الگوریتمهای یادگیری تقویتی (RL) میتوانند مهارتهایی را برای حل وظایف تصمیمگیری مانند بازی کردن، قادر ساختن روباتها برای برداشتن اشیاء یا حتی بهینهسازی طرحهای ریزتراشه بیاموزند. با این حال، اجرای الگوریتم های RL در دنیای واقعی نیاز به جمع آوری داده های فعال گران قیمت دارد. ثابت شده است که پیشآموزش در مجموعه دادههای متنوع، تنظیم دقیق دادهها را برای کارهای پاییندستی فردی در پردازش زبان طبیعی (NLP) و مشکلات بینایی امکانپذیر میکند. همانطور که مدلهای BERT یا GPT-3 مقداردهی اولیه را برای NLP فراهم میکنند، مدلهای بزرگ از پیش آموزشدیده RL میتوانند مقداردهی اولیهسازی عمومی برای تصمیمگیری را فراهم کنند. بنابراین، ما این سوال را میپرسیم: آیا میتوانیم پیشآموزش مشابهی را برای تسریع روشهای RL و ایجاد یک “ستون ستون فقرات” همه منظوره برای RL کارآمد در کارهای مختلف فعال کنیم؟
در «آموزش آفلاین Q بر روی دادههای چند وظیفهای متنوع، هم مقیاسها و هم تعمیمها»، که در ICLR 2023 منتشر میشود، در مورد چگونگی مقیاسبندی RL آفلاین بحث میکنیم، که میتواند برای آموزش توابع ارزش در مجموعه دادههای ایستا قبلاً جمعآوریشده، برای ارائه چنین مواردی مورد استفاده قرار گیرد. یک روش کلی پیش تمرینی ما نشان میدهیم که Scaled Q-Learning با استفاده از مجموعه دادههای متنوع برای یادگیری بازنماییهایی که انتقال سریع به کارهای جدید و یادگیری آنلاین سریع در انواع جدید یک کار را تسهیل میکنند، کافی است، و نسبت به روشهای یادگیری بازنمایی موجود و حتی روشهای مبتنی بر ترانسفورماتور که بسیار استفاده میکنند، به طور قابلتوجهی بهبود مییابد. مدل های بزرگتر
 |
Scaled Q-learning: پیش آموزش چند وظیفه ای با یادگیری محافظه کارانه Q
برای ارائه یک رویکرد پیشآموزشی همهمنظوره، RL آفلاین باید مقیاسپذیر باشد و به ما این امکان را میدهد تا روی دادهها در کارهای مختلف از قبل آموزش ببینیم و از مدلهای شبکه عصبی بیانگر برای به دست آوردن ستون فقرات از قبل آموزشدیده قدرتمند، تخصصی برای کارهای پایین دستی استفاده کنیم. ما روش پیشآموزشی آفلاین RL خود را بر اساس یادگیری محافظهکارانه Q (CQL) قرار دادیم، یک روش RL آفلاین ساده که بهروزرسانیهای استاندارد یادگیری Q را با تنظیمکننده اضافی ترکیب میکند که ارزش اقدامات غیرقابل مشاهده را به حداقل میرساند. با اقدامات گسسته، تنظیم کننده CQL معادل از دست دادن متقابل آنتروپی استاندارد است که یک اصلاح ساده و یک خطی در یادگیری عمیق Q استاندارد است. چند تصمیم مهم طراحی این امکان را فراهم کرد:
- اندازه شبکه عصبی: ما دریافتیم که یادگیری Q چند بازی به معماری شبکه عصبی بزرگ نیاز دارد. در حالی که روش های قبلی اغلب از شبکه های کانولوشن نسبتا کم عمق استفاده می کردند، ما دریافتیم که مدل هایی به بزرگی ResNet 101 منجر به پیشرفت های قابل توجهی نسبت به مدل های کوچکتر شده است.
