مدلهای زبان اکنون قادر به انجام بسیاری از وظایف جدید پردازش زبان طبیعی (NLP) با خواندن دستورالعملها هستند، اغلب مواردی که قبلاً ندیده بودند. توانایی استدلال در مورد وظایف جدید بیشتر به مدل های آموزشی در طیف گسترده ای از دستورالعمل های منحصر به فرد، معروف به “تنظیم دستورالعمل” است که توسط FLAN معرفی شد و در T0، Super-Natural Instructions، MetaICL، و InstructGPT گسترش یافت. با این حال، بسیاری از داده هایی که این پیشرفت ها را هدایت می کنند، برای جامعه تحقیقاتی گسترده تر منتشر نشده باقی می مانند.
که در “مجموعه Flan: طراحی داده ها و روش ها برای تنظیم مؤثر دستورالعملما مجموعهای جدیدتر و گستردهتر از وظایف، الگوها و روشهای تنظیم دستورالعملها را برای ارتقای توانایی جامعه برای تجزیه و تحلیل و بهبود روشهای تنظیم دستورالعمل، از نزدیک بررسی و منتشر میکنیم. این مجموعه برای اولین بار در Flan-T5 و Flan-PaLM مورد استفاده قرار گرفت، که دومی پیشرفت های قابل توجهی را نسبت به Palm بدست آورد. ما نشان میدهیم که آموزش یک مدل در این مجموعه نسبت به مجموعههای عمومی قابل مقایسه در همه معیارهای ارزیابی آزمایششده، عملکرد بهتری را به همراه دارد، بهعنوان مثال، بهبود ۳ درصدی در ۵۷ کار در مجموعه ارزیابی Massive Multitask Language Understanding (MMLU) و بهبود ۸ درصدی در BigBench. سخت (BBH). تجزیه و تحلیل نشان میدهد که این بهبودها هم از مجموعه وظایف بزرگتر و متنوعتر و هم از بهکارگیری مجموعهای از آموزشهای ساده و تکنیکهای تقویت دادهها که ارزان و آسان برای پیادهسازی هستند ناشی میشوند: مخلوط کردن ضربات صفر، چند شات و زنجیرهای از اعلانهای فکری در آموزش، غنی سازی وظایف با وارونگی ورودی، و متعادل کردن مخلوط وظایف. این روشها با هم، مدلهای زبانی بهدستآمده را قادر میسازند تا با مهارت بیشتری در مورد کارهای دلخواه استدلال کنند، حتی آنهایی که نمونههای تنظیم دقیقی برای آنها ندیده است. امیدواریم در دسترس قرار دادن این یافتهها و منابع برای عموم، تحقیق در مورد مدلهای زبانی قدرتمندتر و همهمنظوره را تسریع کند.
مجموعه داده های تنظیم دستورالعمل عمومی
از سال 2020، چندین مجموعه وظایف تنظیم دستورالعمل به سرعت منتشر شده است که در جدول زمانی زیر نشان داده شده است. تحقیقات اخیر هنوز حول مجموعهای از تکنیکها، با مجموعههای متفاوتی از وظایف، اندازههای مدل و قالبهای ورودی که همگی نشان داده شدهاند، ادغام نشدهاند. این مجموعه جدید، که در زیر به عنوان “Flan 2022” نامیده می شود، مجموعه های قبلی از FLAN، P3/T0، و دستورالعمل های طبیعی را با گفتگوی جدید، ترکیب برنامه، و وظایف استدلال پیچیده ترکیب می کند.
