مدلهای بنیادی زبان بینایی بر اساس یک پیشآموزش منفرد ساخته میشوند که پس از آن سازگاری بعدی با وظایف چندگانه پاییندستی است. دو سناریو آموزشی اصلی و غیرمرتبط رایج هستند: یادگیری متضاد به سبک CLIP و پیشبینی نشانه بعدی. یادگیری متضاد به مدل آموزش میدهد تا پیشبینی کند که آیا جفتهای تصویر-متن به درستی مطابقت دارند یا خیر، به طور مؤثری نمایشهای بصری و متنی را برای ورودیهای تصویر و متن مربوطه ایجاد میکند، در حالی که پیشبینی نشانه بعدی محتملترین نشانه متن بعدی را در یک دنباله پیشبینی میکند، بنابراین تولید متن را یاد میگیرد. ، با توجه به وظیفه مورد نیاز. یادگیری متضاد وظایف بازیابی تصویر-متن و متن-تصویر را امکان پذیر می کند، مانند یافتن تصویری که به بهترین وجه با یک توصیف خاص مطابقت دارد، و یادگیری نشانه بعدی، وظایف تولید متن، مانند عنوان تصویر و پاسخ به سؤالات بصری (VQA) را امکان پذیر می کند. در حالی که هر دو رویکرد نتایج قدرتمندی را نشان دادهاند، وقتی یک مدل به طور متضاد از قبل آموزش داده میشود، معمولاً در وظایف تولید متن خوب عمل نمیکند و بالعکس. علاوه بر این، سازگاری با سایر وظایف اغلب با روش های پیچیده یا ناکارآمد انجام می شود. به عنوان مثال، به منظور گسترش یک مدل زبان بینایی به ویدیوها، برخی از مدل ها باید برای هر فریم ویدیو به طور جداگانه استنتاج کنند. این اندازه ویدیوهای قابل پردازش را به چند فریم محدود می کند و به طور کامل از اطلاعات حرکتی موجود در فریم ها استفاده نمی کند.
با انگیزه این موضوع، ما “معماری ساده برای یادگیری مشترک برای وظایف چندوجهی” را به نام MaMMUT ارائه می کنیم که می تواند به طور مشترک برای این اهداف رقابتی آموزش ببیند و پایه ای برای بسیاری از وظایف زبان بینایی به طور مستقیم یا از طریق سازگاری ساده فراهم می کند. MaMMUT یک مدل چندوجهی فشرده با پارامتر 2B است که اهداف متضاد، تولید متن، و آگاه به محلی سازی را آموزش می دهد. این شامل یک رمزگذار تصویر و یک رمزگشای متن است که امکان استفاده مجدد مستقیم از هر دو مؤلفه را فراهم می کند. علاوه بر این، یک انطباق ساده با وظایف متنی ویدئویی فقط نیاز به استفاده از رمزگذار تصویر یک بار دارد و می تواند فریم های بسیار بیشتری را نسبت به کارهای قبلی انجام دهد. مطابق با مدلهای زبان اخیر (مانند PaLM، GLaM، GPT3)، معماری ما از یک مدل متنی فقط رمزگشا استفاده میکند و میتوان آن را به عنوان یک توسعه ساده از مدلهای زبان در نظر گرفت. مدل ما در حالی که اندازه متوسطی دارد، بهتر از وضعیت هنر عمل می کند یا به عملکرد رقابتی در بازیابی تصویر-متن و متن-تصویر، پاسخ به سؤالات ویدیویی (VideoQA)، شرح ویدیو، تشخیص واژگان باز، و VQA دست می یابد.