- معماری شبکه عصبی: برای یادگیری ستون فقرات از پیش آموزشدیدهشده که برای بازیهای جدید مفید هستند، معماری نهایی ما از یک ستون فقرات شبکه عصبی مشترک استفاده میکند، با سرهای 1 لایه جداگانه که مقادیر Q-مقدار هر بازی را خروجی میدهند. این طراحی از تداخل بین بازیها در حین پیشآموزش جلوگیری میکند، در حالی که همچنان به اشتراک گذاری داده کافی برای یادگیری یک نمایش مشترک را فراهم میکند. ستون فقرات بینایی مشترک ما همچنین از جاسازی موقعیت آموخته شده (مشابه مدل های ترانسفورماتور) برای پیگیری اطلاعات مکانی در بازی استفاده می کند.
- تنظیم نمایندگی: کار اخیر مشاهده کرده است که یادگیری Q از مسائل فروپاشی بازنمایی رنج می برد، جایی که حتی شبکه های عصبی بزرگ نیز نمی توانند بازنمایی های موثر را یاد بگیرند. برای مقابله با این مشکل، ما از کارهای قبلی خود برای عادی سازی آخرین لایه های قسمت مشترک شبکه Q استفاده می کنیم. علاوه بر این، ما از اتلاف RL توزیعی طبقهای برای یادگیری Q استفاده کردیم، که به ارائه نمایشهای غنیتری که عملکرد پاییندستی کار را بهبود میبخشد، شناخته شده است.
معیار چند کاره آتاری
ما رویکرد خود را برای RL آفلاین مقیاسپذیر در مجموعهای از بازیهای Atari ارزیابی میکنیم، که در آن هدف آموزش یک عامل RL است تا مجموعهای از بازیها را با استفاده از دادههای ناهمگن از بازیکنان با کیفیت پایین (یعنی کمتر از حد مطلوب) بازی کند و سپس از نتیجه حاصل استفاده کند. ستون فقرات شبکه برای یادگیری سریع تغییرات جدید در بازی های قبل از تمرین یا بازی های کاملاً جدید. آموزش یک خط مشی واحد که بتواند بسیاری از بازیهای آتاری را بازی کند، حتی با روشهای استاندارد RL عمیق آنلاین به اندازه کافی دشوار است، زیرا هر بازی به استراتژی متفاوت و نمایشهای متفاوتی نیاز دارد. در تنظیمات آفلاین، برخی از کارهای قبلی، مانند ترانسفورماتورهای تصمیم چند بازی، پیشنهاد کردند که به طور کامل از RL صرف نظر کنند، و در عوض از یادگیری تقلید شرطی در تلاش برای مقیاسپذیری با معماریهای شبکه عصبی بزرگ، مانند ترانسفورماتورها استفاده کنند. با این حال، در این کار، نشان میدهیم که این نوع پیشآموزش چند بازی را میتوان به طور موثر از طریق RL با استفاده از CQL در ترکیب با چند تصمیم طراحی دقیق انجام داد، که در زیر توضیح میدهیم.
