادگیری عمیق پیشرفت چشمگیری در بینایی، زبان و سایر روشها داشتهاند، بهویژه با افزایش پیشآموزش در مقیاس بزرگ. چنین مدلهایی زمانی دقیقتر هستند که برای دادههای آزمایشی که از توزیع مشابه مجموعه آموزشی آنها استخراج شدهاند، اعمال شوند. با این حال، در عمل، مدلهای مواجهه با داده در تنظیمات دنیای واقعی به ندرت با توزیع آموزشی مطابقت دارند. علاوه بر این، مدل ها ممکن است برای کاربردهایی که عملکرد پیش بینی تنها بخشی از معادله است، مناسب نباشند. برای اینکه مدلها در استقرار قابل اعتماد باشند، باید بتوانند تغییراتی را در توزیع دادهها تطبیق دهند و در طیف وسیعی از سناریوها تصمیمات مفیدی بگیرند.
در “Plex: Towards Reliability Using Pre-trained Large Model Extensions” چارچوبی برای یادگیری عمیق قابل اعتماد به عنوان یک دیدگاه جدید در مورد توانایی های یک مدل؛ این شامل تعدادی از وظایف و مجموعه داده های مشخص برای قابلیت اطمینان مدل تست استرس است. ما همچنین Plex را معرفی می کنیم، مجموعه ای از پسوندهای مدل بزرگ از پیش آموزش دیده که می توانند در بسیاری از معماری های مختلف اعمال شوند. ما کارایی Plex را در حوزههای بینایی و زبان با استفاده از این پسوندها در مدلهای Vision Transformer و T5 پیشرفته نشان میدهیم که منجر به بهبود قابل توجهی در قابلیت اطمینان آنها میشود. ما همچنین کد منبع باز را برای تشویق تحقیقات بیشتر در مورد این رویکرد، منبع باز می کنیم.
 |
| عدم قطعیت — طبقه بندی سگ در مقابل گربه: Plex می تواند بگوید “من نمی دانم” برای ورودی هایی که نه گربه هستند و نه سگ. تعمیم قوی – یک مدل ساده به همبستگی های جعلی (“مقصد”) حساس است، در حالی که Plex قوی است. انطباق – می توانید Plex فعالانه انتخاب کنید داده هایی که از آنها یاد می گیرد تا عملکرد را سریعتر بهبود بخشد. |
چارچوبی برای قابلیت اطمینان
ابتدا، چگونگی درک قابلیت اطمینان یک مدل در سناریوهای جدید را بررسی می کنیم. ما سه دسته کلی از الزامات را برای سیستمهای یادگیری ماشینی قابل اعتماد (ML) ارائه میکنیم: (1) آنها باید عدم قطعیت را در مورد پیشبینیهای خود بهطور دقیق گزارش کنند.“آنچه را که نمی دانند بدانند”) (2) آنها باید قویاً به سناریوهای جدید تعمیم دهند (تغییر توزیع). و (3) آنها باید بتوانند به طور موثر با داده های جدید سازگار شوند (انطباق). مهمتر از همه، هدف یک مدل قابل اعتماد باید به خوبی انجام شود همه از این مناطق به طور همزمان خارج از جعبه، بدون نیاز به هیچ گونه سفارشی سازی برای وظایف فردی.
- عدم قطعیت منعکس کننده اطلاعات ناقص یا ناشناخته است که پیش بینی دقیق را برای یک مدل دشوار می کند. کمیسازی عدم قطعیت پیشبینیکننده به مدل اجازه میدهد تا تصمیمهای بهینه را محاسبه کند و به پزشکان کمک میکند تشخیص دهند که چه زمانی به پیشبینیهای مدل اعتماد کنند، در نتیجه زمانی که مدل احتمالاً اشتباه است، شکستهای دلپذیری را ممکن میسازد.
- تعمیم قوی شامل تخمین یا پیش بینی در مورد یک رویداد غیرقابل مشاهده است. ما چهار نوع داده خارج از توزیع را بررسی میکنیم: تغییر متغیر (زمانی که توزیع ورودی بین آموزش و برنامه تغییر میکند و توزیع خروجی بدون تغییر است)، تغییر معنایی (یا کلاس)، عدم قطعیت برچسب، و تغییر جمعیت فرعی.
