وظیفه تعیین شباهت بین تصاویر یک مشکل باز در بینایی کامپیوتری است و برای ارزیابی واقعی بودن تصاویر تولید شده توسط ماشین بسیار مهم است. اگرچه تعدادی روش ساده برای تخمین شباهت تصویر وجود دارد (مثلاً معیارهای سطح پایین که تفاوتهای پیکسل را اندازهگیری میکنند، مانند FSIM و SSIM)، در بسیاری از موارد، تفاوتهای شباهت اندازهگیری شده با تفاوتهای درک شده توسط یک فرد مطابقت ندارد. با این حال، کار اخیر نشان داده است که نمایشهای میانی طبقهبندیکنندههای شبکه عصبی، مانند AlexNet، VGG و SqueezeNet آموزشدیدهشده در ImageNet، شباهت ادراکی را بهعنوان یک ویژگی نوظهور نشان میدهند. یعنی فواصل اقلیدسی بین بازنماییهای کدگذاریشده تصاویر توسط مدلهای آموزشدیده ImageNet با قضاوت فرد در مورد تفاوتهای بین تصاویر بسیار بهتر از تخمین شباهت ادراکی مستقیماً از پیکسلهای تصویر مرتبط است.
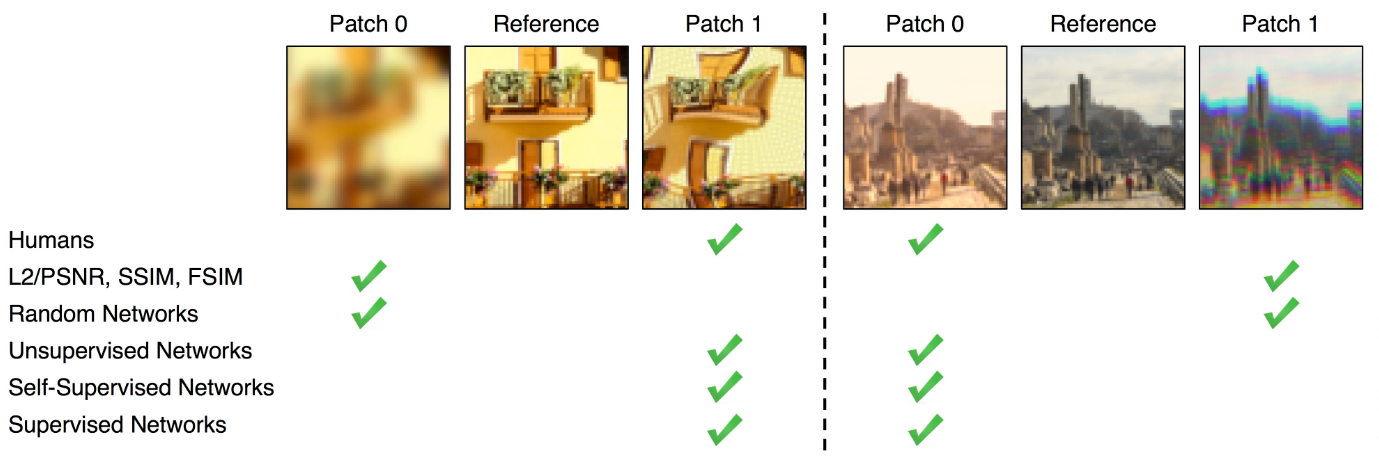 |
| دو مجموعه از تصاویر نمونه از مجموعه داده BAPPS. شبکه های آموزش دیده در مقایسه با معیارهای سطح پایین (PSNR، SSIM، FSIM) با قضاوت های انسانی بیشتر موافق هستند. منبع تصویر: ژانگ و همکاران (2018). |
در “آیا طبقه بندی کننده های ImageNet بهتر شباهت ادراکی را بهتر ارزیابی می کنند؟” منتشر شده در معاملات در تحقیقات یادگیری ماشینی، ما یک مطالعه تجربی گسترده را در مورد رابطه بین دقت طبقهبندیکنندههای ImageNet و توانایی ظاهری آنها برای گرفتن شباهت ادراکی انجام میدهیم. برای ارزیابی این توانایی اضطراری، ما کار قبلی را در اندازهگیری نمرات ادراکی (PS) دنبال میکنیم، که تقریباً همبستگی بین ترجیحات انسان با مدلی برای شباهت تصویر در مجموعه داده BAPPS است. در حالی که کار قبلی نسل اول طبقهبندیکنندههای ImageNet، مانند AlexNet، SqueezeNet و VGG را مورد مطالعه قرار داد، ما به طور قابلتوجهی دامنه تحلیل را با ترکیب طبقهبندیکنندههای مدرن، مانند ResNets و Vision Transformers (ViTs)، در طیف گستردهای از پارامترها افزایش دادیم.
