یادگیری ربات برای طیف وسیعی از وظایف چالش برانگیز دنیای واقعی، از جمله دستکاری ماهرانه، حرکت پاها، و گرفتن استفاده شده است. کمتر رایج است که ببینیم یادگیری ربات برای کارهای پویا و با شتاب بالا که نیاز به تعامل انسان و ربات با حلقه محکم دارند، مانند تنیس روی میز، اعمال می شود. دو ویژگی مکمل تکلیف تنیس روی میز وجود دارد که آن را برای تحقیقات یادگیری رباتیک جالب می کند. اول، این کار هم به سرعت و هم به دقت نیاز دارد، که الزامات قابل توجهی را برای الگوریتم یادگیری ایجاد می کند. در عین حال، مشکل بسیار ساختار یافته (با یک محیط ثابت و قابل پیش بینی) و به طور طبیعی چند عاملی است (ربات می تواند با انسان یا ربات دیگری بازی کند)، و آن را به بستر آزمایشی مطلوبی برای بررسی سؤالات در مورد تعامل انسان و ربات تبدیل می کند. یادگیری تقویتی این ویژگی ها باعث شده است که چندین گروه تحقیقاتی سکوهای تحقیقاتی تنیس روی میز را توسعه دهند [1, 2, 3, 4].
تیم Robotics در گوگل چنین پلتفرمی را برای مطالعه مشکلات ناشی از یادگیری رباتیک در یک محیط چند نفره، پویا و تعاملی ساخته است. در ادامه این پست دو پروژه Iterative-Sim2Real (که در CoRL 2022 ارائه خواهد شد) و GoalsEye (IROS 2022) را معرفی می کنیم که مشکلاتی را که ما تاکنون بررسی کرده ایم را نشان می دهد. Iterative-Sim2Real یک ربات را قادر می سازد تا رالی هایی با بیش از 300 ضربه با یک بازیکن انسانی برگزار کند، در حالی که GoalsEye یادگیری سیاست های مشروط هدف را امکان پذیر می کند که با دقت انسان های آماتور مطابقت دارد.
| سیاست های تکرار شونده-Sim2Real که با انسان ها همکاری می کنند (بالا) و یک خط مشی GoalsEye که توپ ها را به مکان های مختلف برمی گرداند (پایین). |
Iterative-Sim2Real: استفاده از یک شبیه ساز برای بازی با انسان ها
در این پروژه هدف برای ربات است تعاونی در طبیعت: برای انجام یک تجمع با یک انسان تا زمانی که ممکن است. از آنجایی که تمرین مستقیم علیه یک بازیکن انسانی در دنیای واقعی خسته کننده و زمان بر است، ما یک رویکرد مبتنی بر شبیه سازی (یعنی سیم به واقعی) را اتخاذ می کنیم. با این حال، از آنجایی که شبیه سازی رفتار انسان به طور دقیق دشوار است، به کارگیری یادگیری از طریق شبیه به واقعی برای کارهایی که نیاز به تعامل نزدیک و نزدیک با یک شرکت کننده انسانی دارند، دشوار است.
در Iterative-Sim2Real، (یعنی i-S2R)، ما روشی را برای یادگیری مدلهای رفتار انسان برای وظایف تعامل انسان و ربات ارائه میکنیم و آن را بر روی پلتفرم رباتیک تنیس روی میز خود نشان میدهیم. ما سیستمی ساختهایم که میتواند تا 340 ضربه را با یک بازیکن آماتور انسان (نشان داده شده در زیر) به دست آورد.
| رالی 340 ضربه که بیش از 4 دقیقه طول کشید. |
یادگیری مدل های رفتار انسان: مشکل مرغ و تخم مرغ
مشکل اصلی در یادگیری مدلهای دقیق رفتار انسان برای رباتیک به شرح زیر است: اگر برای شروع یک خطمشی مناسب برای ربات نداشته باشیم، نمیتوانیم دادههای با کیفیت بالا در مورد نحوه تعامل یک فرد با ربات جمعآوری کنیم. اما بدون مدل رفتار انسانی، نمیتوانیم در وهله اول سیاستهای ربات را بدست آوریم. یک جایگزین می تواند آموزش مستقیم یک خط مشی روبات در دنیای واقعی باشد، اما این اغلب آهسته، مقرون به صرفه است و چالش های مرتبط با ایمنی را به همراه دارد که با مشارکت مردم تشدید می شود. i-S2R که در زیر نمایش داده شده است، راه حلی برای این مشکل مرغ و تخم مرغ است. از یک مدل ساده از رفتار انسان به عنوان یک نقطه شروع تقریبی استفاده می کند و بین آموزش شبیه سازی و استقرار در دنیای واقعی متناوب است. در هر تکرار، هم مدل رفتار انسانی و هم خط مشی اصلاح می شود.
