در چند دهه گذشته شاهد توسعه سریع فناوری تشخیص کاراکتر نوری (OCR) بودهایم که از یک کار معیار آکادمیک مورد استفاده در پیشرفتهای اولیه تحقیقات یادگیری عمیق به محصولات ملموس موجود در دستگاههای مصرفکننده و توسعهدهندگان شخص ثالث برای استفاده روزانه تکامل یافته است. این محصولات OCR اطلاعات ارزشمندی را که در منابع کاغذی یا مبتنی بر تصویر (مانند کتاب، مجلات، روزنامهها، فرمها، علائم خیابانها، منوی رستورانها) ذخیره میشوند دیجیتالی و دموکراتیک میکنند تا بتوان آنها را فهرستبندی، جستجو، ترجمه و پردازش بیشتر کرد. با تکنیک های پیشرفته پردازش زبان طبیعی.
تحقیقات در تشخیص و تشخیص متن صحنه (یا تشخیص متن صحنه) محرک اصلی این توسعه سریع از طریق تطبیق OCR با تصاویر طبیعی بوده است که پسزمینه پیچیدهتری نسبت به تصاویر سند دارند. با این حال، این تلاشهای تحقیقاتی بر تشخیص و تشخیص هر کلمه در تصاویر متمرکز است، بدون اینکه بفهمند این کلمات چگونه جملات و مقالات را تشکیل میدهند.
تجزیه و تحلیل طرح بندی یکی دیگر از رشته های تحقیق مرتبط است که یک تصویر سند را می گیرد و ساختار آن را استخراج می کند، یعنی عنوان، پاراگراف ها، عنوان ها، شکل ها، جداول و عنوان ها. این تلاشهای تحلیل طرحبندی موازی با OCR هستند و تا حد زیادی به عنوان تکنیکهای مستقلی توسعه یافتهاند که معمولاً فقط بر روی تصاویر سند ارزیابی میشوند. به این ترتیب، هم افزایی بین OCR و تحلیل چیدمان تا حد زیادی مورد بررسی قرار نگرفته است. ما معتقدیم که OCR و تجزیه و تحلیل طرحبندی وظایف مکمل یکدیگر هستند که یادگیری ماشین را قادر میسازد تا متن را در تصاویر تفسیر کند و در صورت ترکیب، دقت و کارایی هر دو کار را بهبود بخشد.
با در نظر گرفتن این موضوع، ما اعلام می کنیم مسابقه تشخیص و تشخیص متن سلسله مراتبی (چالش HierText)، به عنوان بخشی از هفدهمین کنفرانس بین المللی سالانه تجزیه و تحلیل و شناسایی اسناد (ICDAR 2023) میزبانی شد. این مسابقه در وب سایت مسابقه خواندن قوی میزبانی می شود و نشان دهنده اولین تلاش عمده برای یکسان سازی OCR و تجزیه و تحلیل طرح است. در این مسابقه، از محققان سراسر جهان دعوت میکنیم تا سیستمهایی بسازند که بتوانند حاشیهنویسی سلسله مراتبی متن را در تصاویر با استفاده از کلمات خوشهبندی شده در خطوط و پاراگرافها تولید کنند. ما امیدواریم که این رقابت با هدف تجمیع تلاشهای تحقیقاتی در OCR و تجزیه و تحلیل طرحبندی، و ایجاد سیگنالهای جدید برای وظایف پردازش اطلاعات پاییندست، تأثیر مهم و بلندمدتی بر درک متن مبتنی بر تصویر داشته باشد.
