
یادگیری تقویتی (RL) حوزه ای از یادگیری ماشینی است که بر آموزش عوامل هوشمند با استفاده از تجربیات مرتبط تمرکز دارد تا آنها بتوانند وظایف تصمیم گیری مانند بازی های ویدیویی، پرواز بالن های استراتوسفر و طراحی تراشه های سخت افزاری را بیاموزند. با توجه به عمومیت RL، روند رایج در تحقیقات RL، توسعه عواملی است که بتوانند به طور موثر یاد بگیرند. جوانه های چشایی، یعنی از ابتدا بدون استفاده از دانش آموخته شده قبلی در مورد مشکل. با این حال، در عمل، سیستمهای tabula rasa RL معمولا استثنا هستند و نه هنجار برای حل مسائل RL در مقیاس بزرگ. RL در مقیاس بزرگ سیستمهایی مانند OpenAI Five که عملکردی در سطح انسانی در Dota 2 به دست میآورد، در طول چرخه توسعهشان دستخوش تغییرات طراحی متعدد (مثلاً تغییرات الگوریتمی یا معماری) میشوند. این فرآیند اصلاح میتواند ماهها طول بکشد و مستلزم اعمال چنین تغییراتی بدون آموزش مجدد از ابتدا است، که بسیار پرهزینه خواهد بود.
علاوه بر این، ناکارآمدی تحقیق Tabula rasa RL میتواند بسیاری از محققان را از مقابله با مشکلات محاسباتی محروم کند. به عنوان مثال، معیار اساسی آموزش یک عامل RL عمیق بر روی 50+ بازی Atari 2600 در ALE برای 200 میلیون فریم (پروتکل استاندارد) به 1000+ روز GPU نیاز دارد. همانطور که RL عمیق به سمت مسائل پیچیده تر و چالش برانگیزتر حرکت می کند، مانع محاسباتی برای ورود به تحقیقات RL احتمالاً حتی بیشتر خواهد شد.
برای پرداختن به ناکارآمدیهای tabula rasa RL، ما «یادگیری تقویتی در تناسخ مجدد: استفاده مجدد از محاسبات قبلی برای تسریع پیشرفت» را در NeurIPS 2022 ارائه میکنیم. در اینجا، ما یک رویکرد جایگزین برای تحقیقات RL پیشنهاد میکنیم، که در آن کار محاسباتی قبلی، مانند مدلهای آموختهشده، سیاستها، دادههای ثبتشده و غیره، بین تکرارهای طراحی یک عامل RL یا از یک عامل به عامل دیگر استفاده مجدد یا منتقل میشوند. در حالی که برخی از حوزههای فرعی RL از محاسبات قبلی استفاده میکنند، اکثر عوامل RL هنوز تا حد زیادی از ابتدا آموزش دیدهاند. تا کنون، هیچ تلاش گستردهتری برای استفاده از کار محاسباتی قبلی برای گردش کار آموزشی در تحقیقات RL صورت نگرفته است. ما همچنین کد خود را منتشر کردهایم و عواملی را آموزش دادهایم که محققان را قادر میسازد بر روی این کار بسازند.
 |
| Tabula rasa RL در مقابل RL تناسخ (RRL). در حالی که Tabula rasa RL بر یادگیری از ابتدا تمرکز دارد، RRL مبتنی بر فرض استفاده مجدد از کار محاسباتی قبلی (مثلاً عوامل آموخته شده قبلی) هنگام آموزش عوامل جدید یا بهبود عوامل موجود، حتی در همان محیط است. در RRL، عوامل جدید نیازی به آموزش از ابتدا ندارند، به جز برای حملات اولیه به مشکلات جدید. |
چرا Reincarnating RL؟
Reincarnating RL (RRL) یک گردش کار محاسباتی و نمونه کارآمدتر از آموزش از ابتدا است. RRL می تواند تحقیقات را با اجازه دادن به جامعه گسترده تر برای مقابله با مشکلات پیچیده RL بدون نیاز به منابع محاسباتی بیش از حد، دموکراتیک کند. علاوه بر این، RRL می تواند یک الگوی محک زدن را فعال کند که در آن محققان به طور مستمر عوامل آموزش دیده موجود را بهبود می بخشند و به روز می کنند، به ویژه در مورد مشکلاتی که بهبود عملکرد تأثیری در دنیای واقعی دارد، مانند ناوبری بالون یا طراحی تراشه. در نهایت، موارد استفاده از RL در دنیای واقعی احتمالاً در سناریوهایی خواهد بود که کار محاسباتی قبلی در دسترس است (به عنوان مثال، سیاستهای RL مستقر موجود).
