
علیرغم دههها تحقیق، ما رباتهای متحرک زیادی را نمیبینیم که در خانهها، دفاتر و خیابانهای ما پرسه میزنند. ناوبری ربات های دنیای واقعی در محیط های انسان محور همچنان یک مشکل حل نشده باقی مانده است. این موقعیتهای چالشبرانگیز نیازمند ناوبری ایمن و کارآمد در فضاهای تنگ است، مانند فشردن بین میزهای قهوهخوری و کاناپهها، مانور دادن در گوشههای تنگ، درها، اتاقهای نامرتب و موارد دیگر. یک نیاز به همان اندازه حیاتی این است که به روشی پیمایش کنید که با هنجارهای نانوشته اجتماعی اطراف افراد مطابقت داشته باشد، به عنوان مثال، تسلیم شدن در گوشه های کور یا ماندن در یک فاصله راحت. Google Research متعهد به بررسی چگونگی پیشرفت در ML است که ما را قادر می سازد بر این موانع غلبه کنیم.
به طور خاص، مدلهای ترانسفورماتور به پیشرفتهای خیرهکنندهای در روشهای مختلف داده در مسائل یادگیری ماشینی (ML) در دنیای واقعی دست یافتهاند. برای مثال، معماریهای چندوجهی، رباتها را قادر میسازد تا از مدلهای زبان مبتنی بر ترانسفورماتور برای برنامهریزی سطح بالا استفاده کنند. کار اخیری که استفاده می کند ترانسفورماتورها برای رمزگذاری سیاست های رباتیک فرصتی هیجان انگیز برای استفاده از این معماری ها برای ناوبری در دنیای واقعی باز می کند. با این حال، استقرار روی ربات کنترلکنندههای عظیم مبتنی بر ترانسفورماتور میتواند به دلیل محدودیتهای تأخیر سخت برای روباتهای متحرک حیاتی برای ایمنی چالشبرانگیز باشد. پیچیدگی درجه دوم مکان و زمان مکانیسم توجه با توجه به طول ورودی اغلب به شدت گران است و محققان را مجبور میکند تا پشتههای ترانسفورماتور را به قیمت بیانپذیری اصلاح کنند.
به عنوان بخشی از کاوش مداوم ما در زمینه پیشرفتهای ML برای محصولات رباتیک، ما در سراسر Robotics در Google و Everyday Robots شریک شدیم تا «کنترلکنندههای پیشبینی مدل یادگیری با توجه زمان واقعی برای ناوبری در دنیای واقعی» را در کنفرانس یادگیری ربات (CoRL 2022) ارائه کنیم. در اینجا، Performer-MPC را معرفی میکنیم، یک سیستم روباتیک قابل یادگیری سرتاسر که ترکیبی از (1) یک کنترلکننده پیشبینیکننده مدل متمایز مبتنی بر JAX (MPC) است که گرادیانها را به پارامترهای تابع هزینه خود منتشر میکند، (2) مبتنی بر ترانسفورماتور رمزگذاریهای زمینه (مثلاً شبکههای اشغال برای وظایف ناوبری) که تابع هزینه MPC را نشان میدهد و MPC را با سناریوهای اجتماعی پیچیده بدون قوانین کدگذاری دستی تطبیق میدهد، و (3) معماریهای اجراکننده: ترانسفورماتورهای مقیاسپذیر با توجه ضمنی با رتبه پایین با خطی ماژولهای توجه پیچیدگی فضا و زمان برای استقرار کارآمد روی ربات (تأخیر 8 میلیثانیه روی ربات). ما نشان میدهیم که Performer-MPC میتواند تعمیم دهد در محیطهای مختلف برای کمک به روباتها برای حرکت در فضاهای تنگ در حالی که رفتارهای قابل قبول اجتماعی را نشان می دهد.
