پیشبینی سریهای زمانی یک حوزه تحقیقاتی مهم است که برای چندین کاربرد علمی و صنعتی، مانند بهینهسازی زنجیره تامین خردهفروشی، پیشبینی انرژی و ترافیک، و پیشبینی آبوهوا حیاتی است. برای مثال، در موارد استفاده خردهفروشی، مشاهده شده است که بهبود دقت پیشبینی تقاضا میتواند به طور معناداری هزینههای موجودی را کاهش دهد و درآمد را افزایش دهد.
کاربردهای سری زمانی مدرن میتوانند شامل پیشبینی صدها هزار سری زمانی مرتبط (مثلاً تقاضای محصولات مختلف برای یک خردهفروش) در افقهای طولانی (مثلاً یک ربع یا سال دورتر با جزئیات روزانه) باشند. به این ترتیب، مدلهای پیشبینی سری زمانی باید معیارهای کلیدی زیر را برآورده کنند:
- توانایی رسیدگی به ویژگی های کمکی یا متغیرهای کمکی: بیشتر موارد استفاده میتوانند از استفاده مؤثر از متغیرهای کمکی سود زیادی ببرند، به عنوان مثال، در پیشبینی خردهفروشی، تعطیلات و ویژگیهای خاص محصول یا تبلیغات میتوانند بر تقاضا تأثیر بگذارند.
- مناسب برای روش های مختلف داده: باید بتواند دادههای پراکنده را مدیریت کند، به عنوان مثال، تقاضای متناوب برای یک محصول با حجم کم فروش و همچنین بتواند الگوهای فصلی مستمر قوی را در پیشبینی ترافیک مدلسازی کند.
تعدادی از راه حل های مبتنی بر شبکه عصبی توانسته اند عملکرد خوبی را در معیارها نشان دهند و همچنین از معیار فوق پشتیبانی کنند. با این حال، این روشها معمولاً به کندی آموزش داده میشوند و میتوانند برای استنباط، بهویژه برای افقهای طولانیتر، گران باشند.
در «پیشبینی بلندمدت با TiDE: رمزگذار متراکم سری زمانی»، ما یک معماری رمزگذار-رمزگذار پرسپترون چند لایه (MLP) برای پیشبینی سریهای زمانی ارائه میدهیم که در مقایسه با ترانسفورماتور، در معیارهای پیشبینی سریهای زمانی افق بلند، به عملکرد برتر دست مییابد. راه حل های مبتنی بر، در حالی که 5-10 برابر سریع تر است. سپس در «در مورد مزایای تخمین حداکثر احتمال برای رگرسیون و پیشبینی»، نشان میدهیم که استفاده از یک تابع زیان آموزشی با دقت طراحی شده بر اساس تخمین حداکثر احتمال (MLE) میتواند در مدیریت روشهای مختلف داده مؤثر باشد. این دو اثر مکمل یکدیگر هستند و می توانند به عنوان بخشی از یک مدل به کار روند. در واقع، آنها به زودی در پیش بینی Vertex AutoML در Google Cloud AI در دسترس خواهند بود.
TiDE: یک معماری ساده MLP برای پیش بینی سریع و دقیق
یادگیری عمیق در پیشبینی سریهای زمانی، بهتر از روشهای آماری سنتی، به ویژه برای مجموعه دادههای چند متغیره بزرگ، نویدبخش است. پس از موفقیت ترانسفورماتورها در پردازش زبان طبیعی (NLP)، چندین کار وجود دارد که انواع معماری ترانسفورماتور را برای پیش بینی افق طولانی (مدت زمان در آینده) ارزیابی می کند، مانند FEDformer و PatchTST. با این حال، کار دیگری نشان داده است که حتی مدلهای خطی نیز میتوانند از این گونههای ترانسفورماتور در معیارهای سری زمانی بهتر عمل کنند. با این وجود، مدلهای خطی ساده به اندازه کافی گویا نیستند تا ویژگیهای کمکی (مانند ویژگیهای تعطیلات و تبلیغات برای پیشبینی تقاضای خردهفروشی) و وابستگیهای غیرخطی به گذشته را کنترل کنند.