مقیاس پذیری در بازی های آموزشی
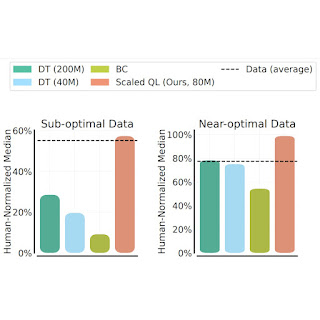
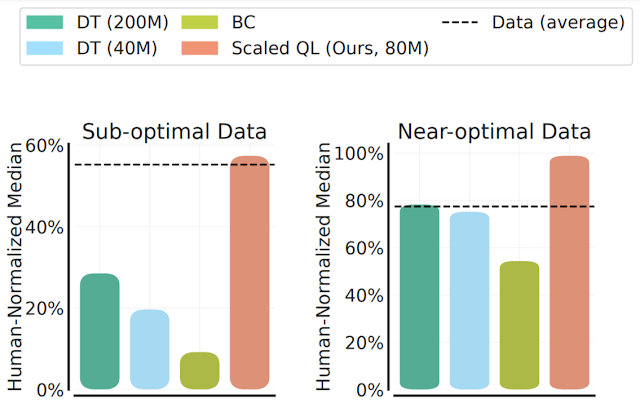
ما عملکرد و مقیاسپذیری روش Scaled Q-Learning را با استفاده از دو ترکیب داده ارزیابی میکنیم: (1) دادههای تقریباً بهینه، شامل تمام دادههای آموزشی که در بافرهای پخش مجدد اجراهای RL قبلی ظاهر میشوند و (2) دادههای با کیفیت پایین، متشکل از دادههای از 20 درصد اول آزمایشات در بافر پخش مجدد (یعنی فقط داده های سیاست های بسیار نابهینه). در نتایج زیر، ما Scaled Q-Learning را با یک مدل پارامتری 80 میلیونی با ترانسفورماتورهای تصمیم چند بازی (DT) با مدلهای 40 میلیون یا 80 میلیونی و یک شبیهسازی رفتاری (یادگیری تقلیدی) پایه (BC) مقایسه میکنیم. ). ما مشاهده میکنیم که Scaled Q-Learning تنها رویکردی است که نسبت به دادههای آفلاین بهبود مییابد و به حدود 80 درصد عملکرد عادی انسانی دست مییابد.
 |
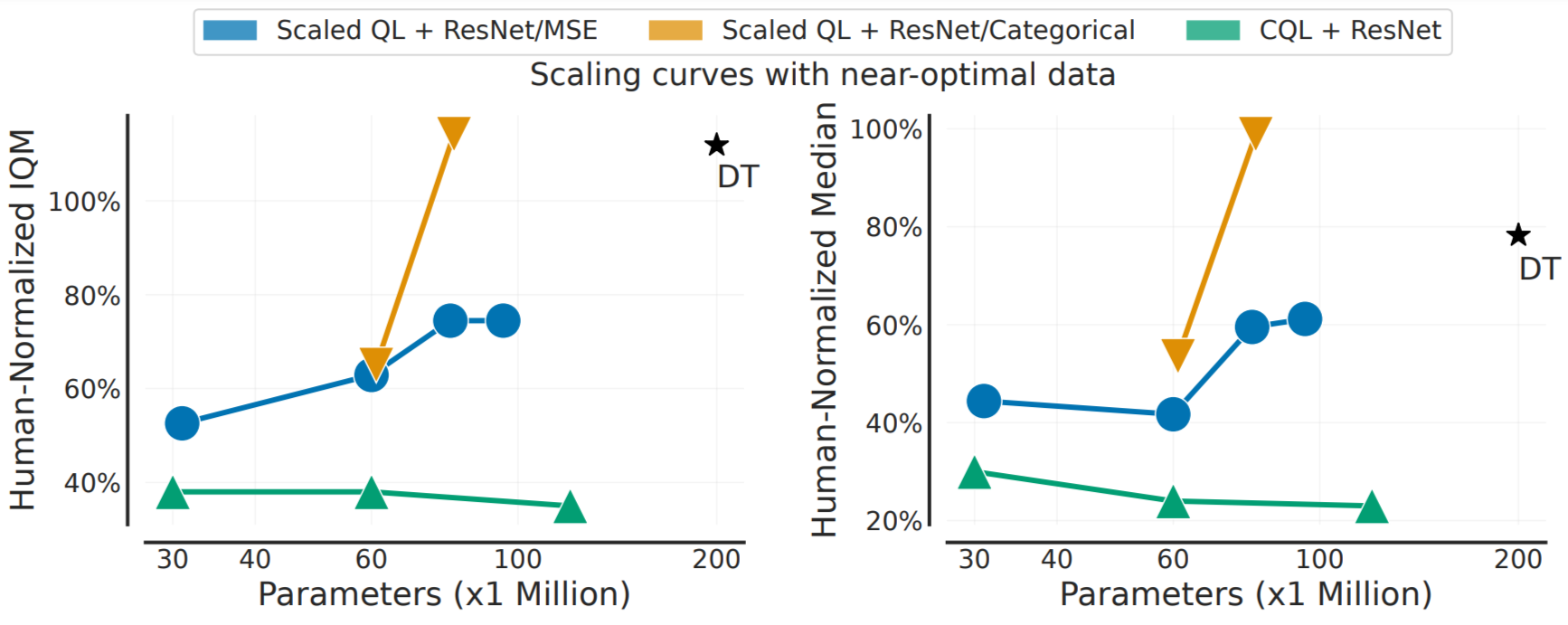
علاوه بر این، همانطور که در زیر نشان داده شده است، Scaled Q-Learning از نظر عملکرد بهبود می یابد، اما از مطلوبیت نیز برخوردار است. پوسته پوسته شدن ویژگیها: همانطور که عملکرد مدلهای زبان و بینایی از پیش آموزشدیده شده با بزرگتر شدن اندازه شبکه چگونه بهبود مییابد، با لذت بردن از چیزی که معمولاً به عنوان «مقیاسگذاری