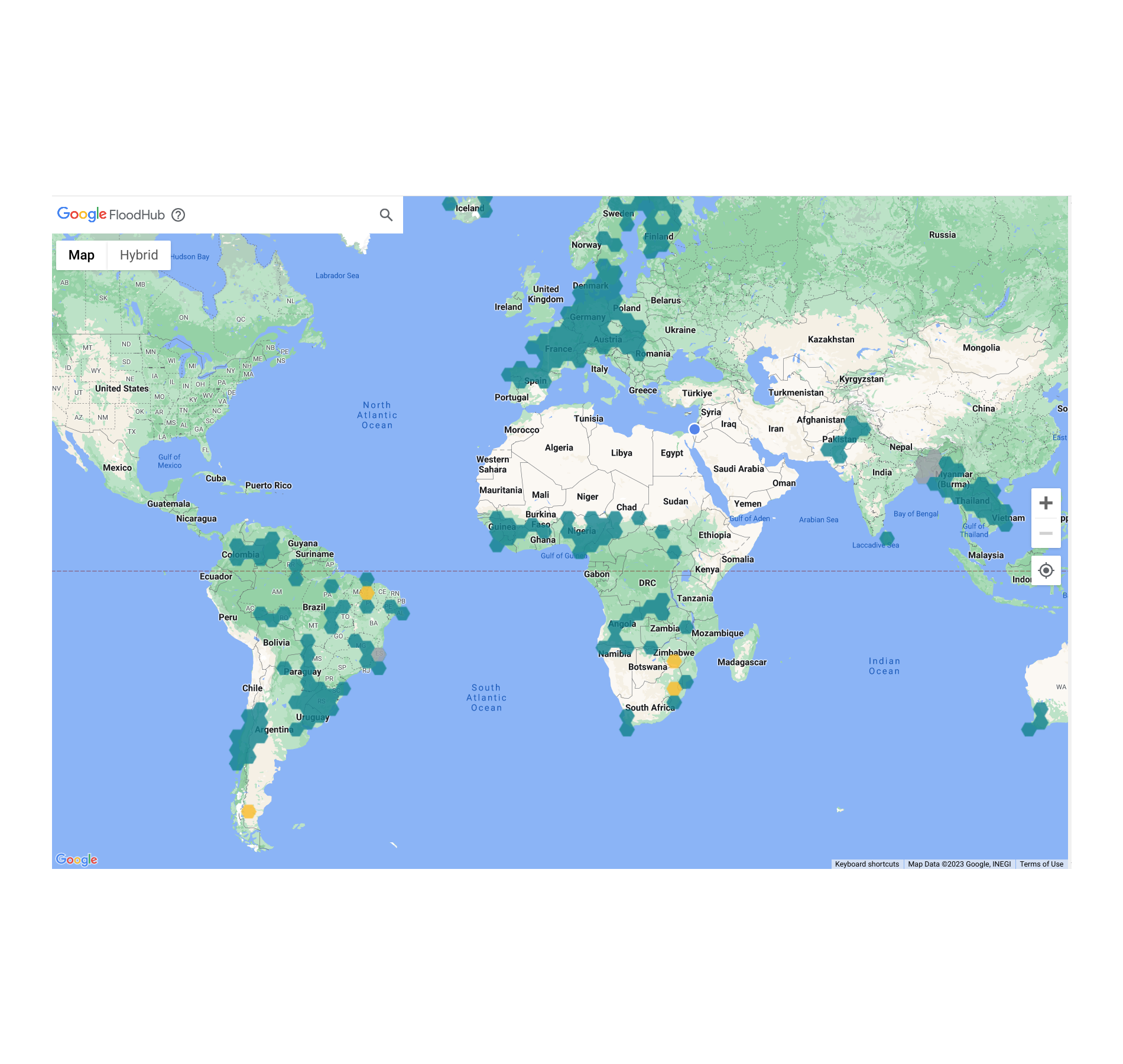
سیل شایع ترین نوع بلایای طبیعی است که سالانه بیش از 250 میلیون نفر را در سراسر جهان تحت تاثیر قرار می دهد. بهعنوان بخشی از «پاسخ به بحران Google» و تلاشهایمان برای رسیدگی به بحران آبوهوایی، از مدلهای یادگیری ماشینی (ML) برای پیشبینی سیل استفاده میکنیم تا به مردم مناطقی که قبل از وقوع فاجعه تحت تأثیر قرار گرفتهاند، هشدار دهیم.