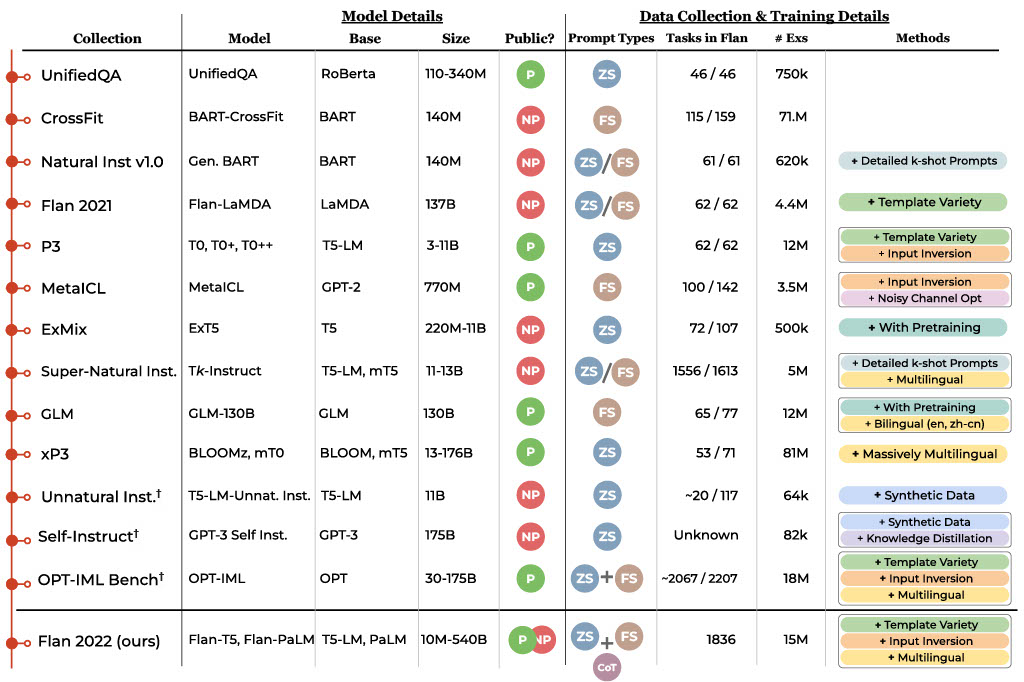 |
| جدول زمانی مجموعههای تنظیم دستورالعمل عمومی، از جمله: UnifiedQA، CrossFit، Natural Instructions، FLAN، P3/T0، MetaICL، ExT5، Super-Natural Instructions، mT0، Unnatural Instructions، Self-Instruct و OPT-IML Bench. جدول تاریخ انتشار، نام مجموعه کار، نام مدل، مدل(های) پایه که با این مجموعه تنظیم شده است، اندازه مدل، عمومی (سبز) یا غیر عمومی (قرمز) بودن مدل به دست آمده را توضیح می دهد. آنها با اعلان های صفر شات (“ZS”)، اعلان های چند شات (“FS”)، اعلان های زنجیره ای از فکر (“CoT”) با هم (“+”) یا جداگانه (“/”)، تعداد تمرین می کنند. از وظایف این مجموعه در Flan 2022، تعداد کل نمونه ها و چند روش قابل توجه مربوط به مجموعه های مورد استفاده در این آثار. توجه داشته باشید که تعداد کارها و مثال ها در مفروضات مختلف متفاوت است و به همین ترتیب تقریب ها نیز متفاوت هستند. تعداد هر یک با استفاده از تعاریف کار از آثار مربوطه گزارش شده است. |
مجموعه Flan علاوه بر مقیاسبندی به وظایف آموزشی آموزندهتر، آموزش را با انواع مختلف مشخصات ورودی-خروجی، از جمله دستورالعملها (اعلام صفر شات)، دستورالعملهایی با نمونههایی از کار (تشویق چند عکس)، و دستورالعملهایی که برای توضیح با پاسخ (زنجیره ای از افکار تحریک). به جز InstructGPT که مجموعه ای از داده های اختصاصی را به کار می گیرد، Flan 2022 اولین اثری است که به طور عمومی مزایای قوی ترکیب این تنظیمات را با هم در طول آموزش نشان می دهد. به جای مبادله بین تنظیمات مختلف، اختلاط تنظیمات اعلان در طول آموزش، تمام تنظیمات درخواست را در زمان استنتاج بهبود می بخشد، همانطور که در زیر نشان داده شده است هم برای وظایف نگه داشته شده و هم از مجموعه وظایف تنظیم دقیق.
