
کاربردهای صنعتی یادگیری ماشین معمولاً از موارد مختلفی تشکیل شده است که روشهای داده یا توزیع ویژگیهای متفاوتی دارند. نمودارهای ناهمگن (HGs) با تعریف چندین نوع گره (برای هر نوع داده) و یال ها (برای رابطه بین اقلام داده) نمای واحدی از این سیستم های داده چندوجهی ارائه می دهند. به عنوان مثال، شبکه های تجارت الکترونیک ممکن است داشته باشند [user, product, review] گره ها یا پلتفرم های ویدئویی ممکن است داشته باشند [channel, user, video, comment] گره ها شبکه های عصبی گراف ناهمگن (HGNN) تعبیه گره ها را یاد می گیرند و روابط هر گره را در یک بردار خلاصه می کنند. با این حال، در HG های دنیای واقعی، اغلب یک مشکل عدم تعادل برچسب بین انواع مختلف گره وجود دارد. این بدان معناست که انواع گرههای کمیاب برچسب نمیتوانند از HGNNها سوء استفاده کنند، که مانع کاربرد گستردهتر HGNNها میشود.
که در “آموزش انتقال شات صفر در یک نمودار ناهمگن از طریق شبکه های انتقال دانشارائه شده در NeurIPS 2022، ما مدلی به نام شبکه انتقال دانش (KTN) را پیشنهاد میکنیم که دانش را از انواع گرههای دارای برچسب به انواع گرههای دارای برچسب صفر با استفاده از اطلاعات رابطهای غنی دادهشده در HG منتقل میکند. ما توضیح می دهیم که چگونه یک مدل HGNN را بدون نیاز به تنظیم دقیق از قبل آموزش می دهیم. KTN ها تا 140 درصد در کارهای یادگیری صفر شات بهتر از خطوط پایه یادگیری انتقالی پیشرفته هستند و می توانند برای بهبود بسیاری از مدل های HGNN موجود در این وظایف تا 24 درصد (یا بیشتر) استفاده شوند.
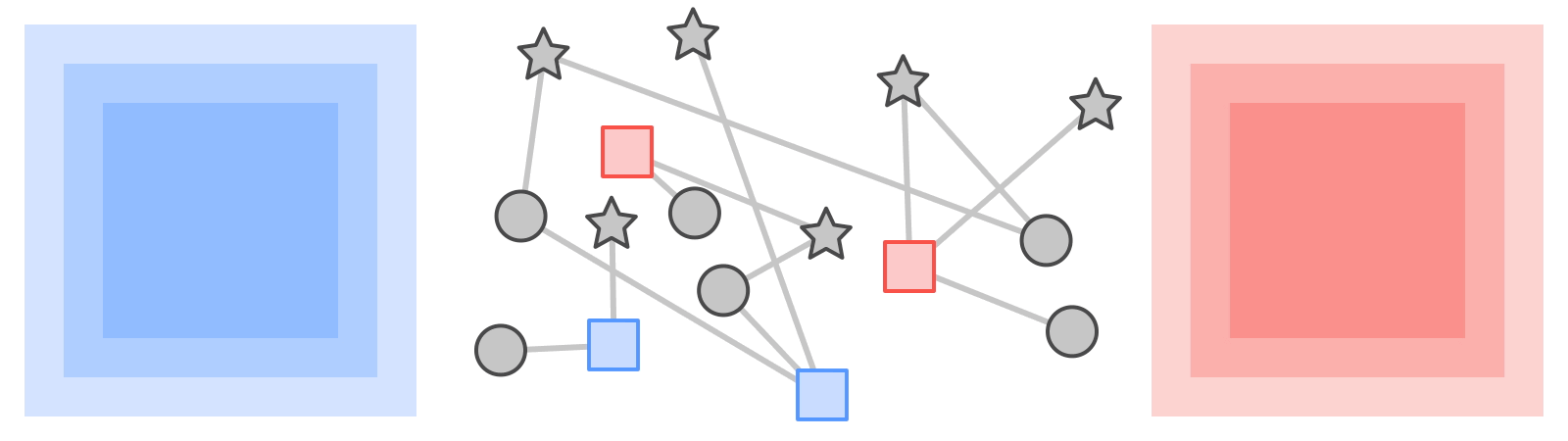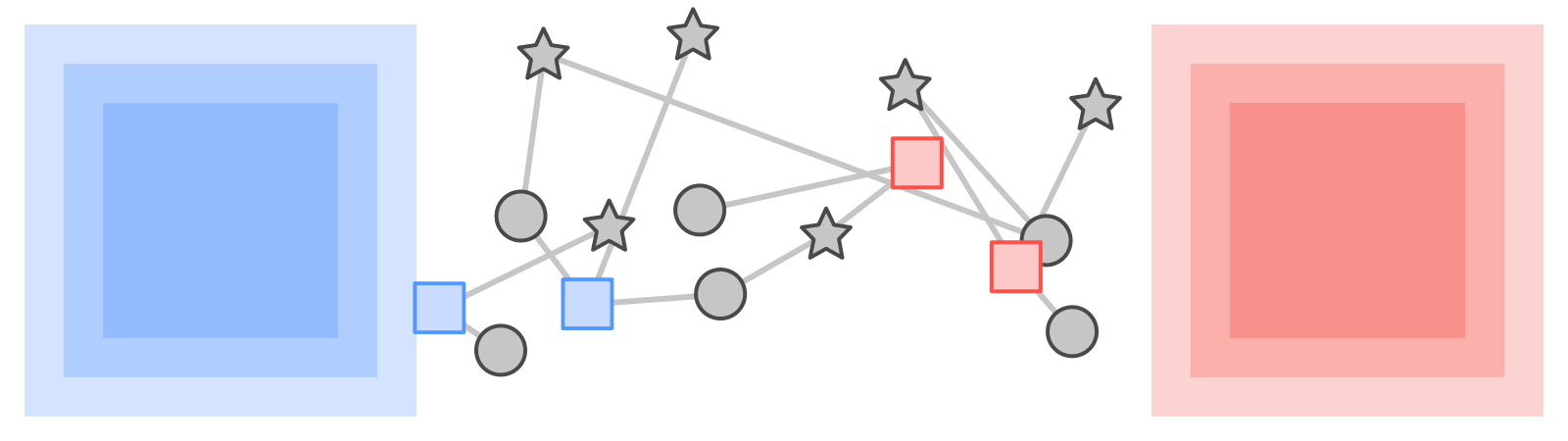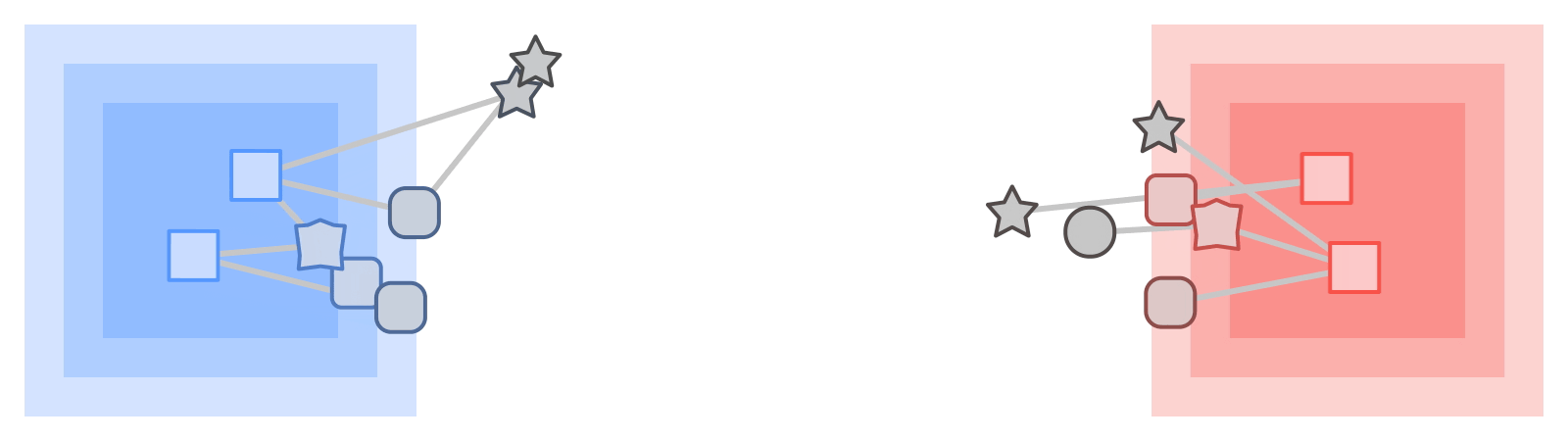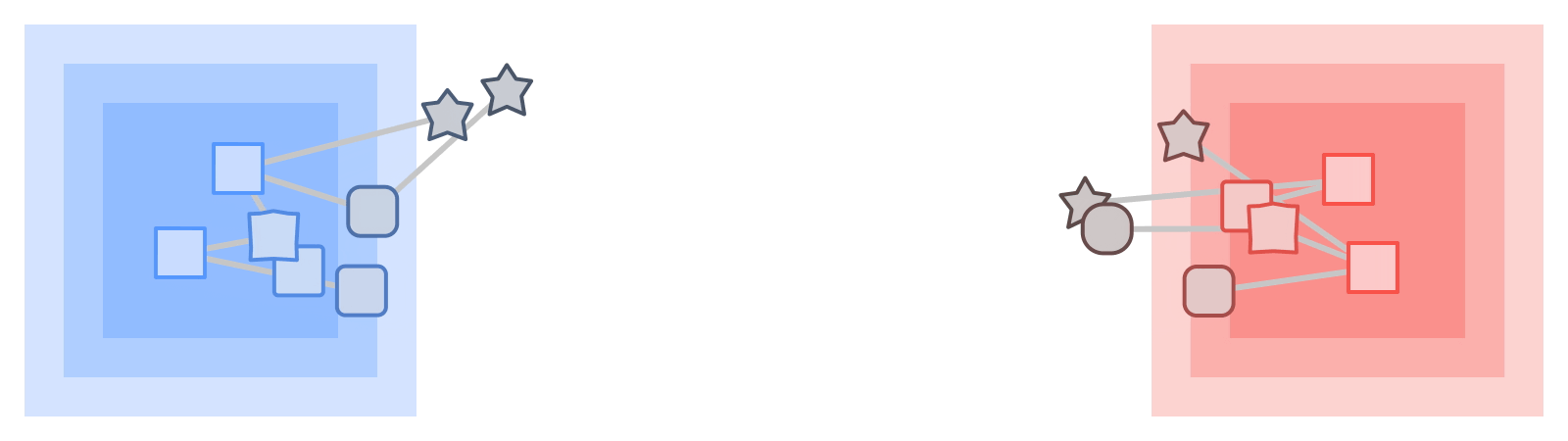 |
| KTN ها برچسب ها را از یک نوع اطلاعات تبدیل می کنند (مربع ها) از طریق یک نمودار به نوع دیگری (ستاره ها). |
گراف ناهمگن چیست؟
HG تشکیل شده است چندین نوع گره و لبه. شکل زیر یک شبکه تجارت الکترونیکی را نشان می دهد که به عنوان HG ارائه شده است. در تجارت الکترونیک، «کاربران» «محصولات» را