قانون قدرت» نامیده میشود، نشان میدهیم که عملکرد Scaled Q-learning از ویژگیهای مقیاسبندی مشابهی برخوردار است. در حالی که این ممکن است تعجب آور نباشد، این نوع مقیاس بندی در RL گریزان بوده است، و عملکرد اغلب با اندازه های مدل بزرگتر بدتر می شود. این نشان میدهد که Scaled Q-Learning در ترکیب با گزینههای طراحی فوق، توانایی RL آفلاین را برای استفاده از مدلهای بزرگ بهتر باز میکند.
 |
تنظیم دقیق بازی ها و تغییرات جدید
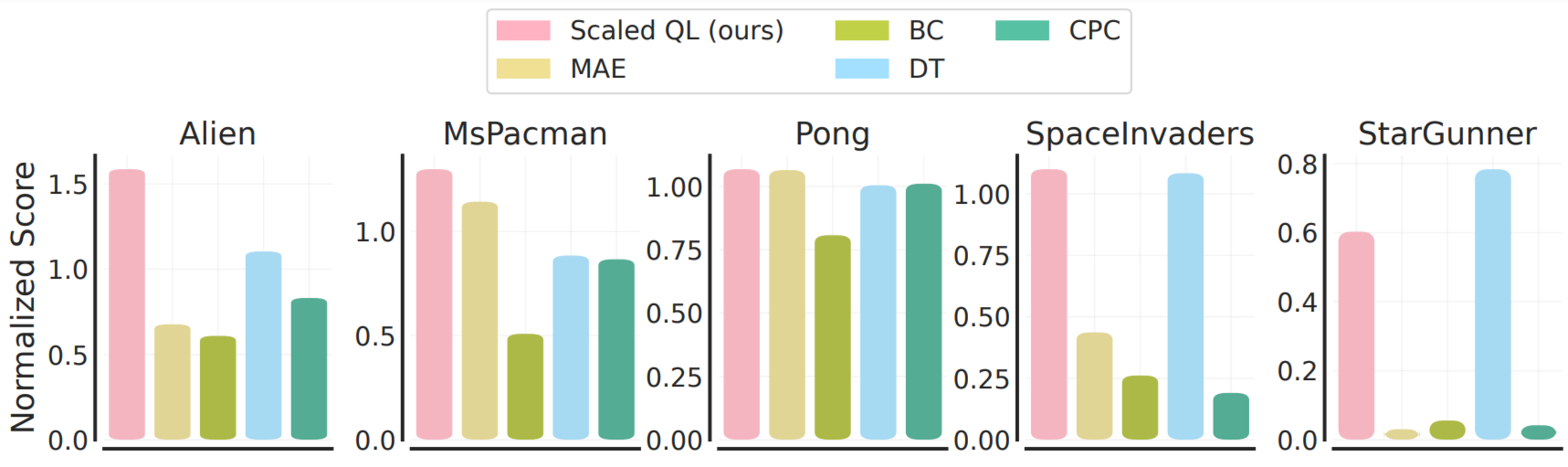
برای ارزیابی تنظیم دقیق از این مقداردهی اولیه آفلاین، ما دو تنظیم را در نظر می گیریم: (1) تنظیم دقیق به یک بازی جدید و کاملاً دیده نشده با مقدار کمی داده آفلاین از آن بازی، مربوط به 2M انتقال گیم پلی، و (2) تنظیم دقیق به نوع جدیدی از بازی ها با تعامل آنلاین. تنظیم دقیق داده های بازی آفلاین در زیر نشان داده شده است. توجه داشته باشید که این شرایط به طور کلی برای روشهای تقلیدی، Decision Transformer و شبیهسازی رفتاری مطلوبتر است، زیرا دادههای آفلاین بازیهای جدید از کیفیت نسبتاً بالایی برخوردار هستند. با این وجود، می بینیم که در بیشتر موارد، یادگیری مقیاس شده Q نسبت به رویکردهای جایگزین (به طور متوسط 80٪)، و همچنین روش های یادگیری بازنمایی اختصاصی، مانند MAE یا CPC، که فقط از داده های آفلاین برای یادگیری بازنمایی های بصری استفاده می کنند بهبود می یابد تا ارزش. کارکرد.
