پیش از این، طرح 1000 زبان و مدل جهانی گفتار را با هدف در دسترس قرار دادن فناوریهای گفتار و زبان برای میلیاردها کاربر در سراسر جهان ارائه کردیم. بخشی از این تعهد شامل توسعه فناوریهای سنتز گفتار با کیفیت بالا است که بر اساس پروژههایی مانند VDTTS و AudioLM برای کاربرانی که به زبانهای مختلف صحبت میکنند، ساخته میشود.
 |
پس از توسعه یک مدل جدید، باید ارزیابی کرد که آیا گفتاری که تولید میکند دقیق و طبیعی است: محتوا باید با کار مرتبط باشد، تلفظ صحیح، لحن مناسب باشد، و نباید هیچ گونه مصنوعات صوتی مانند ترک یا سیگنال مرتبط باشد. سر و صدا. چنین ارزیابی یک گلوگاه بزرگ در توسعه سیستم های گفتار چند زبانه است.
محبوبترین روش برای ارزیابی کیفیت مدلهای سنتز گفتار، ارزیابی انسانی است: یک مهندس تبدیل متن به گفتار (TTS) چند هزار گفته از آخرین مدل تولید میکند، آنها را برای ارزیابی انسانی ارسال میکند و چند روز بعد نتایج را دریافت میکند. این مرحله ارزیابی معمولاً شامل تست های شنیداری، که طی آن ده ها حاشیه نویس یکی پس از دیگری به جملات گوش می دهند تا بفهمند چقدر طبیعی به نظر می رسند. در حالی که انسان ها هنوز در تشخیص طبیعی به نظر رسیدن یک متن شکست نخورده اند، این فرآیند می تواند غیرعملی باشد – به خصوص در مراحل اولیه پروژه های تحقیقاتی، زمانی که مهندسان برای آزمایش و استراتژی مجدد رویکرد خود به بازخورد سریع نیاز دارند. ارزیابی انسانی پرهزینه، زمانبر است و ممکن است به دلیل در دسترس بودن رتبهدهندهها برای زبانهای مورد علاقه محدود شود.
مانع دیگر پیشرفت این است که پروژهها و مؤسسات مختلف معمولاً از رتبهبندیها، پلتفرمها و پروتکلهای مختلفی استفاده میکنند که مقایسه سیب به سیب را غیرممکن میکند. در این راستا، فناوریهای سنتز گفتار از تولید متن عقب هستند، جایی که محققان مدتهاست ارزیابی انسانی را با معیارهای خودکار مانند BLEU یا اخیراً BLEURT تکمیل کردهاند.
در “SQuId: اندازه گیری طبیعی بودن گفتار در بسیاری از زبان ها” که در ICASSP 2023 ارائه می شود، SQuId (شناسایی کیفیت گفتار) را معرفی می کنیم، یک مدل رگرسیون پارامتر 600M که توصیف می کند تا چه حد یک قطعه گفتار طبیعی به نظر می رسد. SQuId بر اساس mSLAM (یک مدل گفتار-متن از پیش آموزشدیده توسعهیافته توسط Google) است که روی بیش از یک میلیون رتبهبندی کیفیت در ۴۲ زبان تنظیم شده و در ۶۵ زبان آزمایش شده است. ما نشان میدهیم که چگونه میتوان از SQuId برای تکمیل رتبهبندیهای انسانی برای ارزیابی استفاده کرد. زبانهای بسیار. این بزرگترین تلاش منتشر شده از این نوع تا به امروز است.
ارزیابی TTS با SQuId
فرضیه اصلی پشت SQuId این است که آموزش یک مدل رگرسیون بر روی رتبهبندیهای قبلاً جمعآوریشده میتواند روشی کمهزینه برای ارزیابی کیفیت یک مدل TTS در اختیار ما قرار دهد. بنابراین، این مدل میتواند افزودهای ارزشمند به جعبه ابزار ارزیابی محقق TTS باشد و جایگزینی تقریباً فوری و البته کمتر دقیق برای ارزیابی انسانی ارائه دهد.
