

یک رویکرد رایج برای کنترل رباتها، برنامهریزی آنها با کد برای شناسایی اشیاء، ترتیب دادن دستورات برای حرکت محرکها، و حلقههای بازخورد برای تعیین نحوه انجام یک کار توسط ربات است. در حالی که این برنامهها میتوانند گویا باشند، سیاستهای برنامهریزی مجدد برای هر کار جدید میتواند زمانبر باشد و به تخصص حوزه نیاز دارد.
چه میشود اگر وقتی دستورالعملهایی از سوی مردم داده میشود، روباتها بتوانند به طور مستقل کد خود را برای تعامل با جهان بنویسند؟ به نظر می رسد که آخرین نسل از مدل های زبان، مانند PaLM، قادر به استدلال پیچیده هستند و همچنین بر روی میلیون ها خط کد آموزش دیده اند. با توجه به دستورالعملهای زبان طبیعی، مدلهای زبان کنونی نه تنها در نوشتن کدهای عمومی، بلکه، همانطور که کشف کردیم، کدهایی که میتوانند اقدامات ربات را نیز کنترل کنند، مهارت بالایی دارند. هنگامی که چندین دستورالعمل نمونه (قالببندی شده به عنوان نظرات) همراه با کد مربوطه (از طریق یادگیری درون متنی) ارائه شود، مدلهای زبان میتوانند دستورالعملهای جدیدی را دریافت کنند و بهطور مستقل کد جدیدی تولید کنند که فراخوانهای API را مجدداً ترکیب میکند، توابع جدید را ترکیب میکند و حلقههای بازخورد را بیان میکند. برای جمع آوری رفتارهای جدید در زمان اجرا. به طور گسترده تر، این یک رویکرد جایگزین برای استفاده از یادگیری ماشین برای ربات ها را پیشنهاد می کند که (i) تعمیم را از طریق مدولار بودن دنبال می کند و (ii) از فراوانی کد منبع باز و داده های موجود در اینترنت استفاده می کند.
 |
| کد داده شده برای یک کار مثال (ترک کرد، مدل های زبان می توانند دوباره فراخوانی های API را برای جمع آوری رفتارهای ربات جدید برای کارهای جدید ترکیب کنند (درست) که از توابع یکسان اما به روش های مختلف استفاده می کنند. |
برای بررسی این امکان، کد به عنوان سیاست (CaP) را توسعه دادیم، یک فرمول ربات محور از برنامه های تولید شده توسط مدل زبان که بر روی سیستم های فیزیکی اجرا می شوند. CaP کار قبلی ما، PaLM-SayCan را با امکان دادن به مدلهای زبانی برای تکمیل وظایف رباتیک پیچیدهتر با بیان کامل کدهای همه منظوره پایتون گسترش میدهد. با CaP، ما استفاده از مدلهای زبان را برای نوشتن مستقیم کد ربات از طریق چند شات پیشنهاد میکنیم. آزمایشهای ما نشان میدهد که کد خروجی منجر به بهبود تعمیم و عملکرد کار نسبت به یادگیری مستقیم وظایف ربات و خروجی کردن اقدامات زبان طبیعی شده است. CaP به یک سیستم واحد اجازه می دهد تا انواع مختلفی از وظایف رباتیک پیچیده و متنوع را بدون آموزش خاص انجام دهد.