 |
 |
 |
| مدل MaMMUT طیف گسترده ای از وظایف مانند بازیابی تصویر-متن/متن-تصویر را امکان پذیر می کند.بالا سمت چپ و بالا سمت راست), VQA (وسط سمت چپ)، تشخیص واژگان باز (وسط سمت راستو VideoQA (پایین). |
معماری مدل فقط رمزگشا
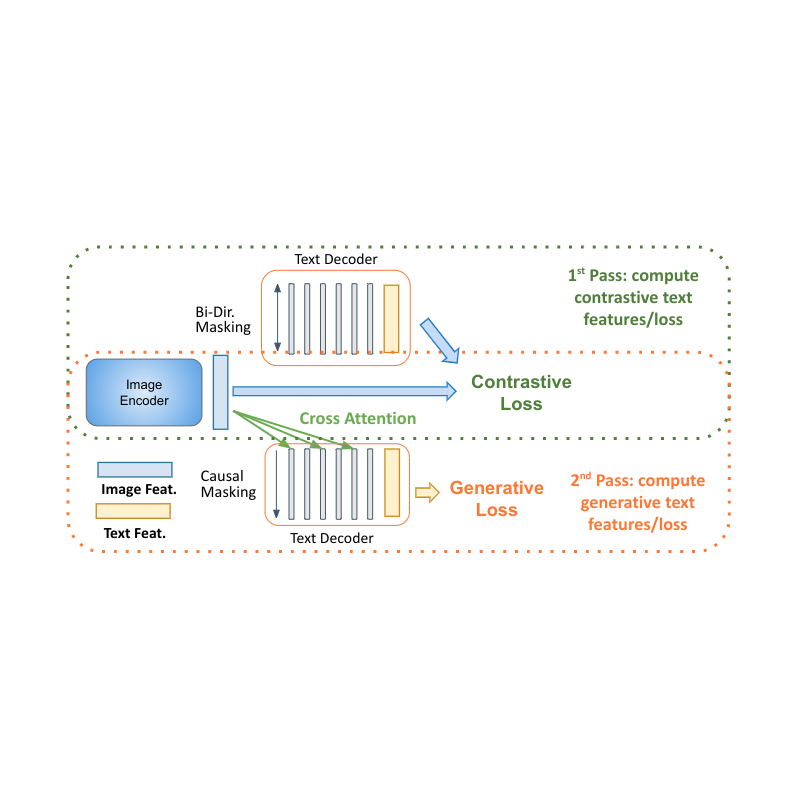
یکی از یافتههای شگفتانگیز این است که یک رمزگشای زبان واحد برای همه این کارها کافی است، که نیاز به ساختارهای پیچیده و روشهای آموزشی ارائهشده در قبل را برطرف میکند. به عنوان مثال، مدل ما (در شکل زیر در سمت چپ ارائه شده است) از یک رمزگذار بصری و رمزگشای متنی منفرد تشکیل شده است که از طریق توجه متقاطع به هم متصل شدهاند و به طور همزمان روی هر دو نوع تلفات متضاد و تولید متن آموزش میدهند. در مقایسه، کار قبلی یا قادر به انجام وظایف بازیابی تصویر-متن نیست، یا فقط برخی از ضررها را فقط برای برخی از بخشهای مدل اعمال میکند. برای فعال کردن وظایف چندوجهی و استفاده کامل از مدل فقط رمزگشا، باید به طور مشترک هم تلفات کنتراست و هم تلفات زیرنویس مولد متن را آموزش دهیم.