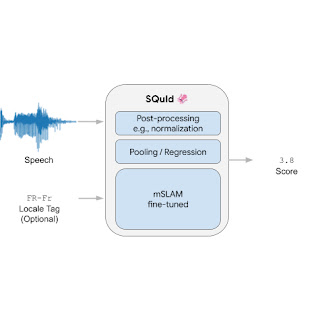
SQuId یک گفته را به عنوان ورودی و یک برچسب محلی اختیاری می گیرد (یعنی یک نوع محلی از یک زبان، مانند “پرتغالی برزیل” یا “انگلیسی بریتانیایی”). نمره ای بین 1 تا 5 برمی گرداند که نشان می دهد شکل موج چقدر طبیعی به نظر می رسد، با مقدار بالاتر نشان دهنده شکل موج طبیعی تر است.
در داخل، مدل شامل سه جزء است: (1) یک رمزگذار، (2) یک لایه ادغام / رگرسیون، و (3) یک لایه کاملا متصل. اول، رمزگذار یک طیفگرام را بهعنوان ورودی میگیرد و آن را در یک ماتریس دو بعدی کوچکتر که شامل 3200 بردار با اندازه 1024 است، جاسازی میکند، جایی که هر بردار یک مرحله زمانی را رمزگذاری میکند. لایه ادغام / رگرسیون بردارها را جمع می کند، تگ محلی را اضافه می کند و نتیجه را در یک لایه کاملاً متصل تغذیه می کند که یک امتیاز را برمی گرداند. در نهایت، ما از پس پردازش ویژه برنامه استفاده می کنیم که امتیاز را مجدداً مقیاس یا عادی می کند تا در محدوده [1, 5] محدوده، که برای طبیعی بودن رتبه بندی های انسانی رایج است. ما کل مدل را از انتها به انتها با از دست دادن رگرسیون آموزش می دهیم.
رمزگذار تا حد زیادی بزرگترین و مهمترین قطعه مدل است. ما از mSLAM استفاده کردیم، یک Conformer با پارامتر 600M که از قبل در گفتار (51 زبان) و متن (101 زبان) آموزش دیده بود.
 |
| مدل SQuId. |
برای آموزش و ارزیابی مدل، مجموعه SQuId را ایجاد کردیم: مجموعهای از 1.9 میلیون بیان رتبهبندی شده در 66 زبان، که برای بیش از 2000 پروژه TTS تحقیق و محصول جمعآوری شده است. مجموعه SQuId مجموعهای از سیستمها، از جمله مدلهای متصل و عصبی را برای طیف وسیعی از موارد استفاده، مانند مسیرهای رانندگی و دستیارهای مجازی، پوشش میدهد. بازرسی دستی نشان میدهد که SQuId در معرض طیف گستردهای از خطاهای TTS، مانند مصنوعات صوتی (به عنوان مثال، ترکها و پاپها)، عروض نادرست (مثلاً سؤالات بدون آهنگهای افزایشیافته در انگلیسی)، خطاهای عادی سازی متن (مثلاً، شفاهی کردن “7 است. /7 بهعنوان «هفت تقسیم بر هفت» به جای «هفتم ژوئیه»)، یا اشتباهات تلفظی (به عنوان مثال، تلفظ «سخت» به عنوان «انگشت پا»).
یک مسئله رایج که هنگام آموزش سیستم های چند زبانه مطرح می شود این است که داده های آموزشی ممکن است به طور یکسان برای همه زبان های مورد علاقه در دسترس نباشد. SQuId نیز از این قاعده مستثنی نبود. شکل زیر اندازه بدنه هر منطقه را نشان می دهد. می بینیم که توزیع عمدتاً تحت سلطه انگلیسی ایالات متحده است.