روشی متفاوت برای تفکر در مورد تعمیم ربات
برای تولید کد برای یک کار جدید با دستورالعملهای زبان طبیعی، CaP از یک مدل زبان کدنویسی استفاده میکند که وقتی با راهنماییها (یعنی عبارتهای وارد کردن که اطلاع میدهند کدام API در دسترس هستند) و مثالهایی (جفتهای دستورالعمل به کد که تعداد کمی ارائه میدهند) از آن خواسته میشود استفاده میکند. -شات “نمایش” نحوه تبدیل دستورالعمل ها به کد)، کد جدیدی را برای دستورالعمل های جدید می نویسد. محور این رویکرد است تولید کد سلسله مراتبی، که مدل های زبان را وادار می کند تا به صورت بازگشتی توابع جدید را تعریف کنند، کتابخانه های خود را در طول زمان جمع آوری کنند و یک پایگاه کد پویا را خود معماری کنند. تولید کد سلسله مراتبی، پیشرفته ترین فناوری را در زمینه رباتیک و همچنین معیارهای استاندارد ژن کد در زیر فیلدهای پردازش زبان طبیعی (NLP) با 39.8% pass@1 در HumanEval، معیاری از مشکلات کدنویسی دست نویس که برای اندازه گیری صحت عملکردی برنامه های سنتز شده
مدلهای زبان کدنویسی میتوانند انواع عملیات حسابی و حلقههای بازخورد مبتنی بر زبان را بیان کنند. برنامههای مدل زبان پایتونیک میتوانند از ساختارهای منطقی کلاسیک، به عنوان مثال، دنبالهها، انتخاب (if/else)، و حلقهها (for/while) برای جمعآوری رفتارهای جدید در زمان اجرا استفاده کنند. آنها همچنین می توانند از کتابخانه های شخص ثالث برای درون یابی نقاط (NumPy)، تجزیه و تحلیل و تولید اشکال (Shapely) برای استدلال فضایی-هندسی و غیره استفاده کنند. این مدل ها نه تنها به دستورالعمل های جدید تعمیم می دهند، بلکه می توانند مقادیر دقیق (مثلاً سرعت ها) را نیز ترجمه کنند. ) به توصیف های مبهم (“سریع تر” و “به سمت چپ”) بسته به زمینه برای استخراج عقل سلیم رفتاری.
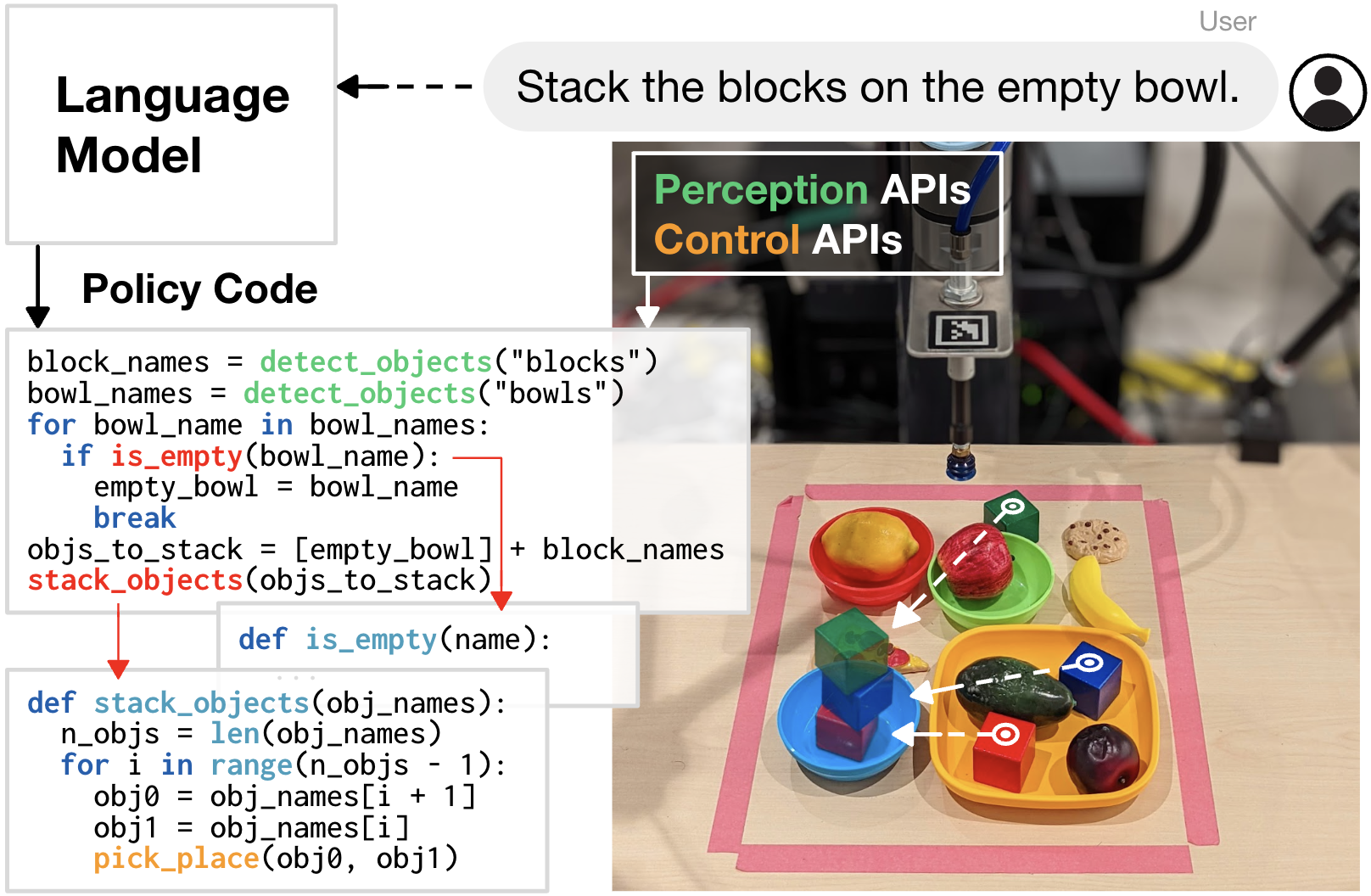 |