 |
| روش i-S2R. |
نتایج
برای ارزیابی i-S2R، ما فرآیند تمرین را پنج بار با پنج حریف مختلف انسانی تکرار کردیم و آن را با رویکرد پایه معمولی سیم به واقعی به همراه تنظیم دقیق (S2R+FT) مقایسه کردیم. وقتی در همه بازیکنان جمع شود، طول رالی i-S2R حدود 9٪ (در پایین سمت چپ) از S2R+FT بیشتر است. هیستوگرام طول رالی برای i-S2R و S2R+FT (در پایین سمت راست) نشان میدهد که بخش بزرگی از رالیها برای S2R+FT کوتاهتر هستند (یعنی کمتر از 5)، در حالی که i-S2R بیشتر به رالیهای طولانیتر میرسد. .
 |
| خلاصه نتایج i-S2R. جزئیات باکس پلات: دایره سفید میانگین، خط افقی وسط، کران جعبه صدک 25 و 75 است. |
ما همچنین نتایج را بر اساس نوع بازیکن تقسیم می کنیم: مبتدی (40٪ بازیکنان)، متوسط (40٪ بازیکنان) و پیشرفته (20٪ بازیکنان). می بینیم که i-S2R به طور قابل توجهی از S2R+FT برای بازیکنان مبتدی و متوسط (۸۰٪ بازیکنان) بهتر عمل می کند.
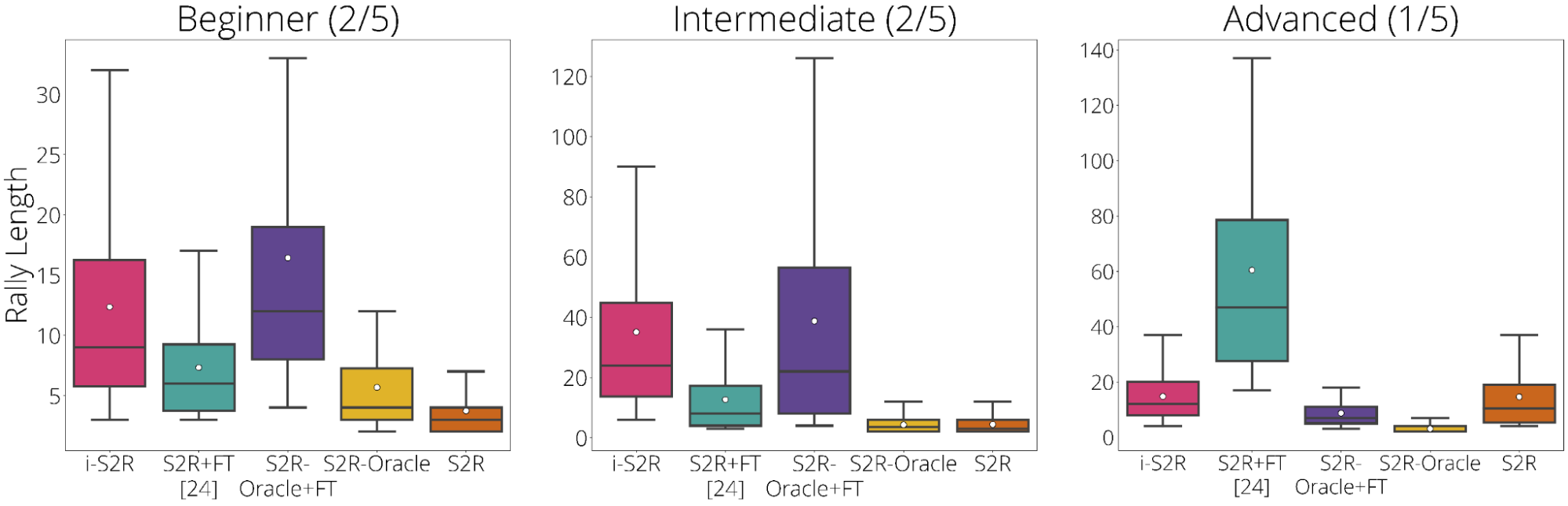 |
| نتایج i-S2R بر اساس نوع پخش کننده. |
جزئیات بیشتر درباره i-S2R را میتوانید در پیشچاپ، وبسایت ما و همچنین در ویدیوی خلاصه زیر پیدا کنید.
