![]()
مدلهای یادگیری عمیق بزرگ در حال تبدیل شدن به نیروی کار انواع وظایف مهم یادگیری ماشینی (ML) هستند. با این حال، نشان داده شده است که بدون هیچ گونه حفاظتی، برای بازیگران بد، برای فاش کردن اطلاعات از نمونههای آموزشی فردی، میتوان به انواع مدلها، در همه روشها حمله کرد. به این ترتیب، محافظت در برابر این نوع نشت اطلاعات ضروری است.
حریم خصوصی دیفرانسیل (DP) حفاظت رسمی در برابر مهاجمی که قصد استخراج اطلاعات در مورد داده های آموزشی را دارد، فراهم می کند. محبوب ترین روش برای آموزش DP در یادگیری عمیق، شیب نزولی تصادفی خصوصی متفاوت (DP-SGD) است. دستور اصلی یک موضوع مشترک را در DP پیادهسازی میکند: خروجیهای یک الگوریتم با نویز برای پنهان کردن مشارکتهای هر ورودی جداگانه.
در عمل، آموزش DP برای مدل های بسیار بزرگ می تواند بسیار گران یا حتی بی اثر باشد. نه تنها هزینه محاسباتی معمولاً هنگام نیاز به تضمین حفظ حریم خصوصی افزایش می یابد، بلکه نویز نیز به نسبت افزایش می یابد. با توجه به این چالش ها، اخیراً علاقه زیادی به توسعه روش هایی وجود داشته است که این امکان را فراهم می کند کارآمد آموزش DP هدف توسعه روشهای ساده و کاربردی برای تولید مدلهای خصوصی در مقیاس بزرگ با کیفیت بالا است.
معیار طبقه بندی ImageNet یک بستر آزمایشی مؤثر برای این هدف است زیرا 1) یک کار چالش برانگیز حتی در محیط غیر خصوصی است که به مدل های به اندازه کافی بزرگ برای طبقه بندی موفقیت آمیز تعداد زیادی از تصاویر متنوع نیاز دارد و 2) عمومی و باز است. – مجموعه داده منبع، که سایر محققان می توانند به آن دسترسی داشته باشند و برای همکاری از آن استفاده کنند. با این رویکرد، محققان ممکن است یک موقعیت عملی را شبیهسازی کنند که در آن یک مدل بزرگ برای آموزش دادههای خصوصی با ضمانتهای DP مورد نیاز است.
برای این منظور، امروز در مورد بهبودهایی که در آموزش مدلهای خصوصی با کاربرد بالا و مقیاس بزرگ ایجاد کردهایم بحث میکنیم. اول، در “آموزش انتقال در مقیاس بزرگ برای طبقه بندی تصاویر خصوصی متفاوت”، ما نتایج قوی را در مورد وظیفه چالش برانگیز طبقه بندی تصاویر در مجموعه داده ImageNet-1k با محدودیت های DP به اشتراک می گذاریم. ما نشان میدهیم که با ترکیبی از یادگیری انتقال در مقیاس بزرگ و فراپارامترهای با دقت انتخاب شده، در واقع میتوان شکاف بین عملکرد خصوصی و غیرخصوصی را حتی در وظایف چالشبرانگیز و مدلهای با ابعاد بالا به میزان قابل توجهی کاهش داد. سپس در «طبقهبندی تصویر خصوصی متفاوت از ویژگیها»، ما بیشتر نشان میدهیم که تنظیم دقیق آخرین لایه مدل از پیش آموزشدیده با الگوریتمهای بهینهسازی پیشرفتهتر، عملکرد را حتی بیشتر بهبود میبخشد و منجر به پیشرفتهترین DP میشود. نتایج در بین انواع معیارهای طبقه بندی تصویر محبوب، از جمله ImageNet-1k. برای تشویق توسعه بیشتر در این جهت و فعال کردن سایر محققان برای تأیید یافتههای ما، کد منبع مرتبط را نیز منتشر میکنیم.
انتقال یادگیری و حریم خصوصی دیفرانسیل
ایده اصلی پشت یادگیری انتقالی استفاده مجدد از دانش به دست آمده از حل یک مسئله و سپس به کار بردن آن در یک مسئله مرتبط است. این به ویژه زمانی مفید است که داده های محدود یا با کیفیت پایین برای مشکل هدف در دسترس باشد زیرا به ما امکان می دهد از دانش به دست آمده از مجموعه داده های عمومی بزرگتر و متنوع تر استفاده کنیم.