 |
| RRL به عنوان یک گردش کار تحقیقاتی جایگزین. محققی را تصور کنید که مامور A را آموزش داده است1 برای مدتی، اما اکنون میخواهد با معماریها یا الگوریتمهای بهتری آزمایش کند. در حالی که گردش کار tabula rasa مستلزم بازآموزی یک عامل دیگر از ابتدا است، RRL گزینه مناسب تر برای انتقال عامل موجود A را ارائه می دهد.1 به یک نماینده دیگر و آموزش بیشتر این نماینده، یا به سادگی تنظیم دقیق A1. |
در حالی که برخی تلاشهای موقتی در مقیاس بزرگ برای تناسخ با کاربرد محدود انجام شده است، به عنوان مثال، جراحی مدل در Dota2، تقطیر سیاست در مکعب روبیک، PBT در AlphaStar، RL تنظیم دقیق یک سیاست شبیهسازی رفتار در AlphaGo / Minecraft، RRL انجام نداده است. به عنوان یک مسئله تحقیقاتی در نوع خود مورد مطالعه قرار گرفته است. برای این منظور، ما برای توسعه رویکردهای RRL همه منظوره در مقابل راهحلهای ad-hoc قبلی استدلال میکنیم.
مطالعه موردی: خطمشی برای ارزشگذاری RL در حال تناسخ
بسته به نوع کار محاسباتی قبلی ارائه شده، می توان مسائل مختلف RRL را مثال زد. بهعنوان گامی در جهت توسعه رویکردهای RRL با کاربرد گسترده، ما یک مطالعه موردی را در مورد تنظیم سیاست به ارزش RL (PVRL) برای انتقال مؤثر یک خطمشی زیربهینه موجود (معلم) به یک عامل مستقل مبتنی بر ارزش RL (دانشآموز) ارائه میکنیم. . در حالی که یک خط مشی مستقیماً یک وضعیت محیطی معین (مثلاً صفحه بازی در آتاری) را به یک اقدام ترسیم می کند، عوامل مبتنی بر ارزش اثربخشی یک اقدام را در یک وضعیت معین از نظر پاداش های قابل دستیابی در آینده تخمین می زنند، که به آنها امکان می دهد از موارد قبلی یاد بگیرند. داده های جمع آوری شده
برای اینکه یک الگوریتم PVRL به طور گسترده مفید باشد، باید شرایط زیر را برآورده کند:
- معلم آگنوستیک: دانش آموز نباید توسط معماری یا الگوریتم آموزشی خط مشی معلم موجود محدود شود.
- از شیر گرفتن معلم: حفظ وابستگی به معلمان نابهینه گذشته برای تناسخ متوالی نامطلوب است.
- محاسبه / نمونه کارآمد: تناسخ تنها زمانی مفید است که از آموزش از ابتدا ارزانتر باشد.
با توجه به الزامات الگوریتم PVRL، ارزیابی می کنیم که آیا رویکردهای موجود، طراحی شده با اهداف نزدیک به هم، کافی هستند یا خیر. ما متوجه شدیم که چنین رویکردهایی یا منجر به پیشرفتهای کوچکی نسبت به Tabula rasa RL میشوند یا در هنگام از شیر گرفتن معلم عملکرد را کاهش میدهند.