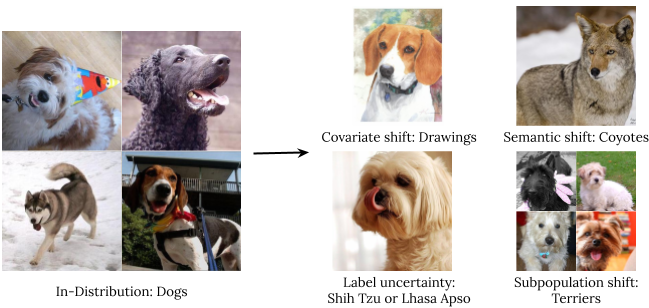
انواع تغییر توزیع با استفاده از تصویری از سگ های ImageNet. - انطباق به بررسی توانایی های مدل در طول فرآیند یادگیری آن اشاره دارد. معیارها معمولاً روی مجموعه دادههای ثابت با تقسیمبندیهای آزمایشی قطار از پیش تعریفشده ارزیابی میشوند. با این حال، در بسیاری از برنامهها، ما به مدلهایی علاقهمندیم که میتوانند به سرعت با مجموعه دادههای جدید سازگار شوند و با کمترین نمونه برچسبگذاری شده به طور موثر یاد بگیرند.
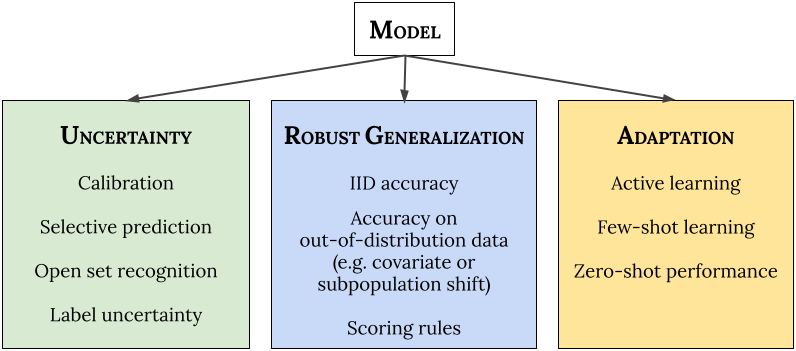 |
| چارچوب قابلیت اطمینان. ما پیشنهاد میکنیم که به طور همزمان عملکرد مدل «خارج از جعبه» (یعنی توزیع پیشبینیکننده) را در سراسر عدم قطعیت، تعمیم قوی، و معیارهای انطباق، بدون هیچ گونه سفارشیسازی برای وظایف فردی، تست استرس انجام دهیم. |
ما 10 نوع کار را برای به دست آوردن سه حوزه قابلیت اطمینان – عدم قطعیت، تعمیم قوی، و انطباق – اعمال می کنیم و اطمینان می دهیم که وظایف مجموعه متنوعی از ویژگی های مطلوب را در هر منطقه اندازه گیری می کنند. این وظایف با هم شامل 40 مجموعه داده پایین دستی در بین روشهای بینایی و زبان طبیعی است: 14 مجموعه داده برای تنظیم دقیق (شامل انطباق مبتنی بر یادگیری فعال و چند شات) و 26 مجموعه داده برای ارزیابی خارج از توزیع.
Plex: برنامه های افزودنی مدل بزرگ از قبل آموزش دیده برای Vision و Language
برای بهبود قابلیت اطمینان، ViT-Plex و T5-Plex را توسعه میدهیم که به ترتیب بر روی مدلهای بزرگ از پیش آموزش دیده برای بینایی (ViT) و زبان (T5) بنا شدهاند. یکی از ویژگیهای کلیدی Plex، ترکیب کارآمدتر بر اساس مدلهای فرعی است که هر یک پیشبینی میکنند و سپس تجمیع میشوند. علاوه بر این، Plex آخرین لایه خطی هر معماری را با یک فرآیند گاوسی یا لایه ناهمسانی مبادله می کند تا عدم قطعیت پیش بینی را بهتر نشان دهد. مشخص شد که این ایدهها برای مدلهایی که از ابتدا در مقیاس ImageNet آموزش دیدهاند، بسیار خوب عمل میکنند. ما مدلها را با اندازههای مختلف تا 325 میلیون پارامتر برای بینایی (ViT-Plex L) و 1 میلیارد پارامتر برای زبان (T5-Plex L) و اندازههای داده قبل از آموزش تا 4 میلیارد نمونه آموزش میدهیم.