Performer-MPC
Performer-MPC قصد دارد MPCهای کلاسیک را با ML از طریق توابع هزینه قابل یادگیری آنها ترکیب کند. بنابراین Performer-MPCs را می توان نمونه ای از الگوریتم های یادگیری تقویت معکوس در نظر گرفت، جایی که تابع هزینه با یادگیری از تظاهرات متخصص استنباط می شود. به طور بحرانی، جزء قابل یادگیری تابع هزینه با تعبیههای نهفته تولید شده توسط Performer-Transformer پارامتر میشود. استنتاج خطی ارائه شده توسط Performers دروازه ای برای استقرار روی ربات در زمان واقعی است.
در عمل، شبکه اشغال که با ترکیب حسگرهای ربات ارائه می شود، به عنوان ورودی مدل Vision Performer عمل می کند. این مدل هرگز به صراحت ماتریس توجه را محقق نمی کند، بلکه از تجزیه رتبه پایین آن برای محاسبه خطی کارآمد ماژول توجه استفاده می کند که منجر به توجه مقیاس پذیر می شود. سپس، جاسازی توکن وصله ورودی ثابت خاص از آخرین لایه مدل، بخش درجه دوم و قابل یادگیری تابع هزینه مدل MPC را پارامتر می کند. این بخش به هزینه های منظم مهندسی شده (فاصله از موانع، شرایط جریمه برای تغییرات ناگهانی سرعت و غیره) اضافه می شود. این سیستم از طریق یادگیری تقلیدی برای تقلید از تظاهرات متخصصان به صورت سرتاسر آموزش داده شده است.
 |
| نمای کلی Performer-MPC. تعبیه نهفته نهایی وصله برجسته شده با رنگ قرمز برای ساخت هزینه یادگیری وابسته به زمینه استفاده می شود. پس انتشار (فلش های قرمز) از طریق پارامترهای ترانسفورماتور است. Performer محاسبه ماژول توجه مقیاس پذیر را از طریق تجزیه تقریبی رتبه پایین ماتریس توجه منظم (ماتریس Query’ و Key’) و با تغییر ترتیب ضرب های ماتریس (که با براکت های سیاه نشان داده شده است) ارائه می دهد. |
ناوبری ربات در دنیای واقعی
اگرچه، در اصل، Performer-MPC را می توان در تنظیمات مختلف روباتیک اعمال کرد، ما عملکرد آن را در جهت یابی در فضاهای محدود با حضور بالقوه افراد ارزیابی می کنیم. ما Performer-MPC را روی یک ربات چرخدار دیفرانسیل مستقر کردیم که یک دوربین سه بعدی LiDAR در جلو و سنسورهای عمق روی سرش نصب شده است. Performer-MPC با تأخیر 8 میلیثانیه قابل استقرار با ربات دارای پارامترهای 8.3M Performer است. زمان واقعی یک اجرا تنها 1 میلیثانیه است و ما از سریعترین نوع Performer-ReLU استفاده میکنیم.
ما Performer-MPC را با دو خط مبنا مقایسه می کنیم، یک خط مشی MPC معمولی (RMPC) بدون مولفه های هزینه آموخته شده، و یک خط مشی صریح (EP) که یک حالت مرجع و هدف را با استفاده از معماری Performer یکسان، اما بدون جفت شدن با ساختار MPC، پیش بینی می کند. . ما Performer-MPC را در یک شبیه سازی و در سه سناریو دنیای واقعی ارزیابی می کنیم. برای هر سناریو، سیاست های آموخته شده (EP و Performer-MPC) با نمایش های سناریو خاص آموزش داده می شود.