همکاری بین محققان در صنعت و دانشگاه برای تسریع پیشرفت به سمت اهداف متقابل در تحقیقات مرتبط با ML ضروری است. در واقع، رویکرد فعلی پیشبینی سیل مبتنی بر ML Google با همکاری محققان (1، 2) در دانشگاه یوهانس کپلر در وین، اتریش، دانشگاه آلاباما و دانشگاه عبری اورشلیم و دیگران توسعه یافته است.
امروز در مورد کارگاه آموزشی پیشبینی سیل اخیر با یادگیری ماشینی صحبت میکنیم، که تلاشهایی را برای گردهمآوری محققان از Google و سایر دانشگاهها و سازمانها برای ارتقای درک ما از رفتار و پیشبینی سیل، و ایجاد راهحلهای قویتر برای تشخیص زودهنگام و هشدار نشان میدهد. ما همچنین پروژه Caravan را مورد بحث قرار می دهیم که به ایجاد یک مخزن منبع باز برای داده های جریان جهانی کمک می کند و خود نمونه ای از همکاری است که از کارگاه قبلی Flood Forecasting Meets Learning Machine ایجاد شده است.
2023 یادگیری ماشینی با کارگاه پیش بینی سیل ملاقات می کند
چهارمین کارگاه سالانه Google Machine Learning Meets Forecasting Workshop در ژانویه برگزار شد. این کارگاه مجازی دو روزه میزبان بیش از 100 شرکت کننده از 32 دانشگاه، 20 سازمان دولتی و غیردولتی و 11 شرکت خصوصی بود. این انجمن فرصتی را برای هیدرولوژیستها، دانشمندان کامپیوتر و امدادگران فراهم کرد تا در مورد چالشها و تلاشها در جهت بهبود پیشبینی سیلهای جهانی، همگام شدن با پیشرفتهای فنآوری پیشرفته و ادغام دانش حوزه در رویکردهای پیشبینی مبتنی بر ML بحث کنند. .
این رویداد شامل صحبتهایی از شش سخنران دعوت شده، یک سری جلسات بحث گروهی کوچک با تمرکز بر مدلسازی هیدرولوژیکی، نقشهبرداری غرقاب، و موضوعات مرتبط با هشدار خطر، و همچنین ارائهای توسط Google در FloodHub بود که دسترسی عمومی و رایگان به پیشبینی سیل Google، تا 7 روز قبل.
 |
سخنرانان دعوت شده در این کارگاه عبارتند از:
ارائه ها را می توان در یوتیوب مشاهده کرد:
پیشبینی سیل 2023 با گفتگوهای یادگیری ماشینی روز 1 ملاقات میکند
پیشبینی سیل 2023 با بحثهای یادگیری ماشینی روز 2 دیدار میکند
برخی از چالشهای اصلی که در طول کارگاه برجسته شد، مربوط به ادغام علم فیزیکی و هیدرولوژیکی با ML برای کمک به ایجاد اعتماد و قابلیت اطمینان بود. پر کردن شکاف در مشاهدات مناطق غرق شده با مدل ها و داده های ماهواره ای. اندازه گیری مهارت و قابلیت اطمینان سیستم های هشدار سیل؛ و بهبود ارتباطات هشدارهای سیل به جمعیت های مختلف جهانی. علاوه بر این، شرکت کنندگان تاکید کردند که پرداختن به این چالش ها و سایر چالش ها مستلزم همکاری بین تعدادی از سازمان های مختلف و رشته های علمی است.
پروژه کاروان
یکی از چالشهای اصلی در انجام تحقیقات موفق ML و ایجاد ابزارهای پیشرفته برای پیشبینی سیل، نیاز به مقادیر زیادی داده برای آموزش و ارزیابی محاسباتی پرهزینه است. امروزه، بسیاری از کشورها و سازمانها دادههای جریان جریان (معمولاً سطح آب یا نرخ جریان) را جمعآوری میکنند، اما استاندارد نشده یا در یک مخزن مرکزی نگهداری میشوند، که دسترسی محققان را دشوار میکند.
در طول کارگاه آموزشی پیشبینی سیل در سال 2019، گروهی از محققان نیاز به منبع باز، مخزن دادههای جریان جهانی را شناسایی کردند و ایدههایی را در مورد استفاده از منابع محاسباتی رایگان از Google Earth Engine برای رسیدگی به چالش جمعآوری دادهها و جامعه پیشبینی سیل ایجاد کردند. دسترسی. پس از دو سال کار مشترک بین محققان گوگل، دانشکده جغرافیا در دانشگاه اکستر، موسسه یادگیری ماشین در دانشگاه یوهانس کپلر، و موسسه علوم جوی و آب و هوا در ETH زوریخ، پروژه کاروان ایجاد شد.