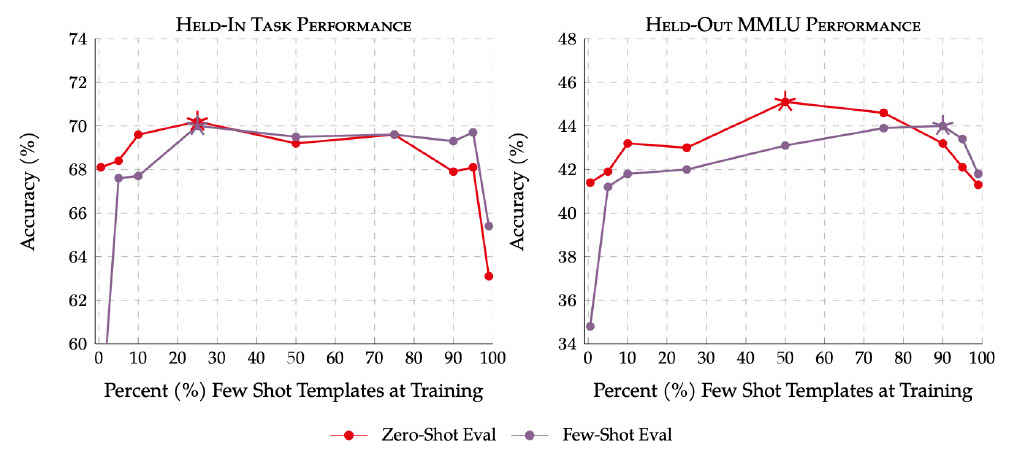 |
| آموزش به صورت مشترک با الگوهای اعلان صفر و چند شات عملکرد را در هر دو وظایف نگهداشتهشده و نگهداشتهشده بهبود میبخشد. ستاره ها اوج عملکرد را در هر تنظیم نشان می دهند. خطوط قرمز نشاندهنده ارزیابی درخواستی صفر شات است، یاس بنفش نشاندهنده ارزیابی درخواستی چند شات است. |
ارزیابی روش های تنظیم آموزش
برای درک تأثیرات کلی تعویض یک مجموعه تنظیم دستورالعمل با مجموعه دیگر، مدلهای T5 با اندازه معادل را در مجموعههای عمومی تنظیم دستورالعمل عمومی، از جمله Flan 2021، T0++، و دستورالعملهای Super-Natural تنظیم میکنیم. سپس هر مدل بر روی مجموعهای از وظایف که قبلاً در هر یک از مجموعههای تنظیم دستورالعمل گنجانده شده است، مجموعهای از پنج وظیفه زنجیرهای از فکر، و سپس مجموعهای از 57 کار متنوع از معیار MMLU، هر دو با صفر ارزیابی میشود. دستورات شات و چند شات. در هر مورد، مدل جدید Flan 2022، Flan-T5، از کارهای قبلی بهتر عمل میکند و یک استدلال NLP همه منظوره قویتر را نشان میدهد.