رابطه بین دقت و تشابه ادراکی
به خوبی ثابت شده است که ویژگی های آموخته شده از طریق آموزش در ImageNet به خوبی به تعدادی از وظایف پایین دستی منتقل می شود و آموزش پیش آموزش ImageNet را به یک دستور العمل استاندارد تبدیل می کند. علاوه بر این، دقت بهتر در ImageNet معمولاً مستلزم عملکرد بهتر در مجموعه متنوعی از وظایف پایین دستی است، مانند استحکام در برابر فسادهای رایج، تعمیم خارج از توزیع و یادگیری انتقال در مجموعه داده های طبقه بندی کوچکتر. برخلاف شواهد رایج که نشان میدهد مدلهای با دقت اعتبارسنجی بالا در ImageNet احتمالاً بهتر به وظایف دیگر منتقل میشوند، بهطور شگفتانگیزی، متوجه میشویم که نمایشهای مدلهای ImageNet کمتر با دقت اعتبارسنجی متوسط، بهترین امتیازات ادراکی را به دست میآورند.
 |
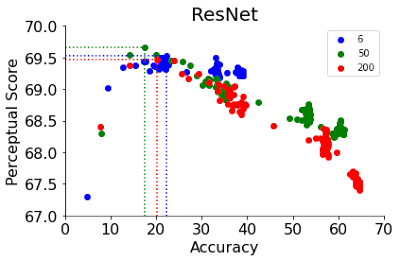
| نمودار نمرات ادراکی (PS) در مجموعه داده 64 × 64 BAPPS (محور y) در برابر دقت اعتبارسنجی ImageNet 64 × 64 (محور x). هر نقطه آبی نشان دهنده یک طبقه بندی ImageNet است. طبقهبندیکنندههای ImageNet بهتر تا یک نقطه خاص (آبی تیره) به PS بهتری دست مییابند که فراتر از آن، بهبود دقت PS را کاهش میدهد. بهترین PS توسط طبقه بندی کننده ها با دقت متوسط (20.0-40.0) به دست می آید. |
ما تغییرات نمرات ادراکی را به عنوان تابعی از فراپارامترهای شبکه عصبی مورد مطالعه قرار می دهیم: عرض، عمق، تعداد مراحل تمرین، کاهش وزن، هموارسازی برچسب و ترک تحصیل. برای هر هایپرپارامتر، یک دقت بهینه وجود دارد که تا آن حد بهبود دقت PS را بهبود می بخشد. این بهینه نسبتاً کم است و خیلی زود در جابجایی هایپرپارامتر به دست می آید. فراتر از این نقطه، دقت طبقهبندیکننده بهبود یافته با PS بدتری مطابقت دارد.
به عنوان مثال، ما تنوع PS را با توجه به دو فراپارامتر ارائه میکنیم: مراحل آموزش در ResNets و عرض در ViTs. PS ResNet-50 و ResNet-200 خیلی زود در چند دوره اول آموزش به اوج می رسد. پس از پیک، PS طبقه بندی کننده های بهتر به شدت کاهش می یابد. ResNet ها با یک زمان بندی نرخ یادگیری آموزش داده می شوند که باعث افزایش گام به گام دقت به عنوان تابعی از مراحل آموزش می شود. جالب اینجاست که پس از پیک، آنها همچنین کاهش گام به گام در PS را نشان می دهند که با این افزایش دقت گام به گام مطابقت دارد.