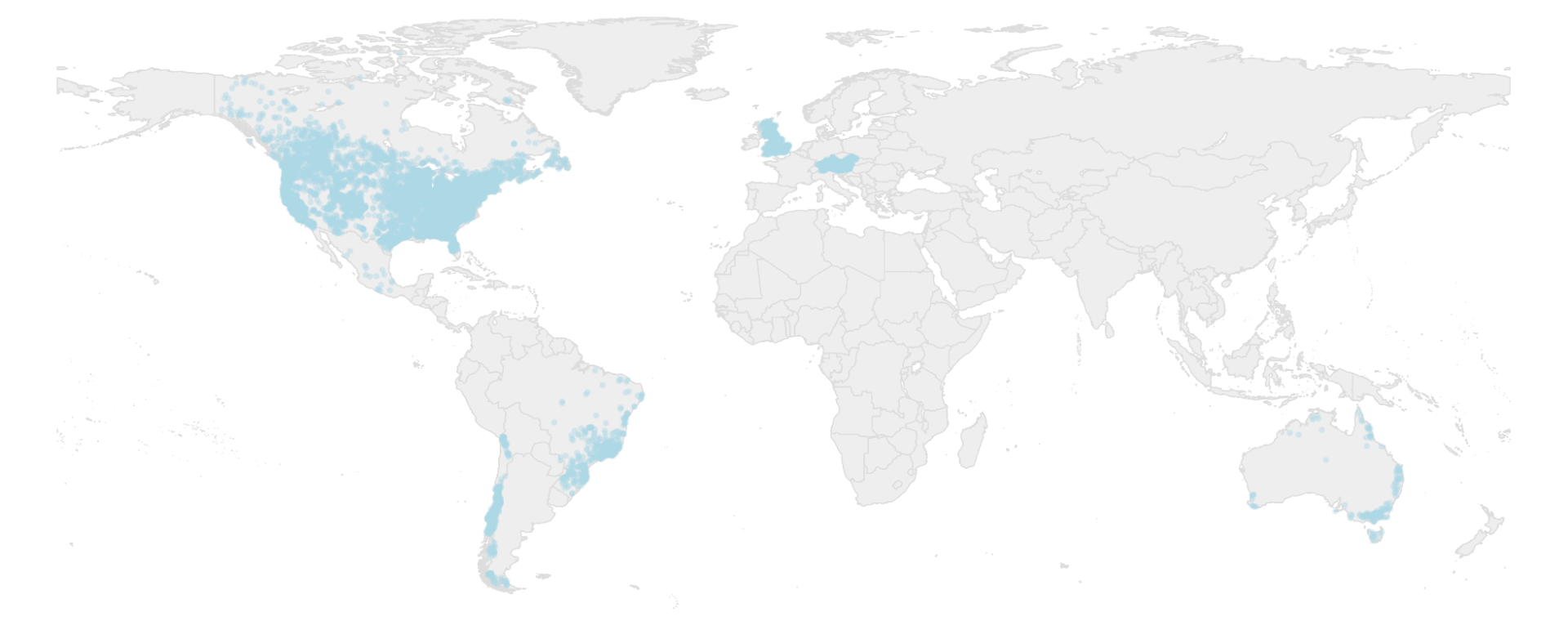
در “کاروان – مجموعه داده های جامعه جهانی برای هیدرولوژی نمونه های بزرگ” منتشر شده در داده های علمی طبیعت، پروژه را با جزئیات بیشتری شرح می دهیم. بر اساس یک مجموعه داده جهانی برای توسعه و آموزش مدلهای هیدرولوژیکی (شکل زیر را ببینید)، کاروان اسکریپتهای منبع باز Python را ارائه میکند که از آب و هوا و دادههای جغرافیایی ضروری استفاده میکند که قبلاً در Google Earth Engine عمومی شده بود تا با دادههای جریان جریانی که کاربران در آن آپلود میکنند مطابقت داشته باشد. مخزن این مخزن در ابتدا حاوی اطلاعات بیش از 13000 حوزه آبخیز در اروپای مرکزی، برزیل، شیلی، استرالیا، ایالات متحده، کانادا و مکزیک بود. علاوه بر این، از مشارکتهای اجتماعی سازمان زمینشناسی دانمارک و گرینلند که شامل دادههای جریان جریان از بیشتر حوزههای آبخیز دانمارک است، بهره برده است. هدف این است که به توسعه و رشد این مخزن ادامه دهیم تا محققان بتوانند به بیشتر داده های جریان جهانی دسترسی داشته باشند. برای اطلاعات بیشتر در مورد مشارکت در مجموعه داده Caravan، به [email protected] مراجعه کنید.
