خوشه بندی یک مشکل اصلی در یادگیری ماشینی بدون نظارت (ML) با کاربردهای فراوان در حوزه های مختلف در صنعت و تحقیقات دانشگاهی به طور گسترده تر است. در هسته خود، خوشه بندی شامل مشکل زیر است: با توجه به مجموعه ای از عناصر داده، هدف این است که عناصر داده را به گروه هایی تقسیم کنیم به طوری که اشیاء مشابه در یک گروه قرار گیرند، در حالی که اشیاء غیر مشابه در گروه های مختلف قرار دارند. این مسئله بیش از 60 سال است که در ریاضیات، علوم کامپیوتر، تحقیقات عملیات و آمار در انواع بیشمار آن مورد مطالعه قرار گرفته است. دو شکل متداول خوشهبندی، خوشهبندی متریک است که در آن عناصر، نقاطی در یک فضای متریک هستند، مانند k-به معنی مشکل و خوشه بندی گراف، که در آن عناصر گره های یک گراف هستند که لبه های آن نشان دهنده شباهت بین آنهاست.
 |
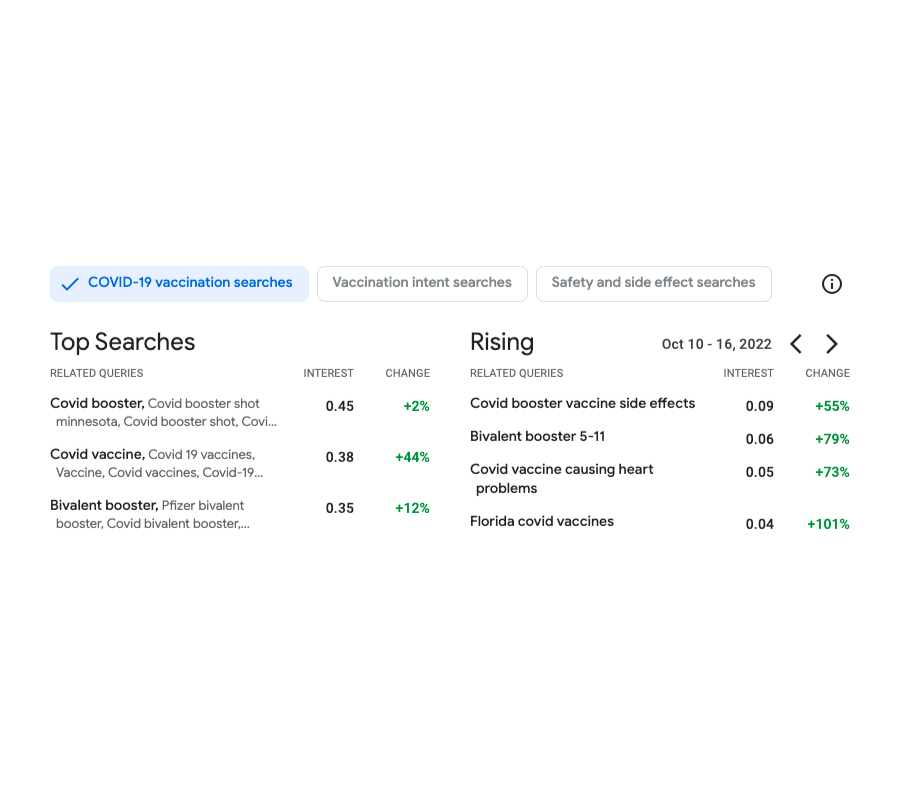
| در k-به معنی مشکل خوشه بندی، مجموعه ای از نقاط در یک فضای متریک با هدف شناسایی به ما داده می شود ک نقاط معرف، مراکز نامیده می شوند (در اینجا به صورت مثلث نشان داده شده اند)، به طوری که مجموع فاصله های مجذور هر نقطه تا نزدیکترین مرکز آن به حداقل برسد. منبع، حقوق: CC-BY-SA-4.0 |
با وجود ادبیات گسترده در مورد طراحی الگوریتم برای خوشهبندی، تعداد کمی از آثار عملی بر محافظت دقیق از حریم خصوصی کاربر در طول خوشهبندی متمرکز شدهاند. هنگامی که خوشهبندی برای دادههای شخصی اعمال میشود (مثلاً پرسشهایی که کاربر انجام داده است)، لازم است پیامدهای حفظ حریم خصوصی استفاده از راهحل خوشهبندی در یک سیستم واقعی و میزان اطلاعاتی که راهحل خروجی در مورد دادههای ورودی نشان میدهد در نظر گرفته شود.