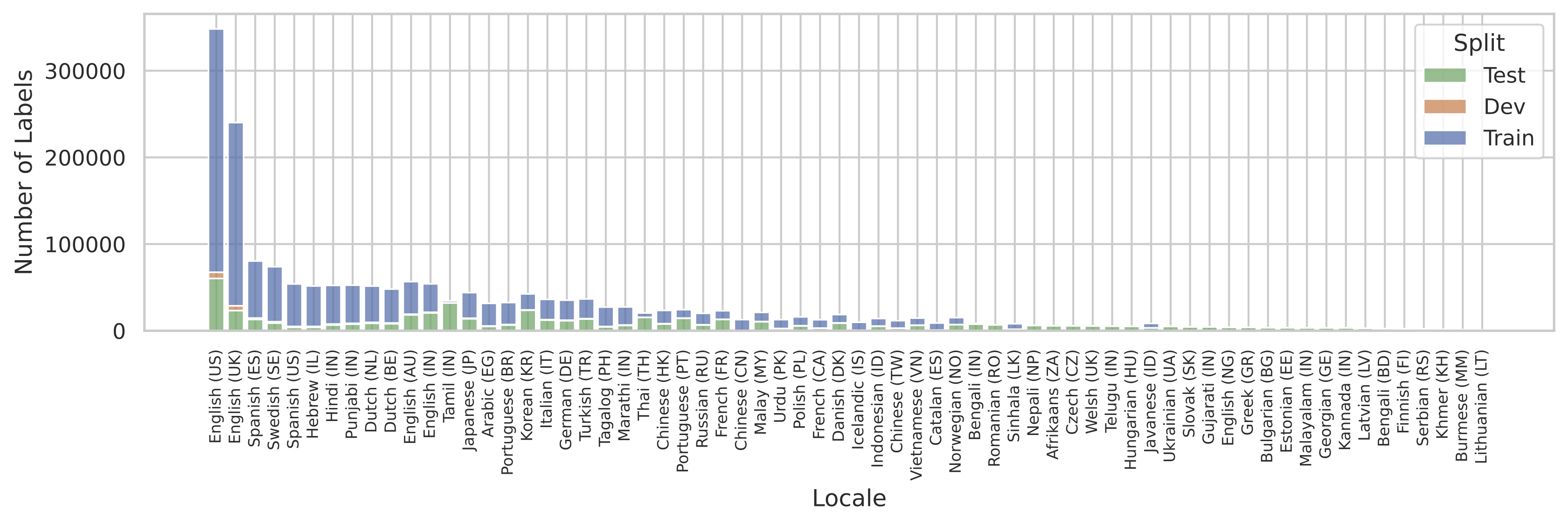 |
| توزیع محلی در مجموعه داده SQuId. |
چگونه میتوانیم عملکرد خوبی برای همه زبانها ارائه دهیم، در حالی که چنین تغییراتی وجود دارد؟ با الهام از کارهای قبلی در زمینه ترجمه ماشینی، و همچنین کارهای گذشته از ادبیات گفتار، تصمیم گرفتیم به جای استفاده از مدل های جداگانه برای هر زبان، یک مدل را برای همه زبان ها آموزش دهیم. فرضیه این است که اگر مدل به اندازه کافی بزرگ باشد، پس انتقال متقابل محلی می تواند رخ دهد: دقت مدل در هر منطقه در نتیجه آموزش مشترک بر روی سایر مکان ها بهبود می یابد. همانطور که آزمایشهای ما نشان میدهد، مکان متقابل ثابت میکند که محرک قدرتمندی برای عملکرد است.
نتایج تجربی
برای درک عملکرد کلی SQuId، ما آن را با یک مدل سفارشی Big-SSL-MOS (شرح شده در مقاله)، یک خط پایه رقابتی با الهام از MOS-SSL، یک سیستم ارزیابی TTS پیشرفته مقایسه می کنیم. Big-SSL-MOS مبتنی بر w2v-BERT است و بر روی مجموعه داده چالش VoiceMOS’22، محبوب ترین مجموعه داده در زمان ارزیابی آموزش دیده است. ما با انواع مختلفی از مدل آزمایش کردیم و متوجه شدیم که SQuId تا 50.0٪ دقیق تر است.