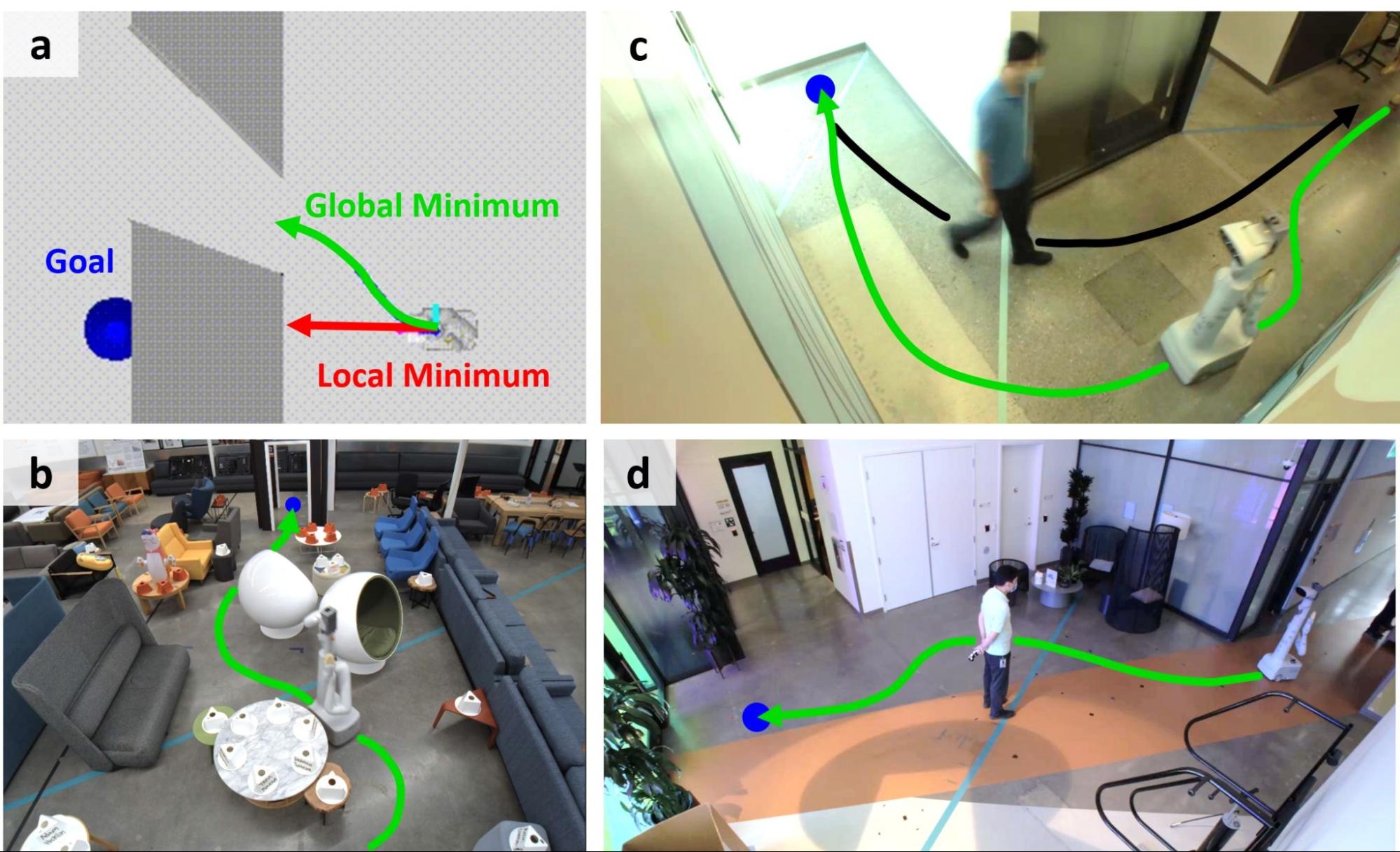 |
| سناریوهای آزمایش: (آ(ب) مانور دادن در فضاهای بسیار محدود، (ج) فعال کردن رفتارهای سازگار اجتماعی برای گوشه کور، و (د) تعاملات انسداد عابر پیاده. |
خطمشیهای ما از طریق شبیهسازی رفتار با چند ساعت داده ناوبری ربات کنترلشده توسط انسان در دنیای واقعی آموزش داده میشوند. برای جزئیات بیشتر جمع آوری داده ها، مقاله را ببینید. ما نتایج برنامهریزی Performer-MPC (سبز) و RMPC (قرمز) را به همراه نمایشهای متخصص (خاکستری) در نیمه بالایی و منحنیهای قطار و آزمایش را در نیمه پایین دو شکل زیر تجسم میکنیم. برای اندازه گیری فاصله بین مسیر ربات و مسیر خبره از فاصله هاوسدورف استفاده می کنیم.