 |
| معماری MaMMUT (ترک کرد) یک ساختار ساده است که از یک رمزگذار بینایی و یک رمزگشای متنی تشکیل شده است. در مقایسه با سایر مدلهای محبوب زبان بینایی – به عنوان مثال، PaLI (وسط) و ALBEF، CoCa (درست) – به طور مشترک و کارآمد برای چندین کار به زبان بینایی، با تلفات متضاد و تولید متن، تمرین می کند و وزن ها را به طور کامل بین وظایف تقسیم می کند. |
رسیور یادگیری دو پاس
مدلهای فقط رمزگشا برای یادگیری زبان مزایای واضحی را در عملکرد با اندازه مدل کوچکتر نشان میدهند (تقریباً نیمی از پارامترها). چالش اصلی برای بکارگیری آنها در تنظیمات چندوجهی، یکسان کردن یادگیری متضاد (که از نمایش سطح توالی بدون قید و شرط استفاده می کند) با عنوان (که احتمال یک نشانه مشروط به نشانه های قبلی را بهینه می کند) است. ما یک رویکرد دو پاس را برای یادگیری مشترک این دو نوع متضاد نمایش متن در رمزگشا پیشنهاد می کنیم. در طی اولین گذر، از توجه متقاطع و پنهانسازی علّی برای یادگیری وظیفه تولید شرح استفاده میکنیم – ویژگیهای متن میتوانند به ویژگیهای تصویر توجه کنند و نشانهها را به ترتیب پیشبینی کنند. در پاس دوم، توجه متقاطع و پوشاندن علّی را غیرفعال می کنیم تا کار کنتراست را یاد بگیریم. ویژگیهای متنی ویژگیهای تصویر را نمیبینند، اما میتوانند به صورت دو طرفه به همه نشانههای متنی در یک زمان برای تولید نمایش مبتنی بر متن نهایی مراجعه کنند. تکمیل این رویکرد دو گذری در یک رمزگشا امکان تطبیق هر دو نوع کار را فراهم می کند که قبلاً تطبیق آنها دشوار بود. در حالی که ساده است، نشان میدهیم که این معماری مدل میتواند پایهای برای وظایف چندوجهی فراهم کند.
 |
| یادگیری دو گذری فقط رمزگشای MaMMUT مسیرهای یادگیری متضاد و مولد را با یک مدل امکان پذیر می کند. |
یکی دیگر از مزایای معماری ما این است که از آنجایی که برای این وظایف مجزا آموزش داده شده است، می توان آن را به طور یکپارچه در چندین برنامه کاربردی مانند بازیابی تصویر-متن و متن-تصویر، VQA و زیرنویس اعمال کرد.
علاوه بر این، MaMMUT به راحتی با وظایف زبان ویدئویی سازگار می شود. رویکردهای قبلی از یک رمزگذار بینایی برای پردازش هر فریم به صورت جداگانه استفاده می کردند که نیاز به اعمال چندین بار آن داشت. این سرعت کند است و تعداد فریمهایی را که مدل میتواند انجام دهد، معمولاً به ۶ تا ۸ محدود میکند. با MaMMUT، ما از لوله های ویدئویی پراکنده برای تطبیق سبک وزن مستقیماً از طریق اطلاعات مکانی-زمانی ویدیو استفاده می کنیم. علاوه بر این، تطبیق مدل با تشخیص واژگان باز با آموزش تشخیص جعبههای مرزی از طریق هد تشخیص شی انجام میشود.
 |
| انطباق معماری MaMMUT با وظایف ویدیویی (ترک کرد) ساده است و به طور کامل از مدل استفاده مجدد می کند. این کار با تولید یک نمایش ویژگی «لولههای» ویدیویی، شبیه به وصلههای تصویر، انجام میشود که به نشانههای ابعاد پایینتر نمایش داده میشوند و از طریق رمزگذار بینایی اجرا میشوند. برخلاف رویکردهای قبلی (درست) که نیاز به اجرای چندین تصویر جداگانه از طریق رمزگذار بینایی دارند، ما فقط یک بار از آن استفاده می کنیم. |
نتایج
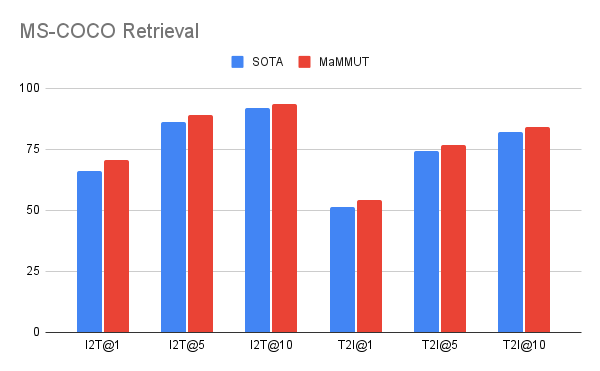
مدل ما به نتایج عالی صفر شات در بازیابی تصویر-متن و متن-تصویر بدون هیچ گونه انطباق میرسد و از تمام مدلهای پیشرفته قبلی بهتر عمل میکند. نتایج در VQA با نتایج پیشرفته ای که توسط مدل های بسیار بزرگتر به دست می آیند قابل رقابت است. مدل PaLI (پارامترهای 17B) و مدل فلامینگو (80B) بهترین عملکرد را در مجموعه داده VQA2.0 دارند، اما MaMMUT (2B) دقتی برابر با 15B PaLI دارد.