 |
در تنظیمات آنلاین، ما شاهد پیشرفتهای بزرگتر از قبل از آموزش با Scaled Q-learning هستیم. در این مورد، روشهای یادگیری بازنمایی مانند MAE حداقل پیشرفت را در طول RL آنلاین به همراه دارد، در حالی که Scaled Q-Learning میتواند با موفقیت دانش قبلی در مورد بازیهای پیشآموزشی را ادغام کند تا امتیاز نهایی را پس از ۲۰ هزار مرحله تعامل آنلاین به طور قابلتوجهی بهبود بخشد.
این نتایج نشان میدهد که پیشآموزش ستونهای تابع ارزش عمومی با RL آفلاین چند وظیفهای میتواند به طور قابلتوجهی عملکرد RL را در کارهای پایین دستی، هم در حالت آفلاین و هم در حالت آنلاین، افزایش دهد. توجه داشته باشید که این وظایف تنظیم دقیق بسیار دشوار است: بازی های مختلف آتاری و حتی انواع یک بازی، از نظر ظاهر و پویایی به طور قابل توجهی متفاوت هستند. به عنوان مثال، بلوک های هدف در Breakout در تغییرات بازی همانطور که در زیر نشان داده شده است ناپدید می شوند و کنترل را دشوار می کنند. با این حال، موفقیت Scaled Q-learning، بهویژه در مقایسه با تکنیکهای یادگیری بازنمایی بصری، مانند MAE و CPC، نشان میدهد که این مدل در واقع بهجای ارائه ویژگیهای بصری بهتر، برخی از نمایشهای پویایی بازی را یاد میگیرد.