GoalsEye: آموزش برگرداندن توپ ها دقیقاً در یک ربات فیزیکی
در حالی که ما روی یادگیری سیم به واقعی در i-S2R تمرکز کردهایم، گاهی اوقات یادگیری با استفاده از دادههای دنیای واقعی مطلوب است – بستن شکاف سیم به واقعی در این مورد غیرضروری است. یادگیری تقلید (IL) یک رویکرد ساده و پایدار برای یادگیری در دنیای واقعی ارائه می دهد، اما نیاز به دسترسی به نمایش دارد و نمی تواند از عملکرد معلم فراتر رود. جمع آوری نمایش های انسانی متخصص از هدف گیری دقیق هدف در تنظیمات سرعت بالا چالش برانگیز و گاهی غیرممکن است (به دلیل دقت محدود در حرکات انسان). در حالی که یادگیری تقویتی (RL) برای چنین کارهایی با سرعت بالا و دقت بالا مناسب است، با یک مشکل اکتشافی دشوار (مخصوصاً در ابتدای کار) مواجه است و می تواند نمونه بسیار ناکارآمد باشد. در GoalsEye، ما رویکردی را نشان میدهیم که تکنیکهای شبیهسازی رفتار اخیر را ترکیب میکند [5, 6] برای یادگیری یک خط مشی هدفمند دقیق، با شروع از یک مجموعه داده کوچک، با ساختار ضعیف و غیر هدفمند.
در اینجا ما یک کار متفاوت تنیس روی میز را با تاکید بر دقت در نظر می گیریم. ما میخواهیم ربات توپ را به یک موقعیت گل دلخواه روی میز برگرداند، به عنوان مثال «به گوشه چپ عقب ضربه بزن» یا «توپ را درست روی تور در سمت راست فرود بیاورد» (فیلم سمت چپ زیر را ببینید). علاوه بر این، ما می خواستیم روشی را پیدا کنیم که بتوان آن را اعمال کرد به طور مستقیم در محیط واقعی تنیس روی میز ما بدون هیچ شبیه سازی. ما متوجه شدیم که ترکیب دو تکنیک یادگیری تقلیدی موجود، یادگیری از بازی (LFP) و آموزش نظارت شده با هدف (GCSL)، به این تنظیمات می رسد. این به اندازه کافی ایمن و کارآمد است که بتوان یک خط مشی را روی یک ربات فیزیکی آموزش داد که به اندازه انسان های آماتور در وظیفه بازگرداندن توپ ها به اهداف خاص روی میز دقیق است.
| خط مشی GoalsEye با هدف هدف به قطر 20 سانتی متر (ترک کرد). بازیکن انسانی با هدف یکسان (درست). |
عناصر اساسی موفقیت عبارتند از:
- یک مجموعه داده “بوت استرپ” حداقل، اما غیر هدفمند ضربه زدن ربات به توپ برای غلبه بر یک مشکل اولیه دشوار اکتشاف.
- Hindsight شبیه سازی رفتاری مشروط هدف را مجدداً نشان داد (GCBC) برای آموزش یک خط مشی هدفمند برای رسیدن به هر هدفی در مجموعه داده.
- دستیابی به هدف با نظارت تکراری. عامل با تعیین اهداف تصادفی و تلاش برای دستیابی به آنها با استفاده از خط مشی فعلی به طور مداوم بهبود می یابد. همه تلاشها دوباره برچسبگذاری میشوند و به مجموعه آموزشی در حال گسترش پیوسته اضافه میشوند. این خود تمرینیکه در آن ربات داده های آموزشی را با تنظیم و تلاش برای رسیدن به اهداف گسترش می دهد، به طور مکرر تکرار می شود.
 |
| روش شناسی اهداف چشم. |
تظاهرات و خودسازی از طریق تمرین کلیدی است
سنتز تکنیک ها بسیار مهم است. هدف سیاست بازگرداندن الف است تنوع از توپ های ورودی به هر موقعیت در سمت حریف از جدول. خط مشی آموزش داده شده بر روی 2480 تظاهرات اولیه فقط در 9 درصد مواقع به 30 سانتی متر از هدف می رسد. با این حال، پس از اینکه یک خطمشی برای 13500 تلاش خود تمرین کرد، دقت دستیابی به هدف به 43% افزایش مییابد (در پایین سمت راست). این پیشرفت همانطور که در ویدیوهای زیر نشان داده شده است به وضوح قابل مشاهده است. با این حال، اگر یک خط مشی فقط به خودی خود عمل کند، آموزش در این شرایط کاملاً شکست می خورد. جالب توجه است که تعداد تظاهرات کارآیی خود تمرینی بعدی را بهبود می بخشد، البته با کاهش بازده. این نشان میدهد که دادههای نمایشی و خود تمرینی میتوانند بسته به زمان و هزینه نسبی برای جمعآوری دادههای نمایشی در مقایسه با خود تمرینی جایگزین شوند.