در زمینه DP، یادگیری انتقال به عنوان یک تکنیک امیدوارکننده برای بهبود دقت مدلهای خصوصی، با بهرهگیری از دانش آموختهشده از وظایف پیشآموزشی، پدیدار شده است. به عنوان مثال، اگر یک مدل قبلاً روی یک مجموعه داده عمومی بزرگ برای یک کار حساس به حریم خصوصی مشابه آموزش داده شده باشد، می توان آن را روی یک مجموعه داده کوچکتر و خاص تر برای وظیفه DP هدف تنظیم کرد. به طور خاص، ابتدا یک مدل را روی یک مجموعه داده بزرگ بدون نگرانی در مورد حریم خصوصی از قبل آموزش میدهیم و سپس به صورت خصوصی مدل را روی مجموعه داده حساس تنظیم میکنیم. در کارمان، کارایی یادگیری انتقال DP را بهبود میبخشیم و آن را با شبیهسازی آموزش خصوصی در مجموعه دادههای در دسترس عموم، یعنی ImageNet-1k، CIFAR-100، و CIFAR-10 نشان میدهیم.
قبل از تمرین بهتر عملکرد DP را بهبود می بخشد
برای شروع بررسی اینکه چگونه یادگیری انتقال می تواند برای وظایف طبقه بندی تصاویر خصوصی متفاوت موثر باشد، ما به دقت فراپارامترهای موثر بر عملکرد DP را بررسی کردیم. با کمال تعجب، ما متوجه شدیم که با فراپارامترهای با دقت انتخاب شده (به عنوان مثال، مقداردهی اولیه لایه آخر به صفر و انتخاب اندازه های دسته بزرگ)، تنظیم دقیق فقط آخرین لایه از یک مدل از پیش آموزش دیده، پیشرفت های قابل توجهی را نسبت به خط پایه ایجاد می کند. آموزش فقط آخرین لایه نیز به طور قابل توجهی نسبت هزینه به کاربرد آموزش یک مدل طبقه بندی تصویر با کیفیت بالا با DP را بهبود می بخشد.
همانطور که در زیر نشان داده شده است، ما عملکرد بهترین پیشنهادات هایپرپارامتر را در ImageNet با و بدون حریم خصوصی و در انواع مدلها و اندازههای دادههای قبل از آموزش مقایسه میکنیم. ما متوجه شدیم که مقیاسبندی مدل و استفاده از مجموعه دادههای پیشآموزشی بزرگتر، شکاف در دقت ناشی از اضافه شدن تضمین حریم خصوصی را کاهش میدهد. به طور معمول، ضمانتهای حفظ حریم خصوصی یک سیستم با پارامتر ε مثبت مشخص میشوند که ε کوچکتر مربوط به حفظ حریم خصوصی بهتر است. در شکل زیر از ضمانت حفظ حریم خصوصی ε = 10 استفاده می کنیم.
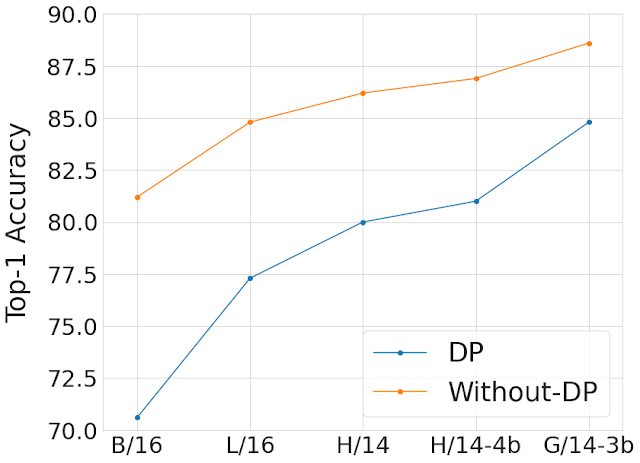 |
| مقایسه بهترین مدلهای ما با و بدون حریم خصوصی در ImageNet در میان اندازههای داده مدل و قبل از آموزش. محور X مدلهای مختلف Vision Transformer را که برای این مطالعه استفاده کردیم به ترتیب صعودی اندازه مدل از چپ به راست نشان میدهد. ما از JFT-300M برای پیشآموزش مدلهای B/16، L/16 و H/14، JFT-4B (نسخه بزرگتر JFT-3B) برای پیشآموزش H/14-4b و JFT-3B برای پیشآموزش G/14-3b استفاده کردیم. . ما این کار را به منظور بررسی اثربخشی مقیاسبندی مشترک مدل و مجموعه دادههای پیشآموزشی (JFT-3B یا 4B) انجام میدهیم. محور Y دقت Top-1 را در مجموعه آزمایشی ImageNet-1k پس از تنظیم دقیق مدل (به صورت خصوصی یا غیرخصوصی) با مجموعه آموزشی ImageNet-1k نشان می دهد. ما به طور مداوم می بینیم که مقیاس بندی مدل و اندازه مجموعه داده قبل از آموزش، شکاف در دقت ناشی از اضافه شدن ضمانت حفظ حریم خصوصی ε = 10 را کاهش می دهد. |