برای اطمینان از حریم خصوصی به معنای دقیق، یک راه حل توسعه الگوریتم های خوشه بندی خصوصی متفاوت (DP) است. این الگوریتمها تضمین میکنند که خروجی خوشهبندی اطلاعات خصوصی در مورد یک عنصر داده خاص (مثلاً اینکه آیا کاربر یک پرس و جو داده است) یا دادههای حساس در مورد نمودار ورودی (مثلاً یک رابطه در یک شبکه اجتماعی) را نشان نمیدهد. با توجه به اهمیت حفاظت از حریم خصوصی در یادگیری ماشینی بدون نظارت، در سالهای اخیر Google روی تحقیق در مورد تئوری و عمل خوشهبندی متریک یا نمودار خصوصی متفاوت و حریم خصوصی متفاوت در زمینههای مختلف، به عنوان مثال، نقشههای حرارتی یا ابزارهایی برای طراحی الگوریتمهای DP سرمایهگذاری کرده است.
امروز ما مشتاق هستیم که دو بهروزرسانی مهم را اعلام کنیم: 1) یک الگوریتم خصوصی متفاوت برای خوشهبندی گراف سلسله مراتبی که در ICML 2023 ارائه خواهیم کرد، و 2) انتشار منبع باز کد یک مقیاس خصوصی متفاوت و مقیاسپذیر. ک-الگوریتم معنی این کد خصوصی متفاوتی را به ارمغان می آورد ک-به معنای خوشه بندی به مجموعه داده های مقیاس بزرگ با استفاده از محاسبات توزیع شده. در اینجا، ما همچنین درباره کار خود در زمینه خوشه بندی فناوری برای راه اندازی اخیر در حوزه سلامت برای اطلاع رسانی به مقامات بهداشت عمومی بحث خواهیم کرد.
خوشه بندی سلسله مراتبی خصوصی متفاوت
خوشهبندی سلسله مراتبی یک رویکرد خوشهبندی محبوب است که شامل تقسیمبندی بازگشتی یک مجموعه داده به خوشهها با دانهبندی فزایندهتر است. یک مثال شناخته شده از خوشه بندی سلسله مراتبی، درخت فیلوژنتیک در زیست شناسی است که در آن تمام حیات روی زمین به گروه های ظریف و ظریف (مانند پادشاهی، شاخه، طبقه، نظم و غیره) تقسیم می شود. یک الگوریتم خوشهبندی سلسله مراتبی نموداری را به عنوان ورودی دریافت میکند که شباهت موجودیتها را نشان میدهد و چنین پارتیشنهای بازگشتی را به روشی بدون نظارت میآموزد. با این حال، در زمان تحقیق ما هیچ الگوریتمی برای محاسبه خوشهبندی سلسله مراتبی یک نمودار با حریم خصوصی لبه، یعنی حفظ حریم خصوصی تعاملات راس، شناخته نشده بود.
در «خوشهبندی سلسله مراتبی خصوصی با ضمانتهای تقریبی قابل اثبات»، ما در نظر میگیریم که چقدر میتوان مشکل را در زمینه DP تقریب زد و مرزهای بالایی و پایینی را در تضمین حریم خصوصی ایجاد کرد. ما یک الگوریتم تقریبی (اولین در نوع خود) با زمان اجرای چند جملهای طراحی میکنیم که هم به یک خطای افزایشی دست مییابد که با تعداد گرهها مقیاس میشود. n (به ترتیب n2.5) و تقریب ضربی O(log½ n)، با خطای ضربی مشابه با تنظیمات غیر خصوصی. ما همچنین یک کران پایینی جدید برای خطای افزودنی (از ترتیب) ارائه می دهیم n2) برای هر الگوریتم خصوصی (صرف نظر از زمان اجرای آن) و یک الگوریتم زمان نمایی ارائه کنید که با این کران پایین مطابقت دارد. علاوه بر این، مقاله ما شامل یک تجزیه و تحلیل فراتر از بدترین حالت است که بر مدل بلوک تصادفی سلسله مراتبی تمرکز دارد، یک مدل نمودار تصادفی استاندارد که ساختار خوشهبندی سلسله مراتبی طبیعی را نشان میدهد و یک الگوریتم خصوصی را معرفی میکند که راهحلی را با هزینه افزایشی بیش از حد مطلوب برمیگرداند. برای نمودارهای بزرگتر و بزرگتر ناچیز است و دوباره با رویکردهای پیشرفته غیرخصوصی مطابقت دارد. ما معتقدیم که این کار درک الگوریتمهای حفظ حریم خصوصی را بر روی دادههای نمودار گسترش میدهد و برنامههای جدید را در چنین تنظیماتی فعال میکند.