 |
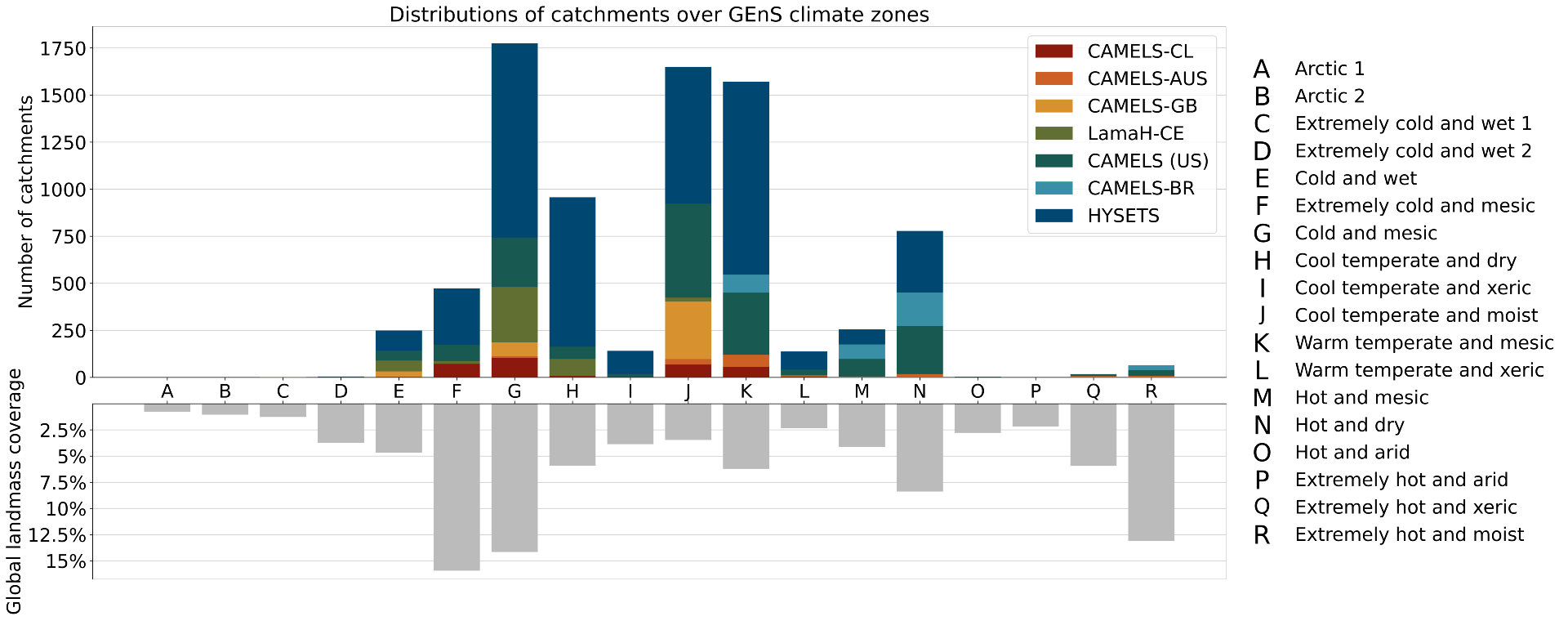 |
| مکان 13000 گیج جریان در مجموعه داده کاروان و توزیع آن سنج ها در مناطق آب و هوایی جهانی GENS. |
مسیر رو به جلو
گوگل قصد دارد به میزبانی این کارگاه ها ادامه دهد تا به گسترش و تعمیق همکاری بین صنعت و دانشگاه در توسعه مدل های هوش مصنوعی محیطی کمک کند. ما مشتاقانه منتظریم تا ببینیم چه پیشرفت هایی ممکن است از کارگاه اخیر حاصل شود. هیدرولوژیست ها و محققان علاقه مند به شرکت در کارگاه های آینده تشویق می شوند با [email protected] تماس بگیرند.