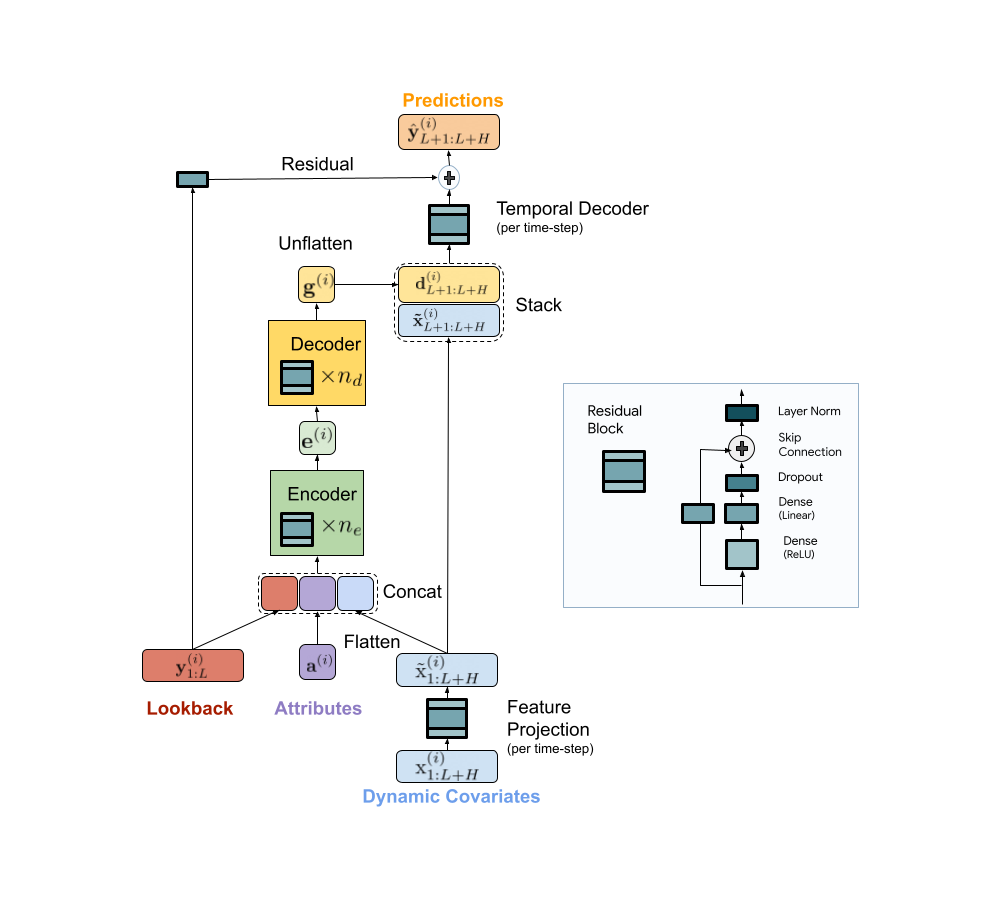
ما یک مدل رمزگذار-رمزگشا مبتنی بر MLP مقیاسپذیر برای پیشبینی سریع و دقیق چند مرحلهای ارائه میکنیم. مدل ما گذشته یک سری زمانی و تمام ویژگی های موجود را با استفاده از یک رمزگذار MLP رمزگذاری می کند. پس از آن، رمزگذاری با ویژگی های آینده با استفاده از رمزگشای MLP ترکیب می شود تا پیش بینی های آینده را ارائه دهد. معماری در زیر نشان داده شده است.