برای رفع این محدودیت ها، یک روش ساده را معرفی می کنیم، QDagger، که در آن عامل دانش را از طریق یک الگوریتم تقلید از معلم غیربهینه تقلید می کند در حالی که همزمان از تعاملات محیطی خود برای RL استفاده می کند. ما با یک عامل شبکه Q عمیق (DQN) آموزش دیده برای 400 میلیون فریم محیطی (یک هفته آموزش تک GPU) شروع می کنیم و از آن به عنوان معلم برای تناسخ عوامل دانشجویی که فقط روی 10 میلیون فریم (چند ساعت آموزش) آموزش دیده اند استفاده می کنیم. معلم با 6 میلیون فریم اول از شیر گرفته می شود. برای ارزیابی معیار، متریک میانگین بین ربعی (IQM) را از کتابخانه RLiable گزارش میکنیم. همانطور که در زیر برای تنظیمات PVRL در بازیهای Atari نشان داده شده است، متوجه میشویم که روش QDagger RRL از رویکردهای قبلی بهتر عمل میکند.
 |
| الگوریتمهای PVRL را در آتاری محک میزنید، با نمرات نرمالسازی شده توسط معلم که در 10 بازی جمعآوری شدهاند. Tabula rasa DQN (–·–) نمره نرمال شده 0.4 را به دست می آورد. رویکردهای پایه استاندارد شامل شروع، JSRL، تمرین، پیش تمرین RL آفلاین و DQfD است. در بین همه روشها، تنها QDagger از عملکرد معلم در 10 میلیون فریم پیشی میگیرد و در 75 درصد بازیها از معلم برتری دارد. |
تناسخ RL در عمل
ما بیشتر رویکرد RRL را در محیط یادگیری Arcade، یک معیار RL عمیق که به طور گسترده استفاده می شود، بررسی می کنیم. ابتدا یک عامل Nature DQN را می گیریم که از بهینه ساز RMSProp استفاده می کند و آن را با بهینه ساز Adam تنظیم می کنیم تا یک عامل DQN (Adam) ایجاد کنیم. در حالی که آموزش یک عامل DQN (آدام) از ابتدا امکان پذیر است، ما نشان می دهیم که تنظیم دقیق Nature DQN با بهینه ساز Adam با استفاده از داده و محاسبه 40 برابر کمتر با عملکرد از ابتدا مطابقت دارد.
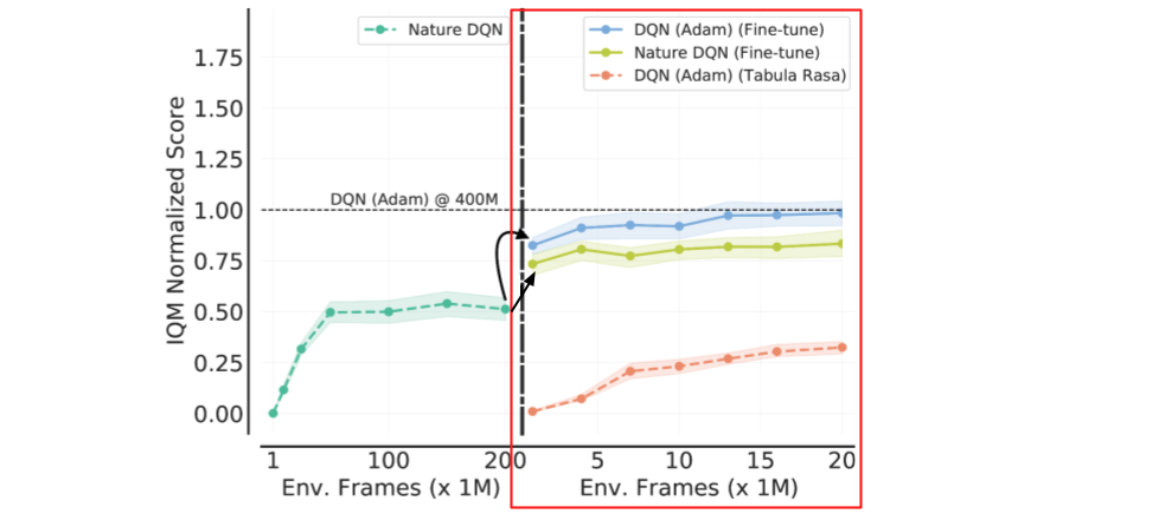 |