 |
| SQuId در مقابل خطوط پایه پیشرفته. ما توافق را با رتبهبندیهای انسانی با استفاده از کندال تاو اندازهگیری میکنیم، جایی که مقدار بالاتر نشاندهنده دقت بهتر است. |
برای درک تأثیر انتقال متقاطع محلی، ما یک سری مطالعات فرسایشی انجام می دهیم. ما مقدار محلیهای معرفیشده در مجموعه آموزشی را تغییر میدهیم و تأثیر آن را بر دقت SQuId اندازهگیری میکنیم. در انگلیسی، که در حال حاضر بیش از حد در مجموعه داده نشان داده شده است، تأثیر افزودن مناطق ناچیز است.
 |
| عملکرد SQuId در انگلیسی ایالات متحده، با استفاده از 1، 8، و 42 زبان در هنگام تنظیم دقیق. |
با این حال، انتقال متقابل محلی برای بسیاری از مناطق دیگر بسیار مؤثرتر است:
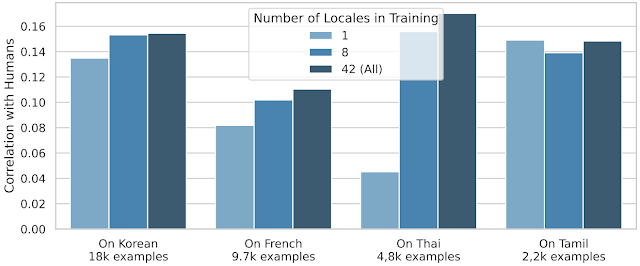 |
| عملکرد SQuId در چهار منطقه منتخب (کره ای، فرانسوی، تایلندی و تامیل)، با استفاده از 1، 8، و 42 محلی در طول تنظیم دقیق. برای هر محلی، اندازه مجموعه آموزشی را نیز ارائه می دهیم. |
برای اینکه انتقال را به حد خود برسانیم، ما 24 لوکال را در طول آموزش نگه داشتیم و از آنها به طور انحصاری برای آزمایش استفاده کردیم. بنابراین، اندازهگیری میکنیم که SQuId تا چه حد میتواند با زبانهایی برخورد کند که قبلاً هرگز ندیده است. نمودار زیر نشان می دهد که اگرچه اثر یکنواخت نیست، انتقال متقاطع محلی کار می کند.
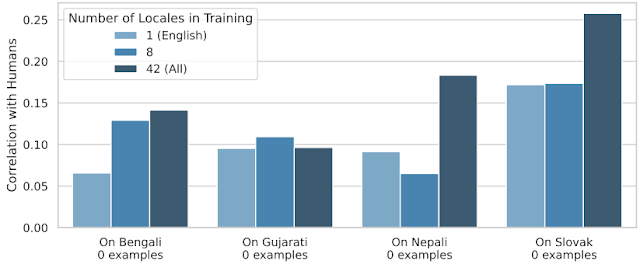 |
| عملکرد SQuId در چهار مکان “صفر شات”. با استفاده از 1، 8، و 42 محلی در هنگام تنظیم دقیق. |
چه زمانی cross-locale عمل می کند و چگونه؟ ما ابطالهای بیشتری را در این مقاله ارائه میکنیم و نشان میدهیم که در حالی که شباهت زبانی نقش دارد (به عنوان مثال، آموزش پرتغالی برزیلی به پرتغالی اروپایی کمک میکند) اما بهطور شگفتانگیزی فاصله زیادی با این موضوع دارد که تنها عامل مهم باشد.
نتیجه گیری و کار آینده
ما SQuId را معرفی میکنیم، یک مدل رگرسیون پارامتر 600M که از مجموعه داده SQuId و یادگیری محلی برای ارزیابی کیفیت گفتار و توصیف طبیعی بودن آن استفاده میکند. ما نشان میدهیم که SQuId میتواند در ارزیابی بسیاری از زبانها مکمل ارزیابهای انسانی باشد. کارهای آینده شامل بهبود دقت، گسترش دامنه زبان های تحت پوشش، و مقابله با انواع خطاهای جدید است.
سپاسگزاریها
نویسنده این پست اکنون بخشی از Google DeepMind است. با تشکر فراوان از همه نویسندگان مقاله: آنکور باپنا، جاشوا کمپ، دیانا مکینون، آنکور پی پاریک و جیسون ریسا.