شکل زیر عملکرد Plex را در یک مجموعه منتخب از وظایف در مقایسه با وضعیت موجود موجود نشان می دهد. مدل با عملکرد برتر برای هر کار معمولاً یک مدل تخصصی است که برای آن مشکل بسیار بهینه شده است. Plex در بسیاری از 40 مجموعه داده به پیشرفتهترین پیشرفتهترین دستاوردها دست یافته است. نکته مهم، Plex با استفاده از خروجی مدل خارج از جعبه، بدون نیاز به طراحی یا تنظیم سفارشی برای هر کار، عملکرد قوی را در تمام وظایف به دست می آورد.
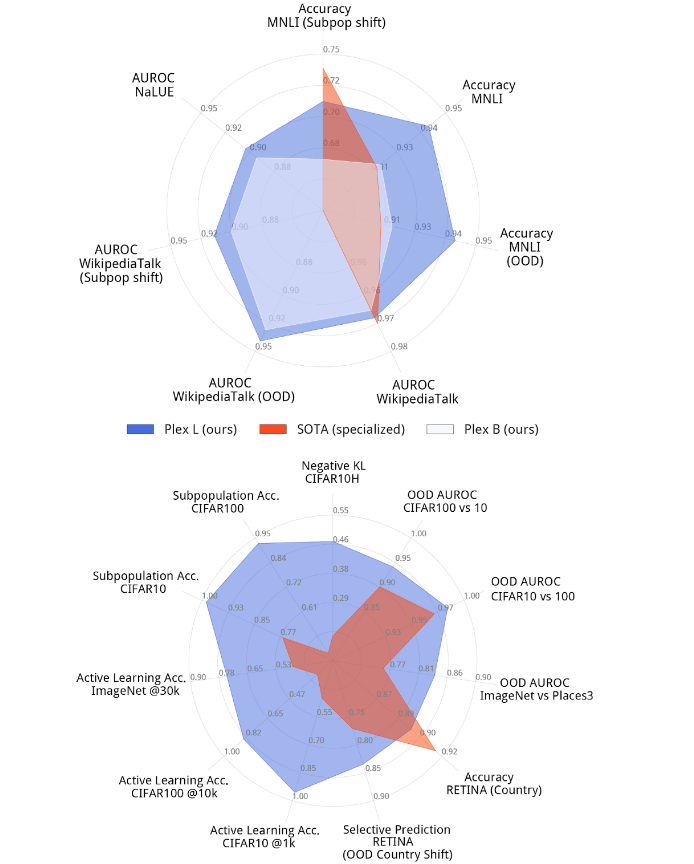 |
| بزرگترین T5-Plex (بالا) و ViT-Plex (پایین) مدلهایی که بر روی مجموعهای برجسته از وظایف قابلیت اطمینان در مقایسه با مدلهای تخصصی پیشرفته ارزیابی شدهاند. پره ها وظایف مختلفی را نشان می دهند و عملکرد متریک را در مجموعه داده های مختلف کمی می کنند. |
Plex در عمل برای وظایف مختلف قابلیت اطمینان
ما قابلیت اطمینان Plex را در کارهای انتخابی در زیر برجسته میکنیم.
Set Recognition را باز کنید
خروجی Plex را در حالتی نشان میدهیم که مدل باید پیشبینی را به تعویق بیندازد زیرا ورودی ورودی است که مدل از آن پشتیبانی نمیکند. این وظیفه به عنوان بازشناسی مجموعه شناخته می شود. در اینجا، عملکرد پیشبینیکننده بخشی از یک سناریوی تصمیمگیری بزرگتر است که در آن مدل ممکن است از انجام پیشبینیهای خاص خودداری کند. در شکل زیر نشان می دهیم ساختار یافته بازشناسی مجموعه باز: Plex خروجی های متعددی را برمی گرداند و به بخش خاصی از خروجی که مدل نامشخص است و احتمالاً خارج از توزیع است، سیگنال می دهد.
 |
| تشخیص مجموعه باز ساختاریافته، مدل را قادر میسازد تا شفافسازیهای ظریف را ارائه دهد. در اینجا، T5-Plex L میتواند موارد ریزدانه خارج از توزیع را که در آن درخواست عمودی (یعنی دامنه خدمات در سطح درشت، مانند بانکداری، رسانه، بهرهوری و غیره) و دامنه پشتیبانی میشود، تشخیص دهد، اما هدف این است که نه |
برچسب عدم قطعیت
در مجموعه داده های دنیای واقعی، اغلب ابهام ذاتی در پشت برچسب حقیقت زمینی برای هر ورودی وجود دارد. به عنوان مثال، این ممکن است به دلیل ابهام رتبهدهنده انسانی برای یک تصویر مشخص باشد. در این مورد، ما می خواهیم مدل توزیع کامل عدم قطعیت ادراکی انسان را به تصویر بکشد. ما Plex را در زیر بر روی نمونههایی از یک نوع ImageNet که ساختهایم که توزیع برچسب حقیقت زمینی را ارائه میکند، نشان میدهیم.