| تناسخ DQN (آدام) از طریق Fine-Tuning. جداکننده عمودی مربوط به بارگذاری وزن شبکه و پخش مجدد داده ها برای تنظیم دقیق است. ترک کرد: Tabula rasa Nature DQN تقریباً بعد از 200 میلیون فریم محیطی از نظر عملکرد همگرا می شود. درست: تنظیم دقیق این عامل Nature DQN با استفاده از نرخ یادگیری کاهش یافته با بهینه ساز Adam برای 20 میلیون فریم، نتایج مشابه DQN (آدام) را که از ابتدا برای 400 میلیون فریم آموزش داده شده است، به دست می آورد. |
با توجه به عامل DQN (آدام) به عنوان نقطه شروع، تنظیم دقیق به معماری کانولوشنال 3 لایه محدود می شود. بنابراین، ما یک رویکرد تناسخ عمومیتر را در نظر میگیریم که از پیشرفتهای معماری و الگوریتمی اخیر بدون آموزش از ابتدا استفاده میکند. به طور خاص، ما از QDagger برای تناسخ یک عامل RL دیگر استفاده میکنیم که از یک الگوریتم پیشرفتهتر RL (Rainbow) و یک معماری شبکه عصبی بهتر (Impala-CNN ResNet) از عامل DQN (آدام) بهخوبی تنظیم شده استفاده میکند.
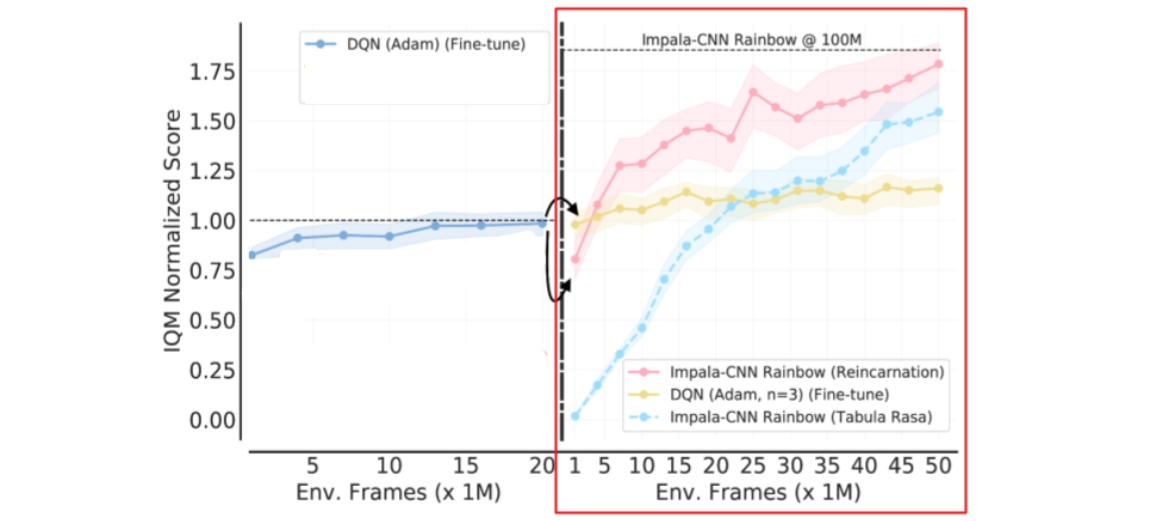 |
| تناسخ مجدد معماری / الگوریتم متفاوت از طریق QDagger. جداکننده عمودی نقطهای است که در آن پیشآموزش آفلاین را با استفاده از QDagger برای تناسخ اعمال میکنیم. ترک کرد: تنظیم دقیق DQN با Adam. درست: مقایسه یک عامل Tabula rasa Impala-CNN Rainbow (آبی آسمان) با یک عامل Impala-CNN Rainbow (صورتی) آموزش دیده با استفاده از QDagger RRL از DQN (آدام) با تنظیم دقیق. عامل Reincarnated Impala-CNN Rainbow به طور مداوم از همتای خراشیده خود بهتر عمل می کند. توجه داشته باشید که تنظیم دقیق DQN (آدام) منجر به کاهش بازده (زرد) می شود. |
به طور کلی، این نتایج نشان میدهد که تحقیقات گذشته میتوانست با استفاده از رویکرد RRL برای طراحی عوامل، به جای آموزش مجدد عوامل از ابتدا، تسریع شود. مقاله ما همچنین حاوی نتایجی در مورد محیط یادگیری بالون است، جایی که نشان میدهیم که RRL به ما اجازه میدهد تا با استفاده مجدد از یک عامل RL توزیعشده که بر روی TPUها برای بیش از یک زمان آموزش دیده است، در مسئله ناوبری بالنهای استراتوسفری تنها با استفاده از چند ساعت محاسبه TPU پیشرفت کنیم. ماه