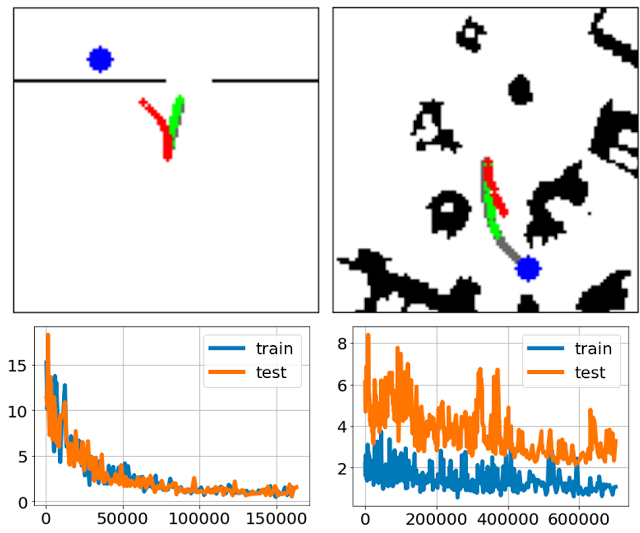 |
| بالا: تجسم نمونه های آزمایشی در پیمایش درگاه (چپ) و مسیر مانع بسیار محدود (راست). مسیرهای Performer-MPC که هدف را هدف قرار می دهند در مقایسه با مسیرهای RMPC همیشه به تظاهرات کارشناسی نزدیک تر هستند. پایین: منحنی های قطار و تست، که در آن محور عمودی نشان دهنده فاصله هاوسدورف و محور افقی نشان دهنده مراحل تمرین است. |
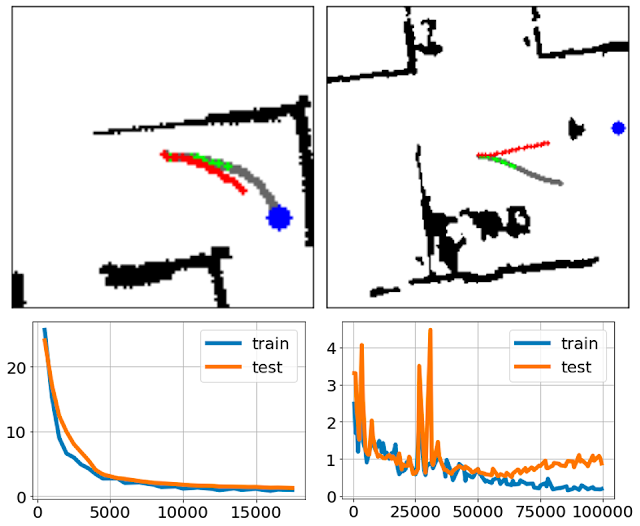 |
| بالا: تجسم نمونه های تست در گوشه کور (ترک کرد) و انسداد عابر پیاده (درست) سناریوها مسیرهای Performer-MPC که هدف را هدف قرار می دهند در مقایسه با مسیرهای RMPC همیشه به تظاهرات کارشناسی نزدیک تر هستند. پایین: منحنی های قطار و تست، که در آن محور عمودی نشان دهنده فاصله هاوسدورف و محور افقی نشان دهنده مراحل تمرین است. |
آموزش اجتناب از حداقل های محلی
ما Performer-MPC را در یک سناریوی پیمایش درگاه شبیهسازی شده ارزیابی میکنیم که در آن 100 جفت شروع و هدف بهطور تصادفی از طرفهای مخالف دیوار نمونهبرداری میشوند. یک برنامه ریز، که توسط یک تابع هزینه حریصانه هدایت می شود، اغلب ربات را به حداقل محلی هدایت می کند (یعنی گیر کردن در نزدیکترین نقطه به هدف در طرف دیگر دیوار). Performer-MPC یک تابع هزینه را می آموزد که ربات را برای عبور از درگاه هدایت می کند، حتی اگر باید از هدف دور شود و بیشتر حرکت کند. Performer-MPC میزان موفقیت 86% را در مقایسه با RMPC 24% نشان می دهد.