می خرند و «نظرات» را می نویسند. یک HG این اکوسیستم را با استفاده از سه نوع گره ارائه می کند [user, product, review] و سه نوع لبه [user-buy-product, user-write-review, review-on-product]. سپس تک تک محصولات، کاربران و نظرات به عنوان گره و روابط آنها به عنوان لبه در HG با انواع گره و لبه مربوطه ارائه می شود.
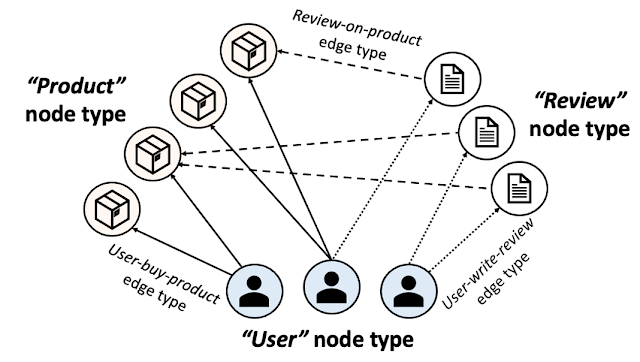 |
| نمودار ناهمگن تجارت الکترونیک |
علاوه بر تمام اطلاعات اتصال، HGs معمولا با داده می شود ویژگی های گره ورودی که اطلاعات هر گره را خلاصه می کند. ویژگیهای گره ورودی میتوانند روشهای متفاوتی در انواع مختلف گره داشته باشند. به عنوان مثال، تصاویر محصولات را می توان به عنوان ویژگی های گره ورودی برای گره های محصول، در حالی که متن را می توان به عنوان ویژگی های ورودی برای بررسی گره ها ارائه داد. برچسب های گره (به عنوان مثال، دسته هر محصول یا دسته ای که بیشتر به هر کاربر علاقه مند است) چیزی است که می خواهیم در هر گره پیش بینی کنیم.