 |
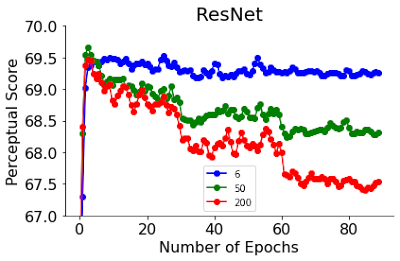 |
| ResNets های با توقف زودهنگام بهترین PS را در عمق های مختلف 6، 50 و 200 به دست می آورند. |
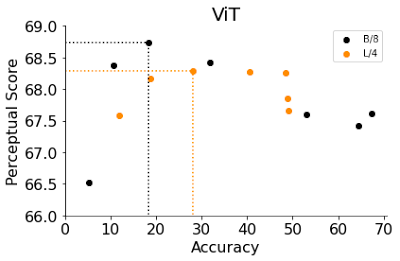
ViT ها شامل مجموعه ای از بلوک های ترانسفورماتور هستند که روی تصویر ورودی اعمال می شوند. عرض یک مدل ViT تعداد نورون های خروجی یک بلوک ترانسفورماتور منفرد است. افزایش عرض آن یک راه موثر برای بهبود دقت آن است. در اینجا، عرض دو نوع ViT، B/8 و L/4 (یعنی مدلهای Base و Large ViT با اندازههای پچ 4 و 8) را تغییر میدهیم و دقت و PS را ارزیابی میکنیم. مشابه مشاهدات ما با ResNets های اولیه متوقف شده، ViT های باریک تر با دقت کمتر بهتر از عرض های پیش فرض عمل می کنند. با کمال تعجب، عرض بهینه ViT-B/8 و ViT-L/4 6 و 12 درصد از عرض های پیش فرض آنها است. برای یک لیست جامع تر از آزمایشات مربوط به سایر پارامترها مانند عرض، عمق، تعداد مراحل تمرین، کاهش وزن، هموارسازی برچسب و حذف در هر دو ResNets و ViTs، مقاله ما را بررسی کنید.
 |
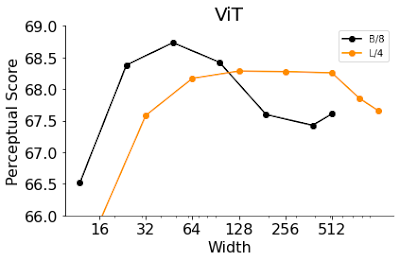 |
| ViT های باریک به بهترین PS می رسند. |
کاهش مقیاس مدل ها نمرات ادراکی را بهبود می بخشد
نتایج ما یک استراتژی ساده را برای بهبود PS یک معماری تجویز می کند: مدل را کاهش دهید تا دقت آن را کاهش دهید تا زمانی که به نمره ادراکی بهینه برسد. جدول زیر بهبودهای PS را که با کوچک کردن هر مدل در هر هایپرپارامتر به دست میآید، خلاصه میکند. به جز ViT-L/4، توقف زودهنگام بدون توجه به معماری، بالاترین پیشرفت را در PS به همراه دارد. علاوه بر این، توقف زودهنگام کارآمدترین استراتژی است زیرا نیازی به جستجوی شبکه گران قیمت نیست.