خوشه بندی خصوصی متفاوت در مقیاس بزرگ
اکنون دندهها را عوض میکنیم و درباره کار خود برای خوشهبندی فضای متریک بحث میکنیم. اکثر کارهای قبلی در خوشه بندی متریک DP بر بهبود تضمین های تقریبی الگوریتم ها در ک-به معنای هدف، کنار گذاشتن سوالات مقیاس پذیری از تصویر. در واقع، مشخص نیست که الگوریتمهای غیرخصوصی چقدر کارآمد هستند k-به معنی ++ یا k-means// را می توان به طور متفاوت خصوصی کرد بدون اینکه به شدت ضمانت های تقریب یا مقیاس پذیری را قربانی کند. از سوی دیگر، مقیاس پذیری و حریم خصوصی در گوگل از اهمیت اولیه برخوردار هستند. به همین دلیل، اخیراً مقالات متعددی منتشر کردیم که به مشکل طراحی الگوریتمهای خصوصی متفاوت کارآمد برای خوشهبندی میپردازند که میتوانند به مجموعه دادههای عظیم مقیاس شوند. هدف ما، علاوه بر این، ارائه مقیاسپذیری به مجموعه دادههای ورودی در مقیاس بزرگ است، حتی زمانی که تعداد مراکز هدف، ک، بزرگ است.
ما در مدل محاسبات موازی انبوه (MPC) کار می کنیم، که یک مدل محاسباتی نماینده معماری های محاسباتی توزیع شده مدرن است. این مدل از چندین ماشین تشکیل شده است که هر کدام تنها بخشی از داده های ورودی را در خود دارند که با هدف حل یک مشکل جهانی و در عین حال به حداقل رساندن میزان ارتباط بین ماشین ها با هم کار می کنند. ما یک الگوریتم تقریب عامل ثابت خصوصی متفاوت را برای ک-به این معنی است که فقط به تعداد ثابتی از دور همگام سازی نیاز دارد. الگوریتم ما بر اساس کار قبلی ما روی مشکل (با کد موجود در اینجا) استوار است، که اولین الگوریتم خوشهبندی خصوصی متفاوت با تضمینهای تقریبی قابل اثبات بود که میتواند در مدل MPC کار کند.
الگوریتم تقریب عامل ثابت DP با استفاده از یک رویکرد دو فازی به شدت نسبت به کار قبلی بهبود مییابد. در مرحله اولیه، یک تقریب خام را برای “دانه” فاز دوم محاسبه می کند، که از یک الگوریتم توزیع پیچیده تر تشکیل شده است. مجهز به تقریب مرحله اول، فاز دوم بر نتایج حاصل از ادبیات Coreset تکیه دارد تا مجموعه ای از نقاط ورودی مرتبط را نمونه برداری کند و راه حل خوشه بندی خصوصی متفاوت خوبی برای نقاط ورودی پیدا کند. سپس ثابت می کنیم که این راه حل با تضمین تقریباً یکسانی به کل ورودی تعمیم می یابد.
بینش جستجوی واکسیناسیون از طریق خوشه بندی DP
سپس این پیشرفتها را در خوشهبندی خصوصی متفاوت در برنامههای دنیای واقعی اعمال میکنیم. یک مثال، استفاده از راهحل خوشهبندی خصوصی متفاوت ما برای انتشار پرسشهای مرتبط با واکسن کووید است، در حالی که محافظتهای قوی از حریم خصوصی برای کاربران ارائه میکنیم.