 |
| Plex برای عدم قطعیت برچسب. با استفاده از مجموعه دادهای به نام ImageNet Real-H، ViT-Plex L توانایی ثبت ابهام ذاتی (توزیع احتمال) برچسبهای تصویر را نشان میدهد. |
یادگیری فعال
ما توانایی یک مدل بزرگ را بررسی میکنیم که نه تنها از طریق مجموعه ثابتی از نقاط داده یاد میگیرد، بلکه در دانستن اینکه از کدام نقاط داده در وهله اول باید یاد گرفت، مشارکت میکند. یکی از این کارها به عنوان یادگیری فعال شناخته می شود، جایی که در هر مرحله آموزشی، مدل ورودی های امیدوارکننده ای را از میان مجموعه ای از نقاط داده بدون برچسب انتخاب می کند که در آن آموزش ببیند. این روش کارایی برچسب مدل ML را ارزیابی میکند، جایی که حاشیهنویسی برچسب ممکن است کمیاب باشد، و بنابراین ما میخواهیم عملکرد را به حداکثر برسانیم و در عین حال تعداد نقاط داده برچسبگذاری شده را به حداقل برسانیم. Plex به بهبود عملکرد قابل توجهی نسبت به معماری مدل مشابه بدون آموزش قبلی دست می یابد. علاوه بر این، حتی با نمونههای آموزشی کمتر، از پیشرفتهترین روش پیشآموزششده، BASE نیز بهتر عمل میکند، که در ۱۰۰ هزار نمونه به دقت ۶۳ درصد میرسد.
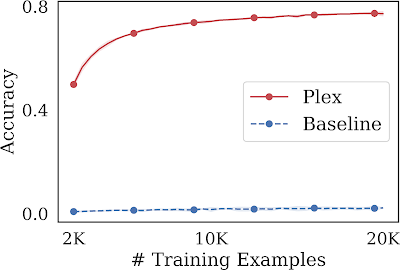 |
| یادگیری فعال در ImageNet1K. ViT-Plex L در مقایسه با یک خط پایه که از قبل از تمرین استفاده نمی کند، بسیار کارآمد است. ما همچنین دریافتیم که استراتژی اکتساب داده های یادگیری فعال موثرتر از انتخاب یکنواخت نقاط داده به صورت تصادفی است. |
بیشتر بدانید
مقاله ما را در اینجا و یک گفتگوی کمکی آتی در مورد کار در کارگاه آموزشی ICML 2022 در 23 ژوئیه 2022 بررسی کنید. برای تشویق تحقیقات بیشتر در این راستا، ما همه کدهای آموزش و ارزیابی را به عنوان بخشی از عدم قطعیت منبع باز می کنیم. خطوط پایه ما همچنین یک نسخه نمایشی ارائه می دهیم که نحوه استفاده از یک چک پوینت مدل ViT-Plex را نشان می دهد. پیاده سازی لایه و روش از Edward2 استفاده می کند.
سپاسگزاریها
از همه نویسندگان همکار برای مشارکت در پروژه و مقاله تشکر می کنیم، از جمله آندریاس کرش، کلارا هویی هو، دوفان، دی. اسکالی، هونگلین یوان، جاسپر اسنوک، جرمیا لیو، جی رن، جوست ون آمرسفورت، کاران سینگال، کهنگ هان، کلی بوکانان، کوین مورفی، مارک کولیر، مایک دوسنبری، نیل بند، نیثوم تاین، رودلف جناتتون، تیم جی رودنر، یارین گال، زکری نادو، زلدا ماریت، زی وانگ و زوبین قهرمانی. همچنین از Anusha Ramesh، Ben Adlam، Dilip Krishnan، Ed Chi، Neil Houlsby، Rif A. Saurous، و Sharat Chikkerur برای بازخورد مفیدشان، و Tom Small و Ajay Nainani برای کمک به تجسمسازی تشکر میکنیم.