| Code as Policies از مدلهای زبان کدنویسی برای نگاشت دستورالعملهای زبان طبیعی به کد روبات برای تکمیل وظایف استفاده میکند. کد تولید شده میتواند APIهای عملکرد ادراک موجود، کتابخانههای شخص ثالث را فراخوانی کند یا توابع جدیدی را در زمان اجرا بنویسد. |
CaP در یک لایه خاص در ربات تعمیم می یابد: تفسیر دستورالعمل های زبان طبیعی، پردازش خروجی های ادراک (به عنوان مثال، از آشکارسازهای شی خارج از قفسه)، و سپس پارامترهای اولیه کنترل. این در سیستمهایی با ادراک و کنترل فاکتوری متناسب میشود و درجهای از تعمیم (که از مدلهای زبانی از پیش آموزشدیده به دست آمده) را بدون حجم جمعآوری دادههای مورد نیاز برای یادگیری رباتهای سرتاسر به ارمغان میآورد. Cap همچنین قابلیتهای مدل زبانی را به ارث میبرد که با کدنویسی مرتبط نیستند، مانند پشتیبانی از دستورالعملها با زبانهای غیر انگلیسی و ایموجیها.
 |
| CaP قابلیتهای مدلهای زبان مانند پشتیبانی چند زبانه و شکلک را به ارث میبرد. |
با مشخص کردن انواع تعمیمهایی که در مشکلات تولید کد با آن مواجه میشوند، میتوانیم همچنین بررسی کنیم که چگونه تولید کد سلسله مراتبی باعث بهبود تعمیم میشود. به عنوان مثال، “سیستماتیک” توانایی ترکیب مجدد قطعات شناخته شده برای تشکیل دنباله های جدید را ارزیابی می کند، “جایگزینی” استحکام را به قطعات کد مترادف ارزیابی می کند، در حالی که “بهره وری” توانایی نوشتن کد خط مشی طولانی تر از آنچه در مثال ها دیده می شود را ارزیابی می کند. وظایف افق بلند جدید که ممکن است نیاز به تعریف و تودرتو توابع جدید داشته باشند). مقاله ما یک معیار منبع باز جدید برای ارزیابی مدل های زبان در مجموعه ای از مشکلات تولید کد مرتبط با رباتیک ارائه می دهد. با استفاده از این معیار، متوجه میشویم که بهطور کلی، مدلهای بزرگتر در بیشتر معیارها عملکرد بهتری دارند و تولید کد سلسله مراتبی، تعمیم «بهرهوری» را بیشتر بهبود میبخشد.