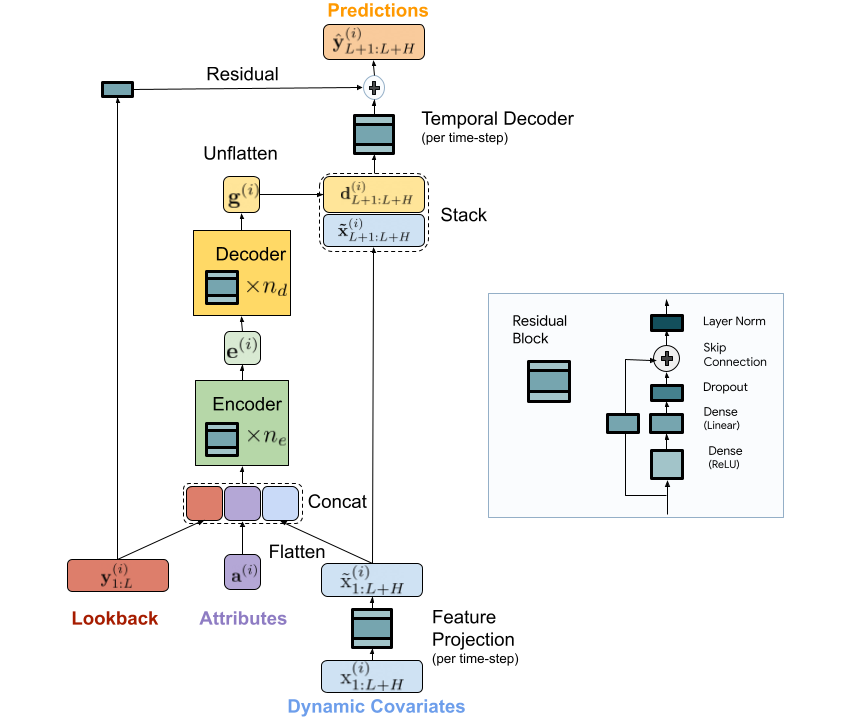 |
| معماری مدل TiDE برای پیش بینی چند مرحله ای |
TiDE در تمرین بیش از 10 برابر سریعتر از خطوط پایه مبتنی بر ترانسفورماتور است در حالی که در معیارها دقیق تر است. دستاوردهای مشابهی را می توان در استنتاج مشاهده کرد، زیرا تنها به صورت خطی با طول زمینه (تعداد مراحل زمانی که مدل به عقب نگاه می کند) و افق پیش بینی مقیاس می شود. در پایین سمت چپ، نشان میدهیم که مدل ما میتواند 10.6% بهتر از بهترین خط مبنا مبتنی بر ترانسفورماتور (PatchTST) در معیار پیشبینی ترافیک محبوب، از نظر میانگین مربعات خطای آزمایشی (MSE) باشد. در سمت راست، نشان میدهیم که در همان زمان مدل ما میتواند تاخیر استنتاج بسیار سریعتری نسبت به PatchTST داشته باشد.
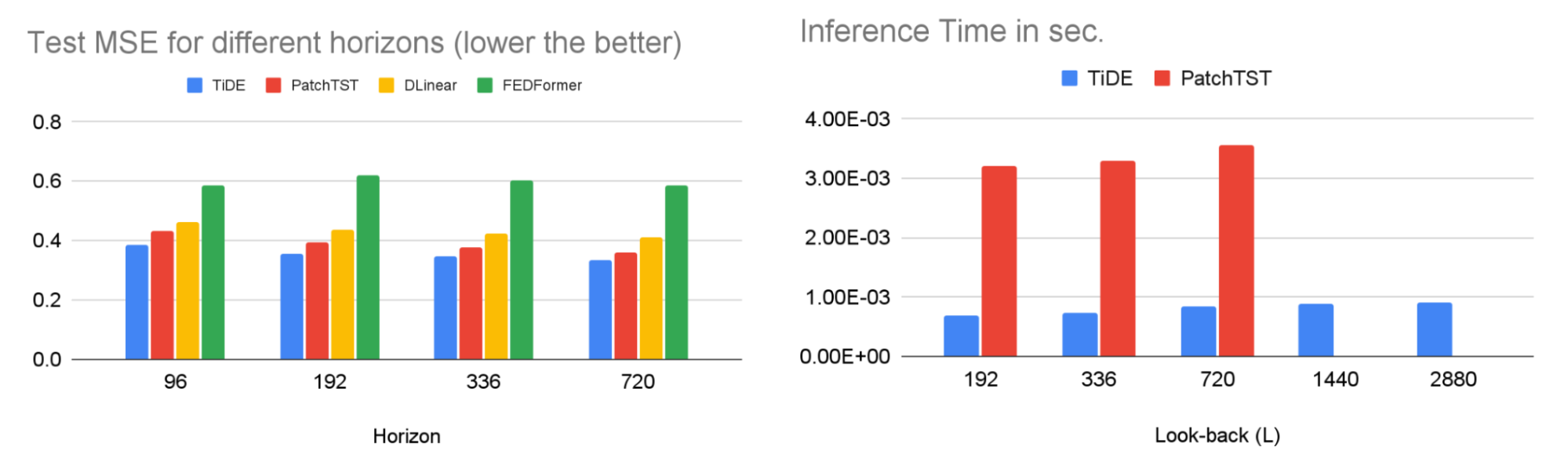 |
| ترک کرد: MSE در مجموعه آزمایشی یک معیار محبوب پیشبینی ترافیک. درست: زمان استنتاج TiDE و PatchTST به عنوان تابعی از طول نگاه به عقب. |
تحقیقات ما نشان میدهد که میتوانیم از مقیاسبندی محاسباتی خطی MLP با اندازههای نگاه به عقب و افق بدون کاهش دقت استفاده کنیم، در حالی که ترانسفورماتورها در این موقعیت مقیاس درجه دوم دارند.