HGNN ها و مسائل مربوط به کمبود برچسب
HGNN ها محاسبه می کنند تعبیه گره ها که ساختارهای محلی هر گره (از جمله گره و اطلاعات همسایه آن) را خلاصه می کند. این جاسازی گره ها توسط یک طبقه بندی کننده برای پیش بینی برچسب هر گره استفاده می شود. برای آموزش یک مدل HGNN و یک طبقهبندی کننده برای پیشبینی برچسبها برای یک نوع گره خاص، به مقدار مناسبی از برچسبها برای نوع نیاز داریم.
یک مسئله رایج در کاربردهای صنعتی یادگیری عمیق، کمبود برچسب است، و با انواع گره های متنوع، HGNN ها حتی بیشتر با این چالش مواجه می شوند. به عنوان مثال، انواع گره های محتوای در دسترس عموم (به عنوان مثال، گره های محصول) به وفور برچسب گذاری می شوند، در حالی که برچسب های گره های کاربر یا حساب ممکن است به دلیل محدودیت های حریم خصوصی در دسترس نباشند. این بدان معناست که در اکثر تنظیمات آموزشی استاندارد، مدلهای HGNN فقط میتوانند استنباطهای خوبی برای چند نوع گره با برچسب فراوان داشته باشند و معمولاً نمیتوانند برای هیچ نوع گره باقیمانده استنتاج کنند (با توجه به عدم وجود برچسب برای آنها).
انتقال یادگیری بر روی نمودارهای ناهمگن
یادگیری انتقال شات صفر تکنیکی است که برای بهبود عملکرد یک مدل در a هدف دامنه بدون برچسب با استفاده از دانش آموخته شده توسط مدل از یکی دیگر از افراد مرتبط منبع دامنه با داده های برچسب گذاری شده کافی برای اعمال یادگیری انتقال برای حل این مشکل کمبود برچسب برای انواع گره های خاص در HG ها، دامنه هدف، انواع گره با برچسب صفر خواهد بود. سپس دامنه منبع چه خواهد بود؟ کار قبلی معمولاً دامنه منبع را به عنوان همان نوع گرههایی که در HG متفاوتی قرار دارند تنظیم میکند، با این فرض که آن گرهها به وفور برچسبگذاری شدهاند. این یادگیری انتقال گراف به گراف رویکرد یک مدل HGNN را روی HG خارجی از قبل آموزش میدهد و سپس مدل را روی HG اصلی (که دارای برچسب کمیاب است) اجرا میکند.
با این حال، این رویکردها به سه دلیل در بسیاری از سناریوهای دنیای واقعی قابل اجرا نیستند. اول، هر HG خارجی که می تواند در تنظیمات یادگیری انتقال گراف به گراف استفاده شود، تقریباً مطمئناً چنین خواهد بود اختصاصیبنابراین، احتمالاً در دسترس نیست. دوم، حتی اگر پزشکان بتوانند به HG خارجی دسترسی داشته باشند، بعید است توزیع آن منبع HG به اندازه کافی HG هدف خود را برای اعمال یادگیری انتقالی مطابقت خواهند داد. در نهایت، انواع گره از کمبود برچسب احتمالاً در سایر HGها نیز با همین مشکل مواجه می شوند (مثلاً مسائل مربوط به حریم خصوصی در گره های کاربر).
رویکرد ما: انتقال یادگیری بین انواع گره ها در یک گراف ناهمگن
در اینجا، ما یک دامنه منبع کاربردی تر را روشن می کنیم، انواع گره های دیگر با برچسب های فراوان که روی همان HG قرار دارند. به جای استفاده از HG های اضافی، ما دانش را در یک HG واحد (که فرض می شود به طور کامل متعلق به پزشکان است) در انواع مختلف گره ها منتقل می کنیم. به طور خاص، ما یک مدل HGNN و یک طبقهبندی کننده را بر روی یک نوع گره با برچسب فراوان (منبع) از قبل آموزش میدهیم، سپس از مدلها در انواع گرههای دارای برچسب صفر (هدف) واقع در همان HG بدون تنظیم دقیق اضافی، دوباره استفاده میکنیم. یکی از الزامات این است که انواع گره منبع و هدف دارای مجموعه برچسب یکسانی باشند (به عنوان مثال، در تجارت الکترونیک HG، گرههای محصول دارای مجموعه برچسبهایی هستند که دستههای محصول را توصیف میکنند، و گرههای کاربر همان مجموعه برچسبهایی را به اشتراک میگذارند که دستههای خرید مورد علاقهشان را توصیف میکند). .