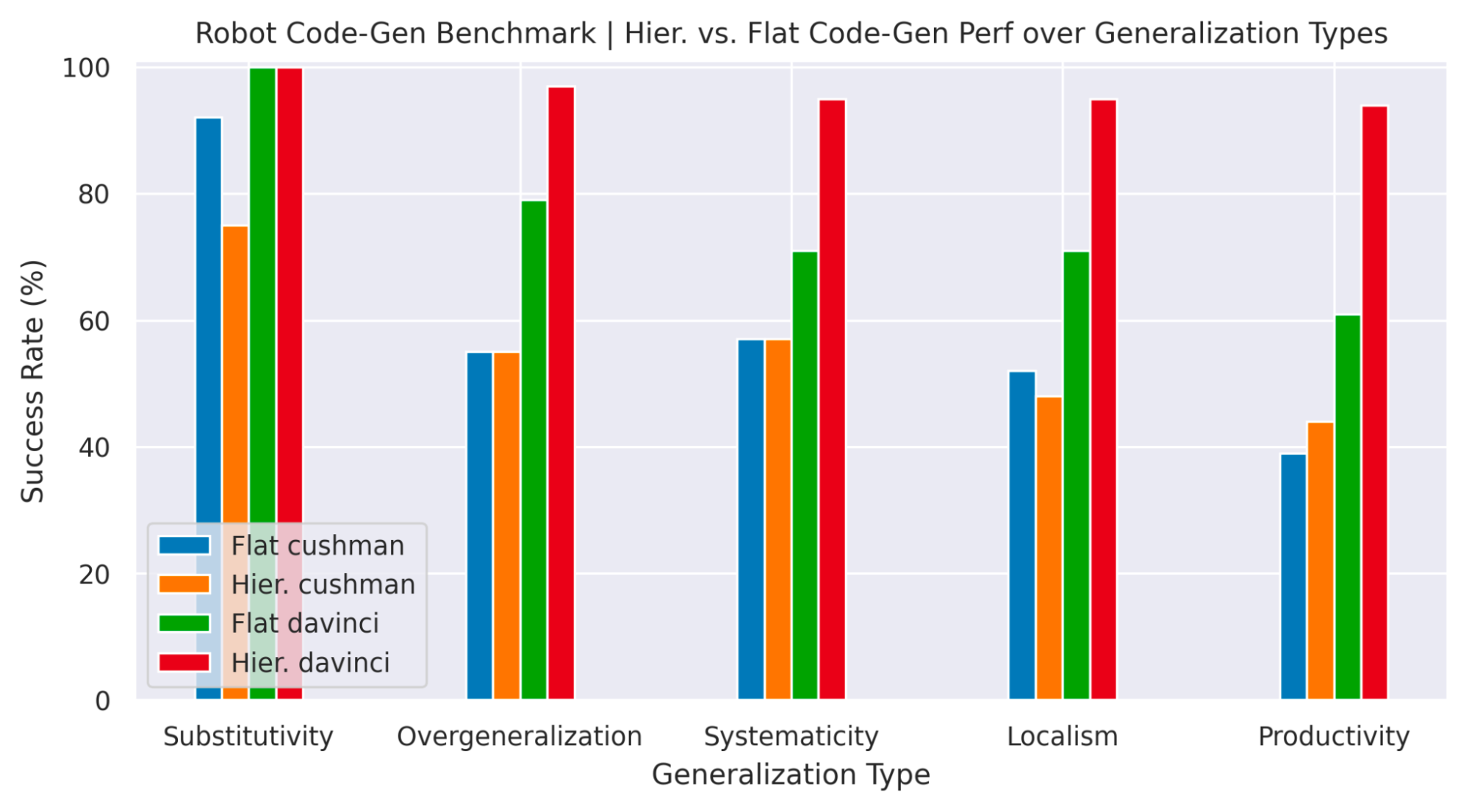 |
| عملکرد در معیار RoboCodeGen ما در انواع مختلف تعمیم. مدل بزرگتر (داوینچی) بهتر از مدل کوچکتر (Cushman) عمل می کند، با تولید کد سلسله مراتبی بیشترین بهره وری را بهبود می بخشد. |
ما همچنین در مورد پتانسیل مدلهای کدنویسی برای بیان طرحهای متقابل برای روباتهایی با مورفولوژیهای مختلف که وظایف یکسانی را بسته به APIهای موجود (فضاهای عمل ادراک) متفاوت انجام میدهند، هیجانزده هستیم، که یکی از جنبههای مهم هر پایه رباتیک است. مدل.