هدف Insights جستجوی واکسیناسیون (VSI) کمک به تصمیمگیرندگان بهداشت عمومی (مقامات بهداشتی، سازمانهای دولتی و سازمانهای غیرانتفاعی) برای شناسایی و پاسخگویی به نیازهای اطلاعاتی جوامع در مورد واکسنهای کووید است. برای دستیابی به این هدف، این ابزار به کاربران اجازه می دهد تا در جزئیات موقعیت جغرافیایی مختلف (کد پستی، سطح شهرستان و ایالت در ایالات متحده) مضامین برتر جستجو شده توسط کاربران در مورد جستارهای مربوط به کووید را بررسی کنند. به طور خاص، این ابزار آمار مربوط به جستجوهای پرطرفدار را به تصویر می کشد که در یک مکان و زمان معین علاقه مند می شوند.
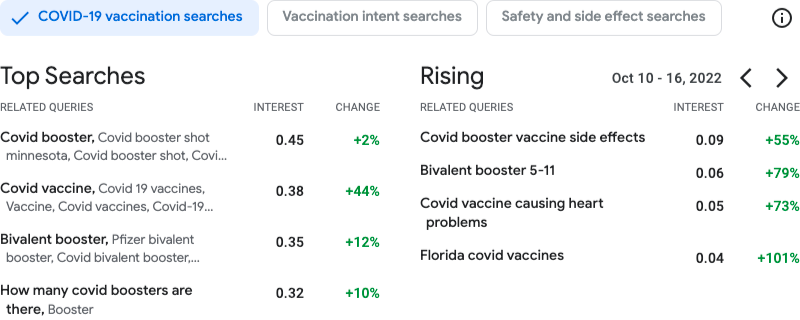 |
| اسکرین شات از خروجی ابزار. در سمت چپ، جستجوهای برتر مربوط به واکسنهای کووید در طول دوره 10-16 اکتبر 2022 نمایش داده میشود. در سمت راست، جستارهایی که در مدت مشابه و در مقایسه با هفته قبل اهمیت فزایندهای داشتهاند. |
برای کمک به شناسایی بهتر مضامین جستجوهای پرطرفدار، این ابزار عبارتهای جستجو را بر اساس شباهت معنایی آنها خوشهبندی میکند. این کار با استفاده از طراحی سفارشی انجام می شود کالگوریتم مبتنی بر میانگین بر روی دادههای جستجو اجرا میشود که با استفاده از مکانیسم DP Gaussian برای اضافه کردن نویز و حذف پرس و جوهای کمشمار ناشناس شدهاند (در نتیجه منجر به خوشهبندی متفاوت میشود). این روش تضمینهای متفاوتی را برای حفظ حریم خصوصی برای محافظت از دادههای کاربر تضمین میکند.
این ابزار دادههای دقیقی را در مورد درک واکسن کووید در جمعیت در مقیاسهای بیسابقهای از دانهبندی ارائه میکند، چیزی که به ویژه برای درک نیازهای جوامع به حاشیه رانده شده که به طور نامتناسبی تحت تأثیر کووید قرار گرفتهاند مرتبط است. این پروژه تأثیر سرمایه گذاری ما در تحقیق در حریم خصوصی متفاوت و روش های ML بدون نظارت را برجسته می کند. ما به دنبال حوزههای مهم دیگری هستیم که میتوانیم این تکنیکهای خوشهبندی را برای کمک به تصمیمگیری در مورد چالشهای بهداشت جهانی، مانند پرسشهای جستجو در مورد چالشهای مرتبط با تغییرات آب و هوا، مانند کیفیت هوا یا گرمای شدید، به کار ببریم.
سپاسگزاریها
از نویسندگان همکار خود سیلویو لاتانزی، وهاب میروکنی، آندرس مونوز مدینا، شیام نارایانان، دیوید ساولپیک، کریس شویگلشون، سرگئی واسیلویتسکی، پیلین ژونگ و همکارانمان از هوش مصنوعی سلامت تیمی که راه اندازی VSI را ممکن کرد، شیلش باوادکار، آدام بولانگر، تاگ گریفیث، مانسی کانسال، چایتانیا کامات، آکیم کوموک، یائل مایر، تومر شیکل، مگان شوم، شارلوت استانتون، میمی سان، سواپنیل ویسپوت و مارک یانگ.
برای اطلاعات بیشتر در مورد تیم Graph Mining (بخشی از الگوریتم و بهینه سازی) از صفحات ما دیدن کنید.