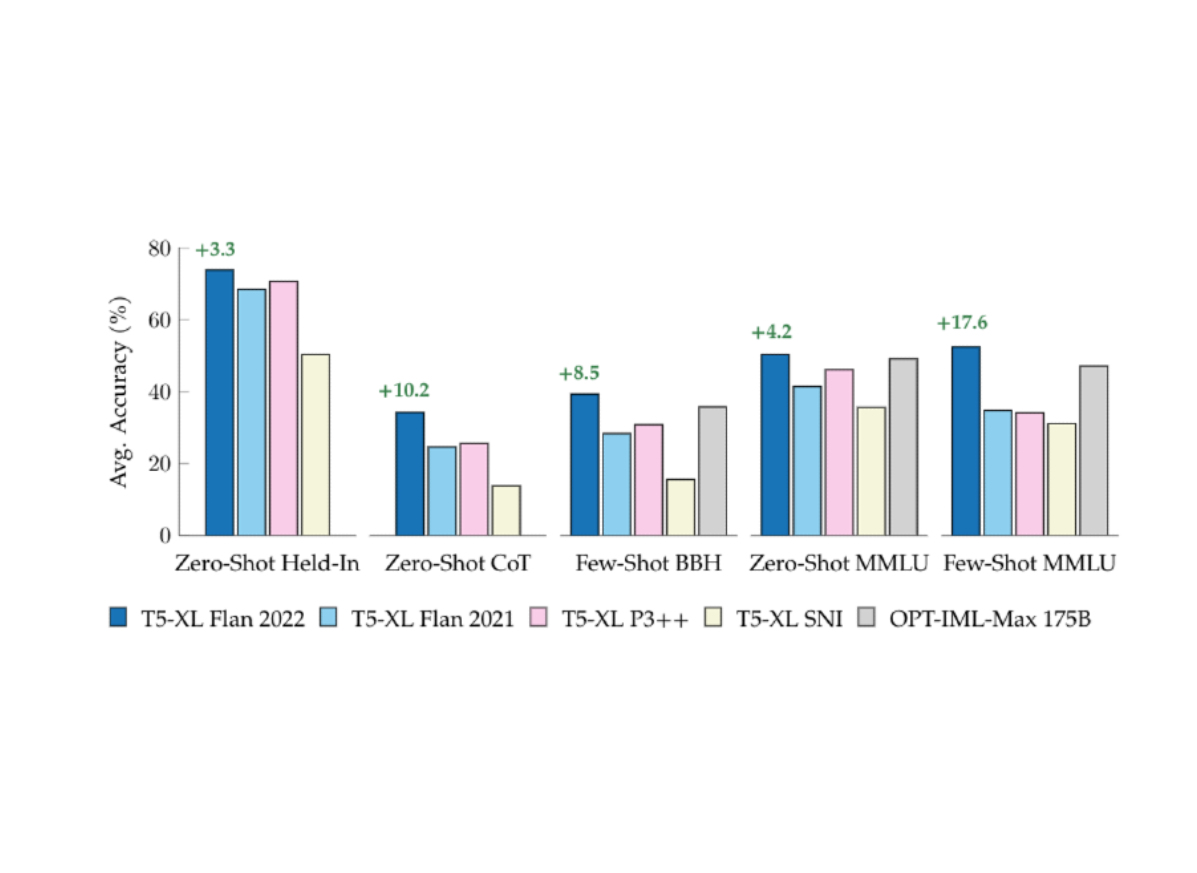
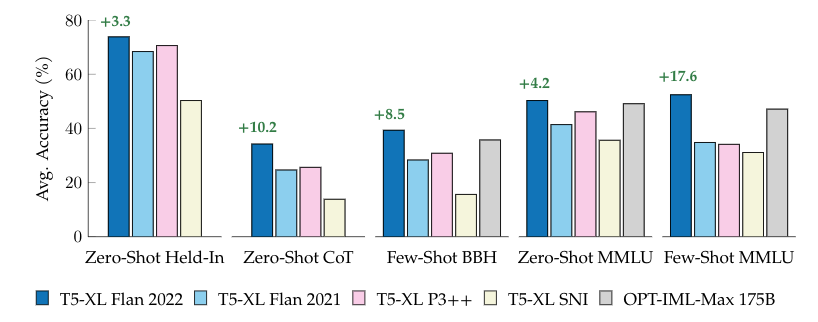 |
| مقایسه مجموعههای تنظیم دستورالعمل عمومی در مجموعههای ارزیابی نگهداشتهشده، زنجیرهای از فکر، و نگهداریشده، مانند BigBench Hard و MMLU. همه مدل ها به جز OPT-IML-Max (175B) توسط ما آموزش داده شده اند و از T5-XL با پارامترهای 3B استفاده می کنند. متن سبز نشان دهنده بهبود نسبت به بهترین مدل بعدی T5-XL (3B) است. |
تنظیم دقیق تک کار
در تنظیمات کاربردی، پزشکان معمولاً مدلهای NLP را بهطور دقیق برای یک کار هدف، جایی که دادههای آموزشی از قبل در دسترس است، به کار میگیرند. ما این تنظیم را بررسی میکنیم تا بفهمیم که چگونه Flan-T5 با مدلهای T5 به عنوان نقطه شروع برای پزشکان کاربردی مقایسه میشود. سه تنظیمات با هم مقایسه می شوند: تنظیم دقیق T5 به طور مستقیم بر روی وظیفه هدف، استفاده از Flan-T5 بدون تنظیم دقیق بیشتر در کار