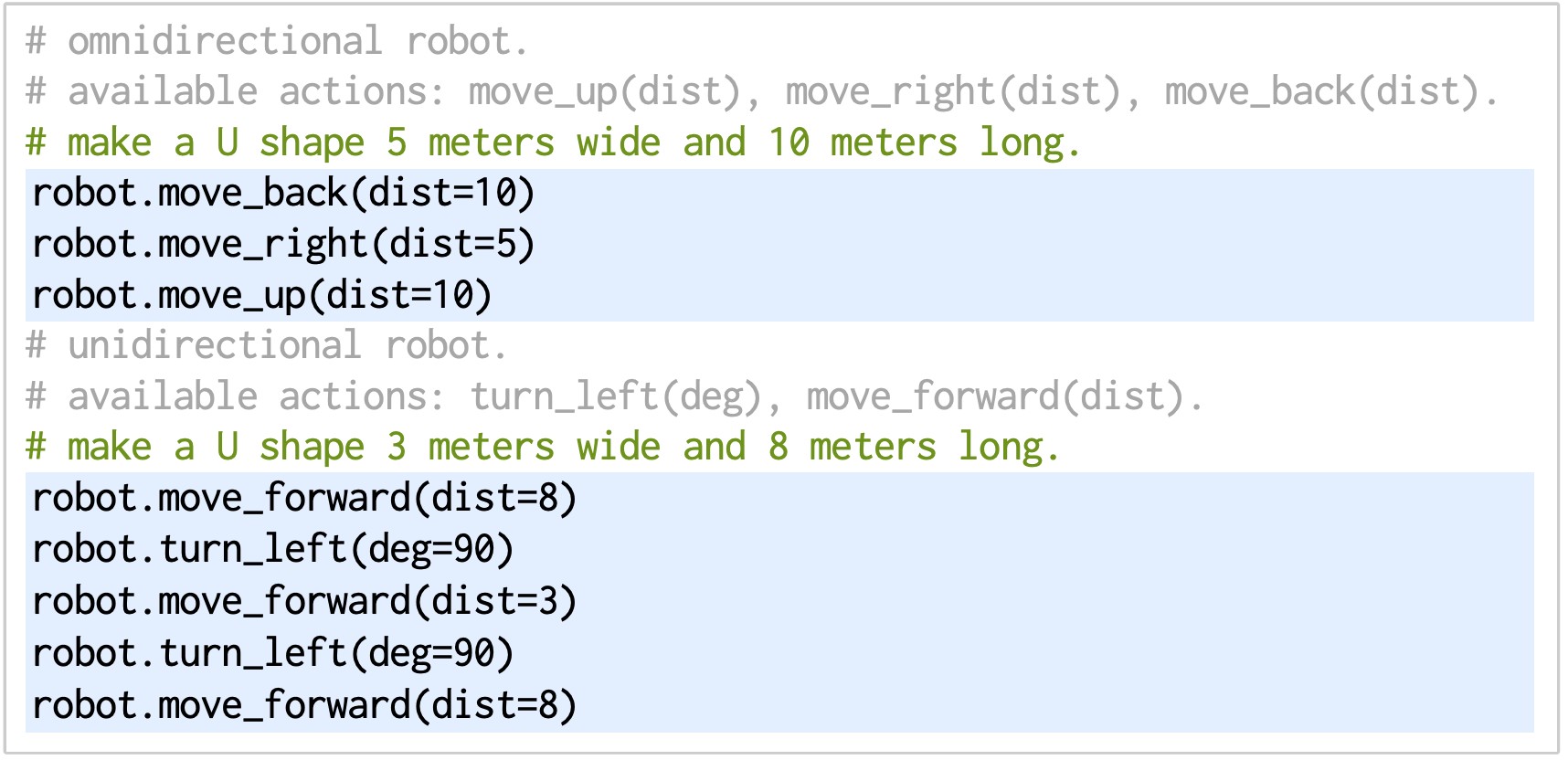 |
| تولید کد مدل زبان، قابلیتهای تجسم متقابل را نشان میدهد، و بسته به APIهای موجود (که فضاهای عمل ادراک را تعریف میکنند) یک کار را به روشهای مختلف تکمیل میکند. |
محدودیت ها
امروزه خطمشیهای کدنویسی بهوسیله (i) آنچه که APIهای ادراک میتوانند توصیف کنند محدود میشود (مثلاً تعداد کمی از مدلهای زبان بصری تا به امروز میتوانند توصیف کنند که آیا یک مسیر «پردستانداز» یا «بهشکل C» است)، و (ii) ) که کنترل های اولیه موجود هستند. فقط تعداد انگشت شماری از پارامترهای اولیه نامگذاری شده را می توان بدون اشباع بیش از حد دستورها تنظیم کرد. رویکرد ما همچنین فرض میکند که همه دستورالعملهای داده شده امکانپذیر هستند، و نمیتوانیم بگوییم که آیا کد تولید شده مفید خواهد بود یا خیر اولین. همچنین CaP ها برای تفسیر دستورالعمل هایی که به طور قابل توجهی پیچیده تر هستند یا در سطح انتزاعی متفاوتی نسبت به نمونه های چند تصویری ارائه شده به درخواست های مدل زبان عمل می کنند، تلاش می کنند. بنابراین، برای مثال، در حوزه رومیزی، «ساخت خانه با بلوکها» برای نمونه خاص ما از کلاهکها دشوار است، زیرا هیچ نمونهای از ساخت سازههای سه بعدی پیچیده وجود ندارد. این محدودیتها به راههایی برای کارهای آینده اشاره میکنند، از جمله گسترش مدلهای زبان بصری برای توصیف رفتارهای سطح پایین روبات (مثلاً مسیرها) یا ترکیب CaPs با الگوریتمهای اکتشافی که میتوانند بهطور مستقل به مجموعه کنترلهای اولیه اضافه کنند.