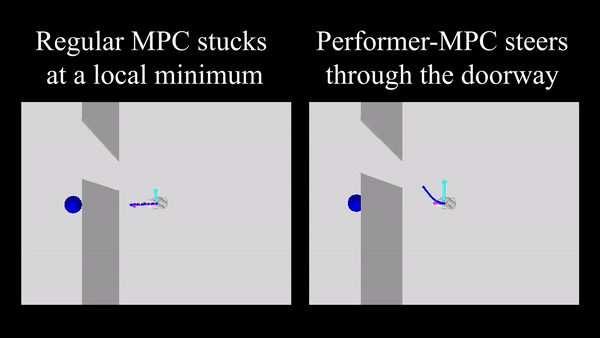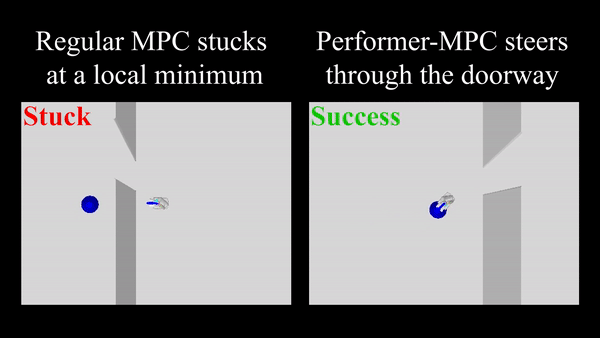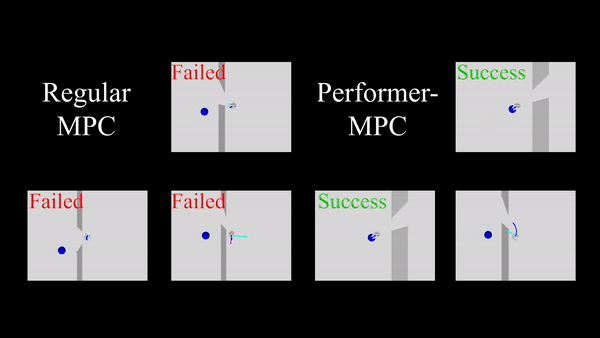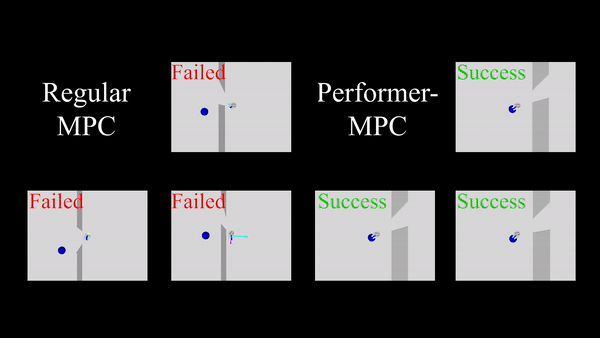 |
| مقایسه Performer-MPC با MPC معمولی در کار عبور از درگاه. |
یادگیری مانورهای بسیار محدود
در مرحله بعد، Performer-MPC را در یک سناریوی چالش برانگیز در دنیای واقعی آزمایش می کنیم، جایی که ربات باید مانورهای تیز و نزدیک به برخورد را در یک محیط خانه یا دفتر به هم ریخته انجام دهد. یک برنامه ریز جهانی، نقاط درشتی (یک مسیر ناوبری اسکلت) را که ربات دنبال می کند، ارائه می دهد. هر خط مشی ده بار اجرا می شود و ما نرخ موفقیت (SR) و میانگین درصد تکمیل (CP) با واریانس (VAR) مسیریابی مسیر مانع را گزارش می کنیم، جایی که ربات قادر است بدون شکست (برخورد یا گیر افتادن) از آن عبور کند. Performer-MPC از RMPC و EP در SR و CP بهتر عمل می کند.