چرا چالش برانگیز است؟
متأسفانه، نمیتوانیم مستقیماً از HGNN و طبقهبندیکننده از پیش آموزشدیده در نوع گره هدف مجدداً استفاده کنیم. یکی از ویژگی های مهم معماری HGNN این است که آنها از ماژول های تخصصی برای هر نوع گره تشکیل شده اند تا به طور کامل تعدد HG ها را یاد بگیرند. HGNN ها از مجموعه های مجزایی از ماژول ها برای محاسبه جاسازی ها برای هر نوع گره استفاده می کنند. در شکل زیر، ماژول های آبی و قرمز رنگ به ترتیب برای محاسبه جاسازی گره ها برای نوع گره مبدا و هدف استفاده می شوند.
 |
| HGNN ها از ماژول های تخصصی برای هر نوع گره تشکیل شده اند و از مجموعه های مجزایی از ماژول ها برای محاسبه جاسازی انواع گره های مختلف استفاده می کنند. جزئیات بیشتر را می توان در مقاله یافت. |
در حالی که HGNN های پیش از آموزش در نوع گره منبع، ماژول های اختصاصی منبع در HGNN ها به خوبی آموزش داده شده اند، با این حال، ماژول های خاص هدف کمتر آموزش دیده اند، زیرا فقط مقدار کمی از گرادیان ها در آنها جریان دارد. این در زیر نشان داده شده است، جایی که می بینیم که هنجار شیب L2 برای انواع گره های هدف (یعنی Mtt) بسیار کمتر از انواع منبع (یعنی Mss). در این مورد، یک مدل HGNN، تعبیه گره های ضعیفی را برای نوع گره هدف خروجی می دهد، که منجر به عملکرد ضعیف کار می شود.
 |
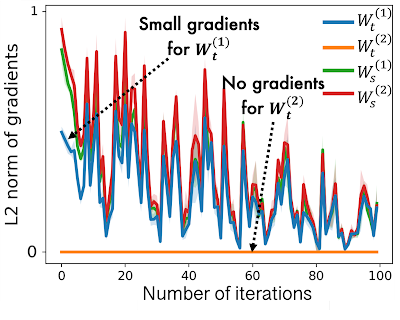 |
| در HGNN ها، ماژول های نوع خاص هدف، صفر یا فقط مقدار کمی گرادیان را در طول پیش آموزش روی نوع گره منبع دریافت می کنند که منجر به عملکرد ضعیف در نوع گره هدف می شود. |
KTN: آموزش انتقال از نوع متقاطع برای HGNN ها
کار ما بر تغییر شکل تعبیههای گره هدف (ضعیف) محاسبه شده توسط یک مدل HGNN از پیش آموزشدیده برای دنبال کردن توزیع جاسازیهای گره منبع متمرکز است. سپس طبقهبندیکنندهای که از قبل بر روی نوع گره منبع آموزش داده شده است، میتواند دوباره برای آن استفاده شود هدف نوع گره چگونه می توانیم جاسازی های گره هدف را به دامنه منبع نگاشت کنیم؟ برای پاسخ به این سوال، بررسی می کنیم که چگونه HGNN ها تعبیه گره ها را برای یادگیری رابطه بین توزیع های منبع و هدف محاسبه می کنند.