 |
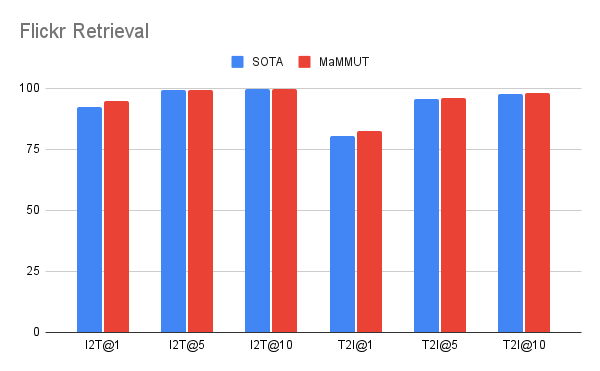 |
| MaMMUT در بازیابی تصویر-متن صفر شات (I2T) و بازیابی متن-تصویر (T2I) در هر دو MS-COCO (SOTA) عملکرد بهتری دارد.بالا) و فلیکر (پایین) معیارها |
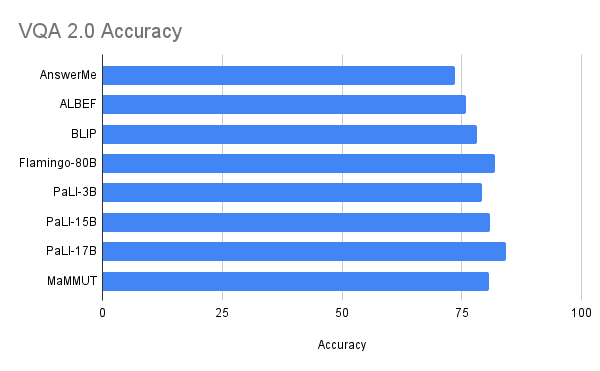 |
| عملکرد در مجموعه داده VQA2.0 رقابتی است اما از مدل های بزرگ مانند Flamingo-80B و PalI-17B بهتر نیست. عملکرد در محیط چالشبرانگیزتر تولید متن باز ارزیابی میشود. |
همانطور که در زیر در مجموعه دادههای MSRVTT-QA و MSVD-QA نشان داده شده است، MaMMUT از آخرین هنر در VideoQA نیز بهتر عمل میکند. توجه داشته باشید که ما از مدلهای بسیار بزرگتری مانند فلامینگو که مخصوصاً برای پیشآموزش تصویر+ویدئو طراحی شده و با دادههای متن تصویر و متن ویدئویی از قبل آموزش داده شده است، بهتر عمل میکنیم.
 |
 |
| MaMMUT از مدل های SOTA در وظایف VideoQA بهتر عمل می کند (مجموعه داده MSRVTT-QA، بالامجموعه داده MSVD-QA، پایینعملکرد بهتری نسبت به مدلهای بزرگتر دارد، بهعنوان مثال، 5B GIT2 یا Flamingo، که از پارامترهای 80B استفاده میکند و برای کارهای زبان تصویر و زبان بینایی از قبل آموزش دیده است. |
نتایج ما در مورد تنظیم دقیق تشخیص واژگان باز، همانطور که در زیر نیز نشان داده شده است، عملکرد بهتری دارد.