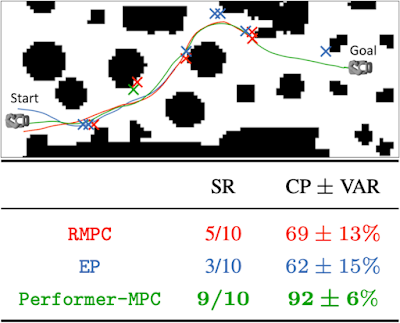 |
| یک مسیر مانع با مسیرهای خط مشی و مکان های شکست (که با ضربدر نشان داده شده است) برای RMPC، EP، و Performer-MPC. |
 |
| روبات کمکی Everyday Robots که در فضاهای بسیار محدود با استفاده از MPC منظم، سیاست صریح و Performer-MPC مانور می دهد. |
یادگیری جهت یابی در فضاهای با افراد
فراتر از موانع استاتیک، ما Performer-MPC را برای ناوبری روبات های اجتماعی اعمال می کنیم، جایی که روبات ها باید به شیوه ای قابل قبول اجتماعی حرکت کنند که طراحی توابع هزینه برای آن دشوار است. ما دو سناریو را در نظر می گیریم: (1) گوشه های کور، که در آن ربات ها باید از سمت داخلی گوشه راهرو اجتناب کنند تا در صورت ظاهر شدن ناگهانی شخصی، و (2) انسداد عابر پیاده، که در آن شخصی به طور غیرمنتظره ای مسیر تعیین شده ربات را مختل می کند.
 |
| Performer-MPC روی ربات کمکی Everyday Robots مستقر شده است. ترک کرد: MPC معمولی به طور موثر گوشههای کور را قطع میکند و فرد را مجبور میکند به عقب برگردد. درست: Performer-MPC از بریدن گوشه های کور اجتناب می کند و امکان ناوبری ایمن و قابل قبول اجتماعی را در اطراف افراد فراهم می کند. |
 |
 |
| مقایسه با یک ربات کمکی Everyday Robots که از MPC معمولی، سیاست صریح، و Performer-MPC در گوشه های کور نامرئی استفاده می کند. |
 |
| مقایسه با یک ربات کمکی Everyday Robots با استفاده از MPC معمولی، سیاست صریح، و Performer-MPC در سناریوهای انسداد عابر پیاده دیده نشده است. |
نتیجه
ما Performer-MPC را معرفی میکنیم، یک سیستم روباتیک قابل یادگیری سرتاسر که مکانیسمهای مختلفی را ترکیب میکند تا ناوبری ربات در دنیای واقعی، قوی و تطبیقی را با ترانسفورماتورهای روی ربات در زمان واقعی امکانپذیر کند. این کار نشان میدهد که معماریهای ترانسفورماتور مقیاسپذیر نقش مهمی در طراحی کنترلکنندههای روباتیک مبتنی بر توجه بیانگر دارند. ما نشان میدهیم که استنتاج با تاخیر میلیثانیهای در زمان واقعی برای سیاستهایی که از ترانسفورماتورها با چند میلیون پارامتر استفاده میکنند، امکانپذیر است. علاوه بر این، ما نشان میدهیم که چنین سیاستهایی رباتها را قادر میسازد تا رفتارهای کارآمد و قابل قبول اجتماعی را که میتوانند به خوبی تعمیم دهند، یاد بگیرند. ما معتقدیم که این یک فصل جدید هیجان انگیز را در مورد استفاده از Transformers در رباتیک دنیای واقعی باز می کند و مشتاقانه منتظر ادامه تحقیقات خود با روبات های کمکی Everyday Robots هستیم.
سپاسگزاریها
تشکر ویژه از Xuesu Xiao برای رهبری این تلاش در Everyday Robots به عنوان یک محقق بازدیدکننده. این تحقیق توسط Xuesu Xiao، Tingnan Zhang، Krzysztof Choromanski، Edward Lee، Anthony Francis، Jake Varley، Stephen Tu، Sumeet Singh، Peng Xu، Fei Xia، Sven Mikael Persson، Dmitry Kalashnikov، Leila Takayama، Roy Frostig، انجام شده است. ، کارولینا پارادا و ویکاس سندوانی. تشکر ویژه از وینسنت ونهوک به خاطر بازخوردش در مورد نسخه خطی.