توابع از دست دادن احتمالی
در بیشتر برنامههای پیشبینی، کاربر نهایی به معیارهای هدف محبوب مانند میانگین درصد مطلق خطا (MAPE)، درصد مطلق خطای وزنی (WAPE)، و غیره علاقهمند است. در چنین سناریوهایی، رویکرد استاندارد استفاده از متریک هدف مشابه با ضرر است. عملکرد در حین تمرین در «درباره مزایای تخمین حداکثر احتمال برای رگرسیون و پیشبینی»، که در ICLR پذیرفته شده است، نشان میدهیم که این رویکرد ممکن است همیشه بهترین نباشد. در عوض، ما از استفاده از حداکثر احتمال از دست دادن برای یک خانواده از توزیعها که به دقت انتخاب شدهاند (که در ادامه بیشتر مورد بحث قرار گرفته است) استفاده میکنیم که میتواند سوگیریهای استقرایی مجموعه داده را در طول آموزش دریافت کند. به عبارت دیگر، به جای خروجی مستقیم پیشبینیهای نقطهای که متریک هدف را به حداقل میرسانند، شبکه عصبی پیشبینی پارامترهای یک توزیع را در خانواده انتخابی پیشبینی میکند که به بهترین شکل دادههای هدف را توضیح میدهد. در زمان استنتاج، میتوانیم آماری را از توزیع پیشبینیشدهای که متریک هدف مورد نظر را به حداقل میرساند، پیشبینی کنیم (مثلاً، میانگین متریک هدف MSE را به حداقل میرساند در حالی که میانه، WAPE را به حداقل میرساند). علاوه بر این، ما همچنین میتوانیم به راحتی تخمینهای عدم قطعیت پیشبینیهای خود را به دست آوریم، به عنوان مثال، میتوانیم پیشبینیهای کمی را با تخمین چندکهای توزیع پیشبینی ارائه کنیم. در چندین مورد استفاده، کمیتهای دقیق بسیار حیاتی هستند، به عنوان مثال، در پیشبینی تقاضا، یک خردهفروش ممکن است بخواهد برای صدک ۹۰ سهام ذخیره کند تا در برابر بدترین سناریوها محافظت کند و از از دست رفتن درآمد جلوگیری کند.
انتخاب خانواده توزیع در چنین مواردی بسیار مهم است. به عنوان مثال، در زمینه داده های شمارش پراکنده، ممکن است بخواهیم خانواده توزیعی داشته باشیم که احتمال بیشتری را روی صفر قرار دهد، که معمولاً به عنوان تورم صفر شناخته می شود. ما ترکیبی از توزیعهای مختلف با وزنهای مخلوط آموختهشده را پیشنهاد میکنیم که میتواند با روشهای دادههای مختلف سازگار شود. در این مقاله، ما نشان میدهیم که استفاده از مخلوطی از توزیعهای دوجملهای منفی صفر و چندگانه در تنظیمات مختلف به خوبی کار میکند، زیرا میتواند با پراکندگی، روشهای چندگانه، دادههای شمارش، و دادههایی با دنبالههای زیر نمایی سازگار شود.