مواد اصلی
ما نشان میدهیم که آموزش مشترک اهداف متضاد و متنساز کار آسانی نیست، و در ابلیشنهایمان متوجه میشویم که این وظایف با انتخابهای مختلف طراحی بهتر انجام میشوند. می بینیم که ارتباطات متقابل کمتری برای کارهای بازیابی بهتر است، اما تعداد بیشتری توسط وظایف VQA ترجیح داده می شود. با این حال، در حالی که این نشان میدهد که انتخابهای طراحی مدل ما ممکن است برای کارهای فردی نابهینه باشد، مدل ما از مدلهای پیچیدهتر یا بزرگتر مؤثرتر است.
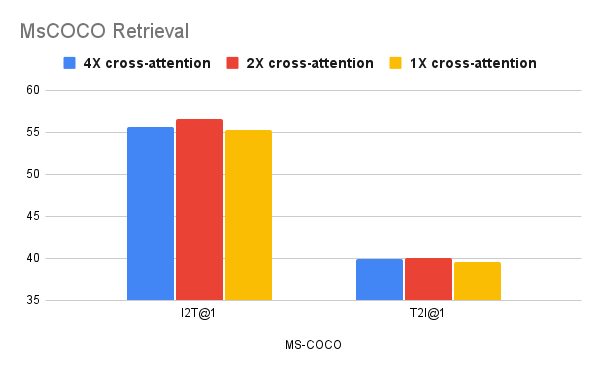 |
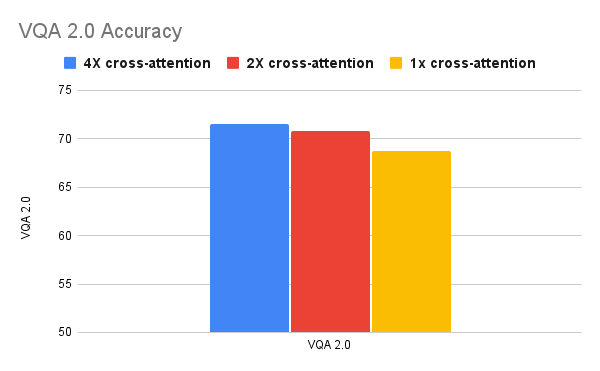 |
| مطالعات فرسایشی نشان می دهد که اتصالات متقاطع کمتر (1-2) برای کارهای بازیابی بهتر است (بالا(پایین). |
نتیجه
ما MaMMUT را ارائه کردیم، یک مدل رمزگشای زبان-کدگذار بینایی ساده و فشرده که به طور مشترک تعدادی از اهداف متناقض را برای تطبیق وظایف متضاد مانند و تولید متن آموزش می دهد. مدل ما همچنین بهعنوان پایهای برای بسیاری از وظایف زبان بینایی، دستیابی به عملکرد پیشرفته یا رقابتی در بازیابی تصویر-متن و متن-تصویر، ویدئو QA، زیرنویس ویدئو، تشخیص واژگان باز و VQA عمل میکند. امیدواریم بتوان از آن برای کاربردهای چندوجهی بیشتر استفاده کرد.
سپاسگزاریها
اثر شرح داده شده توسط: Weicheng Kuo، AJ Piergiovanni، Dahun Kim، Xiyang Luo، Ben Caine، Wei Li، Abhijit Ogale، Luowei Zhou، Andrew Dai، Zhifeng Chen، Claire Cui، و Anelia Angelova نوشته شده است. متشکرم مجتبی سیدحسینی، ویجی واسودوان، پریا گویال، جیاهوی یو، زیروی وانگ، یونگهوی وو، رونزه لی، جی می، رادو سوریکوت، چینگ کینگ هوانگ، اندی لی، نان دو، یوکسین وو، تام دوریگ، پل ناتسف، زوبین گهارامان کمک و حمایت آنها