هدف، و تنظیم دقیق Flan-T5 در وظیفه هدف. برای کارهای نگهداشتهشده و نگهداشتهشده، تنظیم دقیق Flan-T5 نسبت به تنظیم دقیق T5 به طور مستقیم پیشرفتهایی را ارائه میدهد. در برخی موارد، معمولاً جایی که داده های آموزشی برای یک کار هدف محدود است، Flan-T5 بدون تنظیم دقیق بیشتر از T5 بهتر عمل می کند. با تنظیم دقیق مستقیم
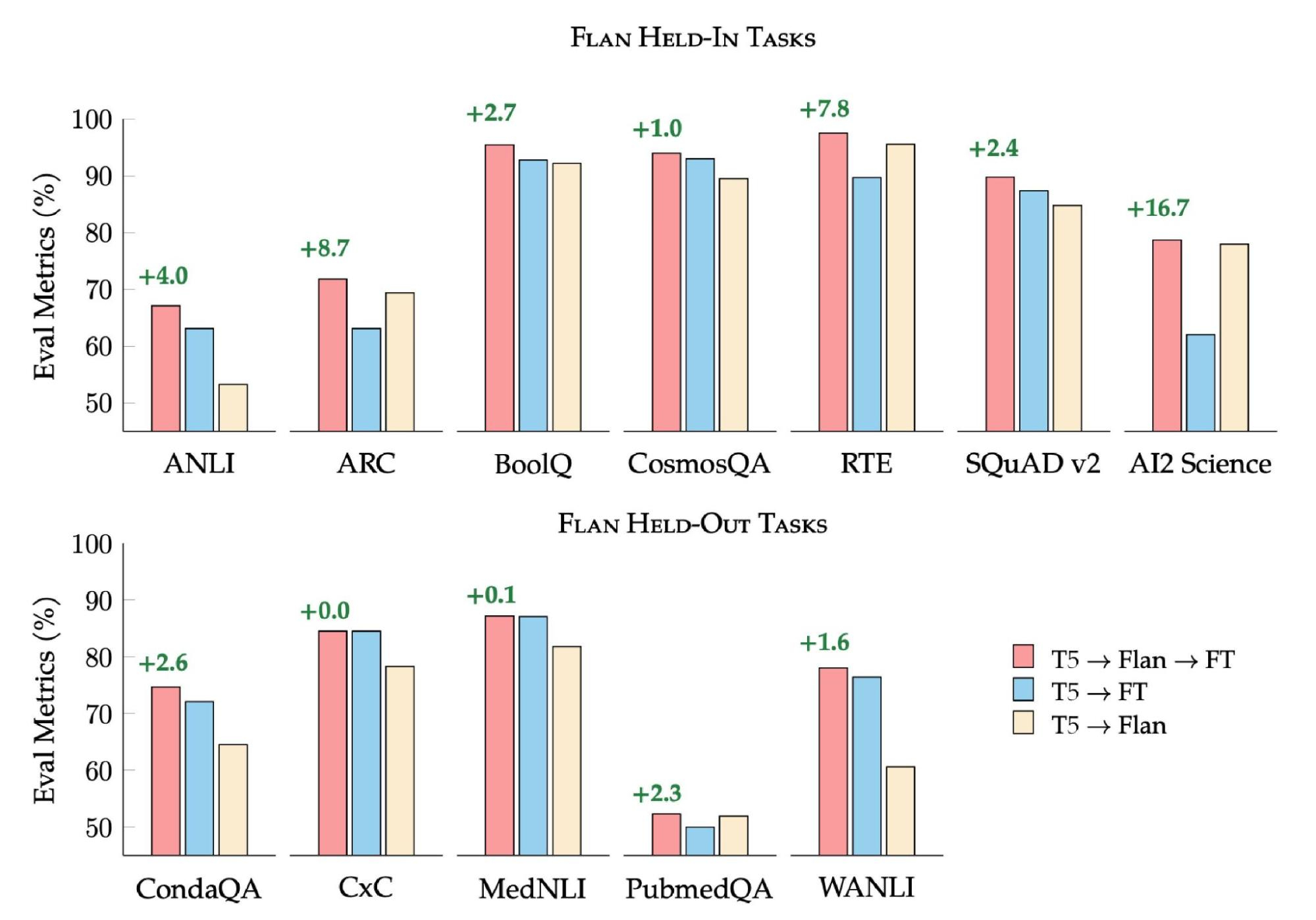 |
| Flan-T5 در تنظیم دقیق تک وظیفه ای بهتر از T5 عمل می کند. ما T5 با تنظیم دقیق تک کاره (نوارهای آبی)، Flan-T5 با تنظیم دقیق تک کاره (قرمز) و Flan-T5 را بدون هیچ تنظیم دقیق دیگری (بژ) مقایسه می کنیم. |
یک مزیت اضافی استفاده از Flan-T5 به عنوان نقطه شروع این است که آموزش به طور قابل توجهی سریعتر و ارزان تر است، سریعتر از تنظیم دقیق T5 همگرا می شود و معمولاً با دقت بالاتری به اوج می رسد. این نشان میدهد که ممکن است برای دستیابی به نتایج مشابه یا بهتر در یک کار خاص، دادههای آموزشی کمتری لازم باشد.