HGNN ها جاسازی های گره متصل را جمع می کنند تا جاسازی های گره هدف را در هر لایه تقویت کنند. به عبارت دیگر، جاسازیهای گره برای هر دو نوع گره منبع و هدف با استفاده از ورودی یکسان بهروزرسانی میشوند – جاسازیهای گره لایه قبلی از هر نوع گره متصل. این بدان معنی است که آنها می توانند توسط یکدیگر نشان داده شوند. ما این رابطه را از نظر تئوری اثبات می کنیم و متوجه می شویم که یک ماتریس نگاشت (تعریف شده توسط پارامترهای HGNN) از دامنه هدف به حوزه منبع وجود دارد (جزئیات بیشتر در قضیه 1 در مقاله). بر اساس این قضیه، یک شبکه عصبی کمکی را معرفی می کنیم که از آن به عنوان a یاد می کنیم شبکه انتقال دانش (KTN)، که جاسازی های گره هدف را دریافت می کند و سپس آنها را با ضرب آنها با یک ماتریس نگاشت (قابل آموزش) تبدیل می کند. سپس یک تنظیم کننده تعریف می کنیم که همراه با کاهش عملکرد در مرحله قبل از آموزش برای آموزش KTN به حداقل می رسد. در زمان آزمایش، جاسازیهای هدف محاسبهشده از HGNN از قبل آموزشدیدهشده را به حوزه منبع با استفاده از KTN آموزشدیده برای طبقهبندی نقشهبرداری میکنیم.
 |
| در HGNN ها، تعبیه گره های نهایی هر دو نوع منبع و هدف از توابع ریاضی مختلف محاسبه می شوند.f(): منبع، g(): target) که از ورودی یکسانی استفاده می کنند – تعبیه گره های لایه قبلی. |
نتایج تجربی
برای بررسی اثربخشی KTN ها، ما 18 کار مختلف یادگیری انتقال شات صفر را روی دو نمودار ناهمگن عمومی، Open Academic Graph و Pubmed اجرا کردیم. ما KTN را با هشت روش یادگیری انتقال پیشرفته مقایسه می کنیم (DAN، JAN، DANN، CDAN، CDAN-E، WDGRL، LP، EP). در زیر نشان داده شده است، KTN به طور مداوم از تمام خطوط پایه در همه کارها بهتر عمل می کند، و تا 140٪ از خطوط پایه یادگیری انتقالی پیشی می گیرد (همانطور که با سود تجمعی با تخفیف عادی، یک معیار رتبه بندی اندازه گیری می شود).
 |
 |
| یادگیری انتقال شات صفر بر روی مجموعه دادههای Open Academic Graph (OAG-CS) و Pubmed. رنگها نشاندهنده دستههای مختلفی از خطوط پایه یادگیری انتقال هستند که نتایج با آن مقایسه میشوند. رنگ زرد: از ویژگی های آماری (مثلاً میانگین، واریانس) توزیع ها استفاده کنید. سبز: از مدل های متخاصم برای انتقال دانش استفاده کنید. نارنجی: انتقال دانش به طور مستقیم از طریق ساختار گراف با استفاده از انتشار برچسب. |
مهمتر از همه، KTN را می توان تقریباً برای تمام مدل های HGNN که دارای پارامترهای نوع گره و لبه خاص هستند و عملکرد صفر شات خود را در دامنه های هدف بهبود می بخشد. همانطور که در زیر نشان داده شده است، KTN دقت را در انواع گره های دارای برچسب صفر در شش مدل مختلف HGNN (R-GCN، HAN، HGT، MAGNN، MPNN، H-MPNN) تا 190٪ بهبود می بخشد.
 |
| KTN را می توان در شش مدل مختلف HGNN اعمال کرد و عملکرد صفر شات آنها را در دامنه های هدف بهبود بخشید. |
غذای آماده
اکوسیستم های مختلف در صنعت را می توان به صورت نمودارهای ناهمگن ارائه کرد. HGNN ها اطلاعات گراف ناهمگن را در نمایش های موثر خلاصه می کنند. با این حال، مسائل کمبود برچسب در انواع خاصی از گره ها مانع از کاربرد گسترده تر HGNN ها می شود. در این پست، KTN، اولین روش یادگیری انتقال متقاطع طراحی شده برای HGNN را معرفی کردیم. با KTN، ما می توانیم به طور کامل از غنای نمودارهای ناهمگن از طریق HGNN بدون توجه به کمبود برچسب بهره برداری کنیم. برای جزئیات بیشتر به مقاله مراجعه کنید.
سپاسگزاریها
این مقاله کار مشترکی با جان پالوویچ (Google Research)، داستین زله (Google Research)، زینیو هو (Intern، Google Research) و Russ Salakhutdinov (CMU) است. ما از تام اسمال برای خلق فیگور متحرک در این پست وبلاگ تشکر می کنیم.