انتشار منبع باز
ما کد مورد نیاز برای بازتولید آزمایشهای خود و یک نسخه نمایشی ربات شبیهسازی شده تعاملی را در وبسایت پروژه منتشر کردهایم که شامل نمایشهای واقعی دیگری با ویدیوها و کدهای تولید شده است.
نتیجه
کد به عنوان سیاست گامی به سوی روباتهایی است که میتوانند رفتارهای خود را اصلاح کنند و بر این اساس قابلیتهای خود را گسترش دهند. این می تواند فعال باشد، اما انعطاف پذیری خطرات بالقوه را نیز افزایش می دهد، زیرا برنامه های ترکیب شده (مگر اینکه به صورت دستی در هر زمان اجرا بررسی شوند) ممکن است منجر به رفتارهای ناخواسته با سخت افزار فیزیکی شوند. ما میتوانیم این خطرات را با بررسیهای ایمنی داخلی که کنترلهای اولیه را که سیستم میتواند به آنها دسترسی داشته باشد، کاهش دهیم، اما برای اطمینان از اینکه ترکیبهای جدیدی از اولیههای شناختهشده به همان اندازه ایمن هستند، کار بیشتری لازم است. ما از بحث گسترده در مورد چگونگی به حداقل رساندن این خطرات و در عین حال به حداکثر رساندن تأثیرات مثبت بالقوه نسبت به ربات های همه منظوره استقبال می کنیم.
سپاسگزاریها
این تحقیق توسط Jacky Liang، Wenlong Huang، Fei Xia، Peng Xu، Karol Hausman، Brian Ichter، Pete Florence، Andy Zeng انجام شده است. تشکر ویژه از Vikas Sindhwani، Vincent Vanhoucke برای بازخورد مفید در مورد نوشتن، Chad Boodoo برای عملیات و پشتیبانی سخت افزاری. پیش چاپ اولیه در arXiv موجود است.