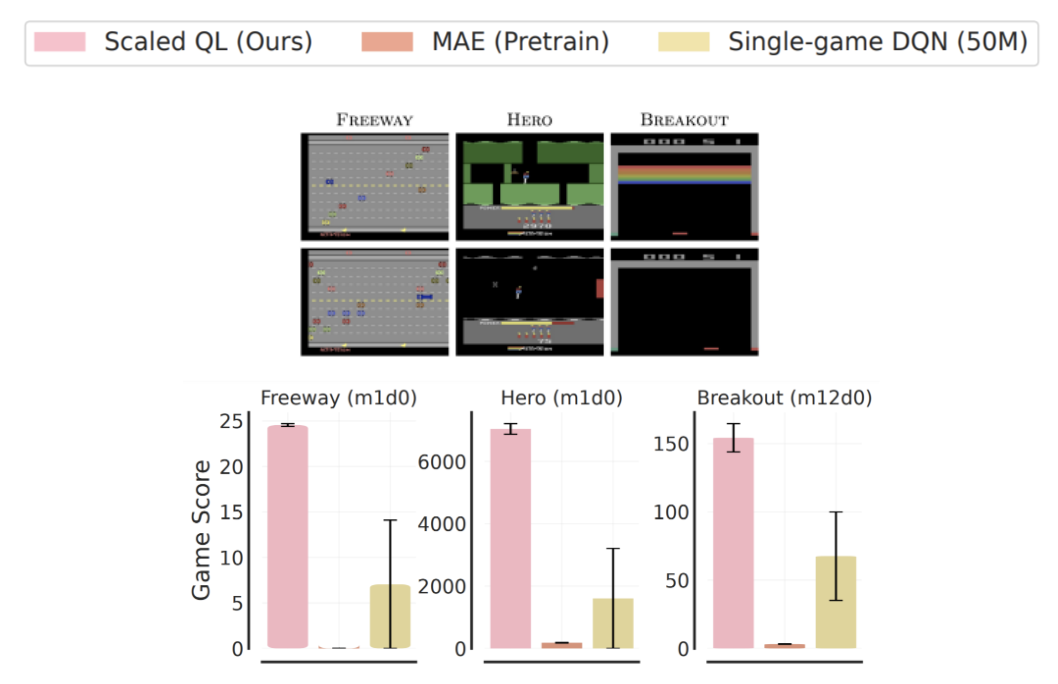 |
| تنظیم دقیق با RL آنلاین برای انواع بازی Freeway، Hero، و Breakout. نوع جدید مورد استفاده در تنظیم دقیق در ردیف پایین هر شکل نشان داده شده است، بازی اصلی که در قبل از تمرین مشاهده می شود در ردیف بالا قرار دارد. تنظیم دقیق Scaled Q-Learning به طور قابل توجهی بهتر از MAE (یک روش یادگیری نمایش تصویری) و یادگیری از ابتدا با DQN تک بازی است. |
نتیجه گیری و نکات اولیه
ما Scaled Q-Learning را ارائه کردیم، یک روش پیشآموزشی برای RL آفلاین مقیاسشده که بر اساس الگوریتم CQL ساخته شده است، و نشان دادیم که چگونه RL آفلاین کارآمد را برای آموزش چند وظیفهای فعال میکند. این کار پیشرفت اولیه را در جهت فعال کردن آموزش عملیتر در دنیای واقعی عوامل RL به عنوان جایگزینی برای خطوط لوله مبتنی بر شبیهسازی پرهزینه و پیچیده یا آزمایشهای مقیاس بزرگ انجام داد. شاید در درازمدت، کار مشابه به عوامل کلی از پیش آموزش دیده RL منجر شود که مهارت های کاوش و تعامل گسترده ای را از پیش آموزش آفلاین در مقیاس بزرگ توسعه می دهند. اعتبارسنجی این نتایج در طیف گستردهتری از وظایف واقعیتر، در حوزههایی مانند روباتیک (به برخی از نتایج اولیه مراجعه کنید) و NLP، یک جهت مهم برای تحقیقات آینده است. پیش آموزش آفلاین RL پتانسیل زیادی دارد و انتظار داریم در کارهای آینده شاهد پیشرفت های زیادی در این زمینه باشیم.
سپاسگزاریها
این کار توسط Aviral Kumar، Rishabh Agarwal، Xinyang Geng، George Tucker و Sergey Levine انجام شده است. تشکر ویژه از شری یانگ، اوفر ناچوم و کوانگ-هوی لی برای کمک به پایگاه کد مبدل تصمیم چند بازی برای ارزیابی و معیار چند بازی آتاری و تام اسمال برای تصاویر و انیمیشن.