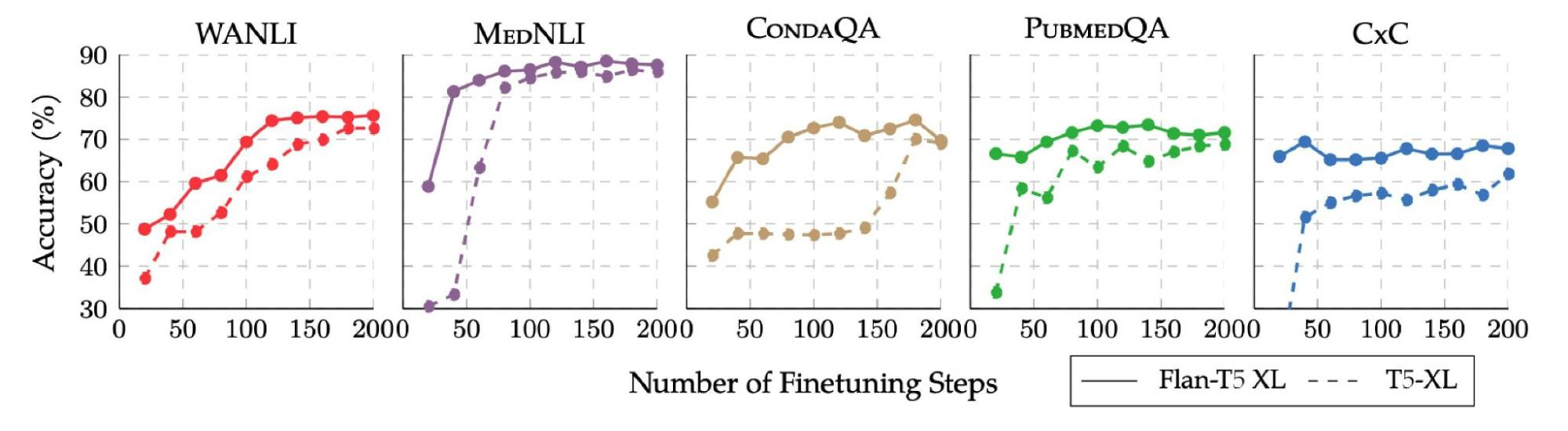 |
| Flan-T5 سریعتر از T5 در تنظیم دقیق تک کاره، برای هر یک از پنج وظیفه نگهداشته شده از Flan fine-tuning همگرا می شود. منحنی یادگیری Flan-T5 با خطوط ثابت و منحنی یادگیری T5 با خط چین نشان داده شده است. تمام وظایف در طول تنظیم دقیق Flan انجام می شود. |
مزایای بهره وری انرژی قابل توجهی برای جامعه NLP وجود دارد که مدل های تنظیم شده با دستورالعمل مانند Flan-T5 را برای تنظیم دقیق تکلیف به جای مدل های معمولی تنظیم نشده بدون دستورالعمل استفاده می کند. در حالی که تنظیم دقیق قبل از آموزش و دستورالعمل از نظر مالی و محاسباتی گران است، اما هزینهای یکباره است که معمولاً طی میلیونها دوره تنظیم دقیق بعدی مستهلک میشود، که در مجموع میتواند برای برجستهترین مدلها گرانتر شود. مدلهای تنظیمشده با دستورالعمل، راهحل امیدوارکنندهای را در کاهش قابل توجه میزان مراحل تنظیم دقیق مورد نیاز برای دستیابی به عملکرد یکسان یا بهتر ارائه میدهند.
نتیجه
مجموعه جدید تنظیم دستورالعمل Flan محبوب ترین مجموعه های عمومی قبلی و روش های آنها را یکپارچه می کند، در حالی که الگوهای جدید و پیشرفت های ساده مانند آموزش با تنظیمات سریع ترکیبی را اضافه می کند. روش بهدستآمده از دستورالعملهای Flan، P3 و Super-Natural در معیارهای نگهدارنده، زنجیرهای فکر، MMLU و BBH 3 تا 17 درصد در انواع صفر و چند شات بهتر عمل میکند. نتایج نشان میدهد که این مجموعه جدید به عنوان نقطه شروع کارآمدتری برای محققان و متخصصان علاقهمند به تعمیم دستورالعملهای جدید یا تنظیم دقیق در یک کار جدید است.
سپاسگزاریها
همکاری با Jason Wei، Barret Zoph، Le Hou، Hyung Won Chung، Tu Vu، Albert Webson، Denny Zhou و Quoc V Le در این پروژه یک افتخار بود.