بحث
مقایسه نسبتاً رویکردهای تناسخ مستلزم استفاده از همان کار محاسباتی و گردش کار است. علاوه بر این، یافتههای تحقیق در RRL که به طور کلی تعمیم میدهند، در مورد اینکه چگونه یک الگوریتم به کار محاسباتی موجود دسترسی دارد مؤثر است، به عنوان مثال، ما با موفقیت QDagger را با استفاده از Atari برای تناسخ در محیط یادگیری بالن استفاده کردیم. به این ترتیب، ما حدس می زنیم که تحقیقات در تناسخ RL می تواند در دو جهت منشعب شود:
- معیارهای استاندارد شده با کار محاسباتی منبع باز: مشابه NLP و چشم انداز، جایی که معمولاً مجموعه کوچکی از مدل های از پیش آموزش دیده رایج است، تحقیقات در RRL ممکن است به مجموعه کوچکی از کار محاسباتی منبع باز (مثلاً خط مشی های معلم از قبل آموزش دیده) بر روی یک معیار معین همگرا شود.
- دامنه های دنیای واقعی: از آنجایی که به دست آوردن عملکرد بالاتر در برخی از حوزه ها تأثیر واقعی دارد، جامعه را به استفاده مجدد از عوامل پیشرفته و تلاش برای بهبود عملکرد آنها تشویق می کند.
مقاله ما را برای بحث گسترده تر در مورد مقایسه های علمی، تعمیم پذیری و تکرارپذیری در RRL ببینید. به طور کلی، ما امیدواریم که این کار محققان را به انتشار کارهای محاسباتی (مثلاً نقاط بازرسی مدل) برانگیزد که دیگران بتوانند مستقیماً روی آن بسازند. در این راستا، ما کدهای خود و عوامل آموزش دیده را با بافرهای پخش نهایی آنها منبع باز کرده ایم. ما بر این باوریم که تناسخ RL می تواند به طور قابل توجهی پیشرفت تحقیقات را با ایجاد کار محاسباتی قبلی تسریع بخشد، برخلاف همیشه که از ابتدا شروع کنیم.
سپاسگزاریها
این کار با همکاری پابلو ساموئل کاسترو، آرون کورویل و مارک بلمار انجام شده است. مایلیم از تام اسمال برای فیگور متحرک استفاده شده در این پست تشکر کنیم. همچنین از بازخورد بازبینان ناشناس NeurIPS و چندین عضو تیم تحقیقاتی Google، DeepMind و Mila سپاسگزاریم.