بهینه سازهای بهتر عملکرد DP را بهبود می بخشند
با کمال تعجب متوجه شدیم که آموزش خصوصی فقط آخرین لایه یک مدل از پیش آموزش دیده بهترین ابزار را با DP ارائه می دهد. در حالی که مطالعات گذشته [1, 2, 3] تا حد زیادی به استفاده از الگوریتمهای آموزش خصوصی متفاوت درجه اول مانند DP-SGD برای آموزش مدلهای بزرگ متکی است، در مورد خاص یادگیری خصوصی فقط آخرین لایه از ویژگیها، مشاهده میکنیم که بار محاسباتی اغلب به اندازهای کم است که امکان طرحهای بهینهسازی پیچیدهتر را فراهم میکند. از جمله روشهای مرتبه دوم (مثلاً روشهای نیوتن یا شبه نیوتن)، که میتوانند دقیقتر و همچنین از نظر محاسباتی گرانتر باشند.
در “طبقه بندی تصاویر خصوصی متفاوت از ویژگی ها”، ما به طور سیستماتیک تأثیر توابع از دست دادن و الگوریتم های بهینه سازی را بررسی می کنیم. ما متوجه شدیم که در حالی که رگرسیون لجستیک که معمولاً استفاده می شود بهتر از رگرسیون خطی در محیط غیر خصوصی عمل می کند، وضعیت در محیط خصوصی برعکس است: رگرسیون خطی حداقل مربعات از رگرسیون لجستیک هم از نظر حریم خصوصی و هم از دیدگاه محاسباتی بسیار مؤثرتر است. محدوده معمولی مقادیر ε ([1, 10]و حتی برای مقادیر اپسیلون سختتر (ε < 1) موثرتر است.
ما بیشتر با استفاده از روش DP نیوتن برای حل بررسی می کنیم لجستیکی پسرفت. ما متوجه شدیم که این هنوز با رگرسیون خطی DP در رژیم حفظ حریم خصوصی بالا بهتر است. در واقع، روش نیوتن شامل محاسبه یک Hessian (ماتریسی که اطلاعات مرتبه دوم را جمعآوری میکند) است و خصوصی کردن متفاوت این ماتریس مستلزم افزودن نویز بسیار بیشتری در رگرسیون لجستیک نسبت به رگرسیون خطی است که دارای هسین بسیار ساختار یافته است.
با تکیه بر این مشاهدات، روشی را معرفی می کنیم که آن را فراخوانی می کنیم SGD خصوصی متفاوت با کوواریانس ویژگی (DP-FC)، که در آن به سادگی هسین را در رگرسیون لجستیک با کوواریانس ویژگی خصوصی شده جایگزین می کنیم. از آنجایی که کوواریانس ویژگی فقط به ورودیها بستگی دارد (و نه به پارامترهای مدل و نه برچسبهای کلاس)، ما میتوانیم آن را در کلاسها و تکرارهای آموزشی به اشتراک بگذاریم، بنابراین میزان نویز مورد نیاز برای محافظت از آن را تا حد زیادی کاهش میدهیم. این به ما امکان می دهد مزایای استفاده از رگرسیون لجستیک را با حفاظت از حریم خصوصی کارآمد رگرسیون خطی ترکیب کنیم، که منجر به بهبود مبادله حریم خصوصی و ابزار مفید می شود.