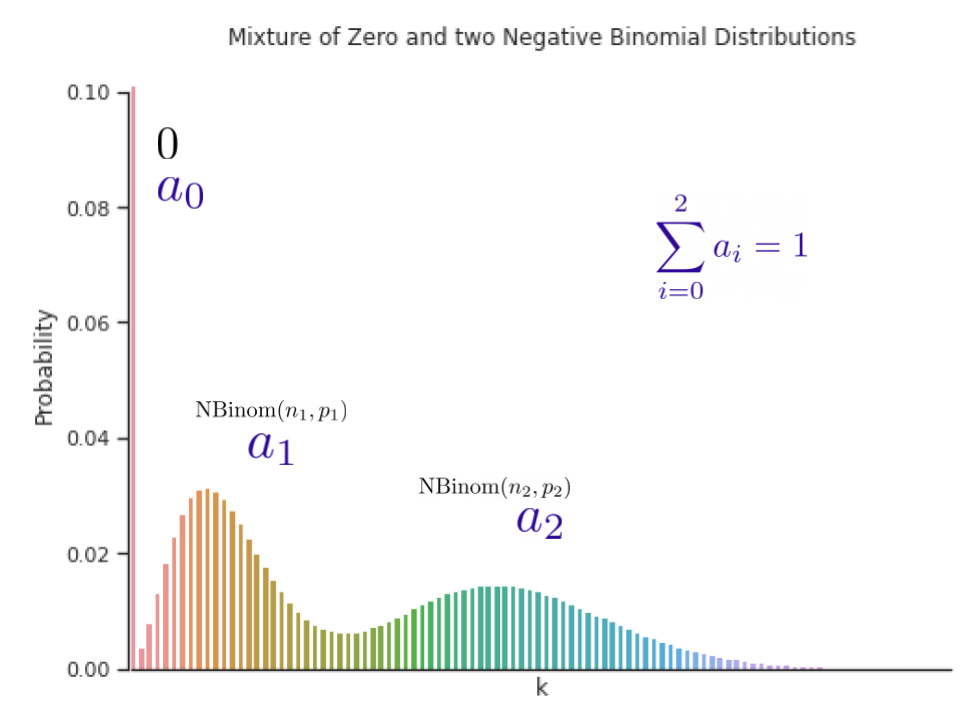 |
| مخلوطی از صفر و دو توزیع دوجمله ای منفی. اوزان سه جزء، الف1، آ2 و الف3، می توان در طول آموزش یاد گرفت. |
ما از این تابع ضرر برای آموزش مدلهای Vertex AutoML در مجموعه دادههای رقابت پیشبینی M5 استفاده میکنیم و نشان میدهیم که این تغییر ساده میتواند منجر به افزایش 6 درصدی شود و عملکرد بهتری از سایر معیارها در متریک رقابت، ریشه وزنی میانگین مربعات خطای مقیاس (WRMSSE) داشته باشد.
| پیش بینی M5 | WRMSSE |
| Vertex AutoML | 0.639 +/- 0.007 |
| Vertex AutoML با از دست دادن احتمالی | 0.581 +/- 0.007 |
| DeepAR | 0.789 +/- 0.025 |
| اشکال پررنگ | 0.804 +/- 0.033 |
نتیجه
ما نشان دادهایم که چگونه TiDE، همراه با توابع ضرر احتمالی، پیشبینی سریع و دقیق را امکانپذیر میسازد که به طور خودکار با توزیعها و روشهای مختلف داده سازگار میشود و همچنین تخمینهای عدم قطعیت را برای پیشبینیهای خود ارائه میدهد. این دقت پیشرفتهای را در میان راهحلهای مبتنی بر شبکه عصبی با کسری از هزینههای معماریهای پیشبینی مبتنی بر ترانسفورماتور قبلی، برای کاربردهای پیشبینی سازمانی در مقیاس بزرگ، ارائه میکند. ما امیدواریم که این کار علاقهمندی به بازنگری (هم از لحاظ نظری و هم تجربی) مدلهای پیشبینی سریهای زمانی عمیق مبتنی بر MLP را برانگیزد.
سپاسگزاریها
این کار نتیجه همکاری بین چندین نفر در سرتاسر Google Research و Google Cloud است، از جمله (به ترتیب حروف الفبا): Pranjal Awasthi، Dawei Jia، Weihao Kong، Andrew Leach، Shaan Mathur، Petros Mol، Shuxin Nie، Ananda Theertha Suresh، و رز یو.