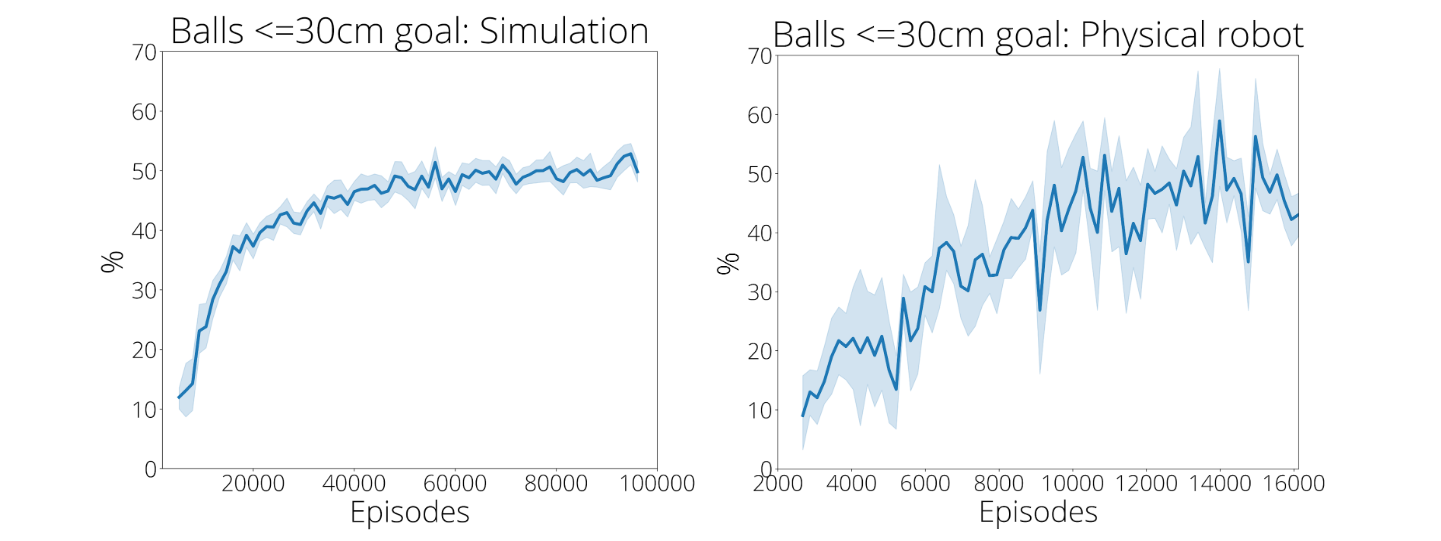 |
| خود تمرینی به طور قابل ملاحظه ای دقت را بهبود می بخشد. ترک کرد: آموزش شبیه سازی شده درست: آموزش واقعی ربات. مجموعه داده های نمایشی شامل 2500 قسمت، هم در شبیه سازی و هم در دنیای واقعی است. |
| تجسم مزایای خود تمرینی. ترک کرد: سیاست آموزش بر روی 2480 تظاهرات اولیه. درست: سیاست پس از 13500 تلاش دیگر برای خودتمرینی. |
جزئیات بیشتر در مورد GoalsEye را می توان در پیش چاپ و در وب سایت ما یافت.
نتیجه گیری و کار آینده
ما دو پروژه مکمل را با استفاده از پلت فرم تحقیقاتی رباتیک تنیس روی میز ارائه کرده ایم. i-S2R خطمشیهای RL را میآموزد که میتوانند با انسانها تعامل داشته باشند، در حالی که GoalsEye نشان میدهد که یادگیری از دادههای بدون ساختار دنیای واقعی همراه با تمرین خود نظارت برای یادگیری سیاستهای شرطی هدف در یک محیط دقیق و پویا مؤثر است.
یکی از جهتگیریهای تحقیقاتی جالبی که باید روی سکوی تنیس روی میز دنبال شود، ساخت یک ربات «مربی» است که میتواند سبک بازی خود را با توجه به سطح مهارت افراد شرکتکننده تطبیق دهد تا همه چیز را چالشبرانگیز و هیجانانگیز نگه دارد.
سپاسگزاریها
از نویسندگان همکارمان، سامیندا ابیرووان، الکس بیولی، کریستوف چورومانسکی، دیوید بی. دآمبروسیو، تیانلی دینگ، دیپالی جین، کوری لینچ، پاناگ آر. سانکتی، پیر سرمانت و آنیش شانکار تشکر می کنیم. ما همچنین از حمایت بسیاری از اعضای تیم روباتیک که در بخش های قدردانی مقالات ذکر شده اند سپاسگزاریم.