با DP-FC، تنها با انجام تنظیمات دقیق DP بر روی ویژگی های استخراج شده از یک ابزار قدرتمند، به طور قابل توجهی در سه معیار طبقه بندی تصاویر خصوصی، یعنی ImageNet-1k، CIFAR-10 و CIFAR-100، از نتایج پیشرفته قبلی پیشی می گیریم. مدل از پیش آموزش دیده
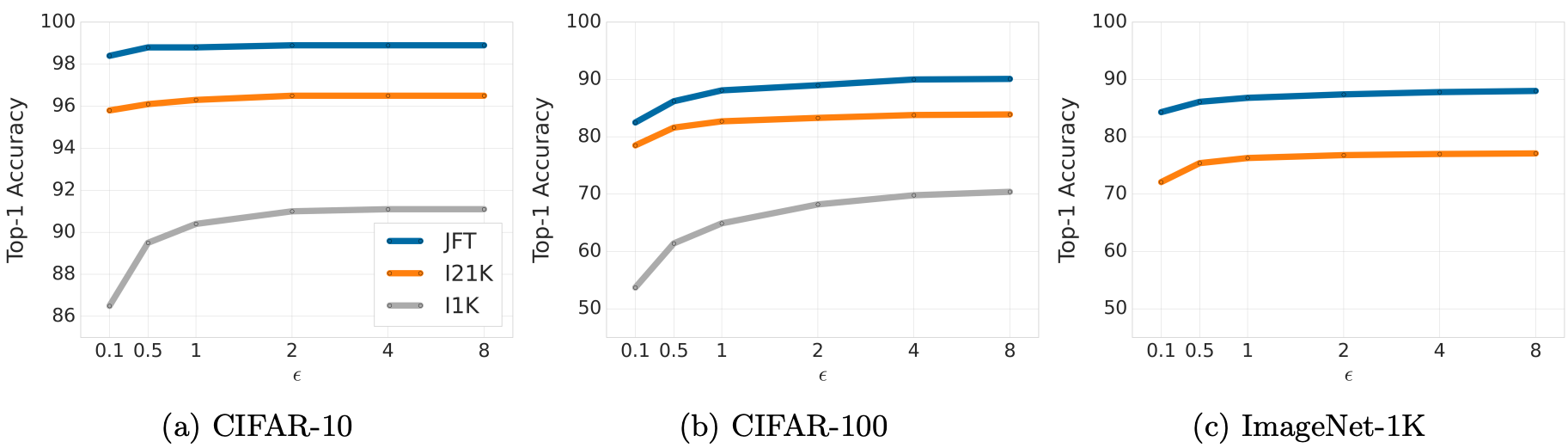 |
| مقایسه دقت بالای 1 (محور Y) با تنظیم دقیق خصوصی با استفاده از روش DP-FC در هر سه مجموعه داده در محدوده ε (محور X). مشاهده میکنیم که پیشآموزش بهتر حتی بیشتر به مقادیر کمتر ε (ضمانت حفظ حریم خصوصی سختتر) کمک میکند. |
نتیجه
ما نشان میدهیم که پیشآموزش در مقیاس بزرگ بر روی یک مجموعه داده عمومی یک استراتژی مؤثر برای به دست آوردن نتایج خوب در صورت تنظیم دقیق خصوصی است. علاوه بر این، مقیاسبندی اندازه مدل و مجموعه دادههای قبل از آموزش عملکرد مدل خصوصی را بهبود میبخشد و شکاف کیفیت را در مقایسه با مدل غیرخصوصی کاهش میدهد. ما بیشتر استراتژی هایی را برای استفاده موثر از یادگیری انتقالی برای DP ارائه می کنیم. توجه داشته باشید که این کار دارای چندین محدودیت است که ارزش در نظر گرفتن دارد – از همه مهمتر رویکرد ما به در دسترس بودن یک مجموعه داده عمومی بزرگ و قابل اعتماد است که می تواند برای منبع و بررسی چالش برانگیز باشد. امیدواریم کار ما برای آموزش مدل های بزرگ با تضمین حریم خصوصی معنی دار مفید باشد!
سپاسگزاریها
علاوه بر نویسندگان این وبلاگ، این تحقیق توسط Abhradeep Thakurta، Alex Kurakin و Ashok Cutkosky انجام شده است. ما همچنین از توسعه دهندگان کتابخانه های Jax، Flax و Scenic سپاسگزاریم. به طور خاص، از مصطفی دهقانی برای کمک به ما در زمینه خطوط پایه دید منظره و با کارایی بالا و لوکاس بیر برای کمک به حذف داده های JFT تشکر می کنیم. همچنین از Li Zhang، Emil Praun، Andreas Terzis، Shuang Song، Pierre Tholoniat، Roxana Geambasu، و Steve Chien برای تحریک بحث در مورد حریم خصوصی متفاوت در طول پروژه سپاسگزاریم. علاوه بر این، ما از داوران ناشناس، گوتام کامات و وارون کاناد برای بازخورد مفید در طول فرآیند انتشار تشکر می کنیم. در نهایت، مایلیم از جان اندرسون و کورینا کورتس از Google Research، Borja Balle، Soham De، Sam Smith، Leonard Berrada و Jamie Hayes از DeepMind برای بازخورد سخاوتمندانه تشکر کنیم.