| مدل | پیش فرض | عرض | عمق | وزن پوسیدگی |
مرکزی برش |
قطار – تعلیم دادن مراحل |
بهترین |
| ResNet-6 | 69.1 | +0.4 | – | +0.3 | 0.0 | +0.5 | 69.6 |
| ResNet-50 | 68.2 | +0.4 | – | +0.7 | +0.7 | +1.5 | 69.7 |
| ResNet-200 | 67.6 | +0.2 | – | +1.3 | +1.2 | +1.9 | 69.5 |
| ViT B/8 | 67.6 | +1.1 | +1.0 | +1.3 | +0.9 | +1.1 | 68.9 |
| سرعت L/4 | 67.9 | +0.4 | +0.4 | -0.1 | -1.1 | +0.5 | 68.4 |
| امتیاز ادراکی با کوچک کردن مدلهای ImageNet بهبود مییابد. هر مقدار نشان دهنده بهبودی است که با کوچک کردن یک مدل در یک هایپرپارامتر معین نسبت به مدل با ابرپارامترهای پیشفرض به دست میآید. |
توابع ادراکی جهانی
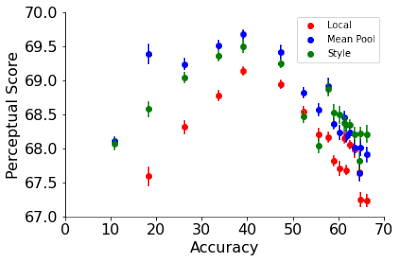
در کار قبلی، تابع شباهت ادراکی با استفاده از فواصل اقلیدسی در ابعاد فضایی تصویر محاسبه شد. این یک مطابقت مستقیم بین پیکسلها را فرض میکند، که ممکن است برای تصاویر تابیده، ترجمه شده یا چرخیده برقرار نباشد. در عوض، ما دو تابع ادراکی را اتخاذ میکنیم که بر بازنمایی جهانی تصاویر متکی هستند، یعنی تابع از دست دادن سبک از کار انتقال سبک عصبی که شباهت سبکی بین دو تصویر را ثبت میکند و یک تابع فاصله میانگین استخر نرمال شده. تابع سبک از دست دادن ماتریس همبستگی متقاطع بین کانالی را بین دو تصویر مقایسه می کند در حالی که تابع میانگین میانگین نمایش های جهانی میانگین مکانی را مقایسه می کند.
 |
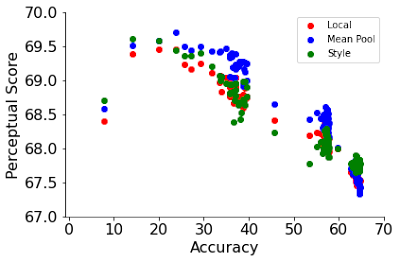 |
| توابع ادراکی جهانی به طور مداوم PS را در هر دو شبکه آموزش دیده با فراپارامترهای پیش فرض بهبود می بخشد (بالا) و ResNet-200 به عنوان تابعی از دوره های قطار (پایین). |
ما تعدادی فرضیه را بررسی می کنیم تا رابطه بین دقت و PS را توضیح دهیم و با چند بینش اضافی همراه شویم. به عنوان مثال، دقت مدلهای بدون اتصال پرش معمولاً با PS همبستگی معکوس دارد و لایههای نزدیک به ورودی به طور متوسط PS کمتری در مقایسه با لایههای نزدیک به خروجی دارند. برای کاوش بیشتر در مورد حساسیت اعوجاج، دانه بندی کلاس ImageNet و حساسیت فرکانس فضایی، مقاله ما را بررسی کنید.
نتیجه
در این مقاله، این سوال را بررسی میکنیم که آیا بهبود دقت طبقهبندی معیارهای ادراکی بهتری را به همراه دارد. ما رابطه بین دقت و PS در ResNets و ViTs را در بسیاری از فراپارامترهای مختلف مطالعه میکنیم و مشاهده میکنیم که PS یک رابطه معکوس-U با دقت نشان میدهد، که در آن دقت تا یک نقطه خاص با PS ارتباط دارد و سپس یک همبستگی معکوس نشان میدهد. در نهایت، در مقاله ما، به طور مفصل تعدادی از توضیحات را برای رابطه مشاهده شده بین دقت و PS، شامل اتصالات پرش، توابع شباهت جهانی، حساسیت اعوجاج، امتیازات ادراکی لایهای، حساسیت فرکانس فضایی و دانهبندی کلاس ImageNet مورد بحث قرار میدهیم. در حالی که توضیح دقیق مبادله مشاهده شده بین دقت ImageNet و شباهت ادراکی یک راز است، ما هیجان زده هستیم که مقاله ما در را برای تحقیقات بیشتر در این زمینه باز می کند.
سپاسگزاریها
این کار مشترک با نیل هولزبی و نال کالچبرنر است. همچنین مایلیم از باسیل مصطفی، کوین سورسکی، سایمون کورنبلیت، یوهانس باله، مایک موزر، محمد نوروزی و جاشا سول-دیکستین برای بحث های مفید تشکر کنیم.