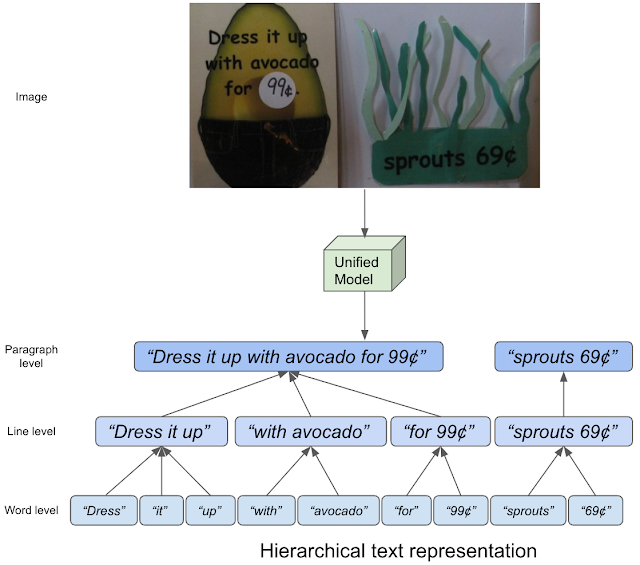 |
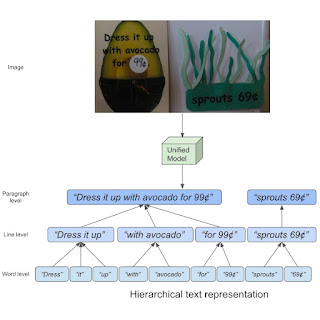
| مفهوم نمایش سلسله مراتبی متن. |
ساخت یک مجموعه داده متنی سلسله مراتبی
در این رقابت، ما از مجموعه داده HierText استفاده میکنیم که در CVPR 2022 با مقاله خود «به سوی تشخیص و تحلیل طرحبندی متن یکپارچه صحنه از انتها به انتها» منتشر کردیم. این اولین مجموعه داده تصویر واقعی است که حاشیه نویسی سلسله مراتبی از متن را ارائه می دهد کلمه، خط، و پاراگراف حاشیه نویسی سطح اینجا، “کلمات“به عنوان دنباله ای از کاراکترهای متنی تعریف می شوند که توسط آنها قطع نمی شوند فضاها. “خطوط“سپس به این صورت تعبیر می شوند”فضا“-خوشه های جدا شده از”کلمات“که به طور منطقی در یک جهت به هم متصل هستند و در مجاورت فضایی تراز می شوند. در نهایت، “پاراگراف ها“متشکل از”خطوط” که موضوع معنایی یکسانی دارند و از نظر هندسی منسجم هستند.
برای ساخت این مجموعه داده، ابتدا تصاویر را از مجموعه داده های Open Images با استفاده از Google Cloud Platform (GCP) Text Detection API حاشیه نویسی کردیم. ما از میان این تصاویر حاشیه نویسی فیلتر کردیم و فقط تصاویر را غنی از محتوای متن و ساختار طرحبندی نگه داشتیم. سپس، ما با شرکای شخص ثالث خود برای تصحیح دستی همه رونویسیها و برچسبگذاری کلمات، خطوط و ترکیب پاراگراف کار کردیم. در نتیجه، 11639 تصویر رونویسی شده به دست آوردیم که به سه زیر مجموعه تقسیم شدند: (1) یک مجموعه قطار با 8281 تصویر، (2) یک مجموعه اعتبارسنجی با 1724 تصویر و (3) یک مجموعه آزمایشی با 1634 تصویر. همانطور که در مقاله توضیح داده شد، ما همپوشانی بین مجموعه داده خود، TextOCR، و Intel OCR را نیز بررسی کردیم (هر دو نیز تصاویر حاشیه نویسی را از Open Images استخراج میکردند)، مطمئن شدیم که تصاویر آزمایشی در مجموعه داده HierText نیز در TextOCR گنجانده نشدهاند. یا اینتل آموزش OCR و تقسیم اعتبار و بالعکس. در زیر، نمونه هایی را با استفاده از مجموعه داده HierText تجسم می کنیم و مفهوم متن سلسله مراتبی را با سایه انداختن هر موجودیت متن با رنگ های مختلف نشان می دهیم. می بینیم که HierText دارای تنوع دامنه تصویر، طرح متن و تراکم متن بالا است.
 |
| نمونه هایی از مجموعه داده HierText. ترک کرد: تصویر هر یک از موجودیت کلمه. میانه: تصویر خوشه بندی خطوط. درست: خوشه بندی پاراگراف تصویری. |
مجموعه داده با بالاترین چگالی متن
علاوه بر نمایش سلسله مراتبی جدید، HierText دامنه جدیدی از تصاویر متنی را نشان می دهد. توجه داریم که HierText در حال حاضر متراکم ترین مجموعه داده OCR است که در دسترس عموم است. در زیر ویژگی های HierText را در مقایسه با سایر مجموعه داده های OCR خلاصه می کنیم. HierText به طور متوسط 103.8 کلمه در هر تصویر را شناسایی می کند که بیش از 3 برابر تراکم TextOCR و 25 برابر چگالی تر از ICDAR-2015 است. این چگالی بالا چالشهای منحصر به فردی را برای شناسایی و شناسایی ایجاد میکند و در نتیجه HierText به عنوان یکی از مجموعههای داده اولیه برای تحقیقات OCR در Google استفاده میشود.
| مجموعه داده | تقسیم آموزشی | تقسیم اعتبار | تقسیم آزمایشی | کلمات در هر تصویر | ||||||||||
| ICDAR-2015 | 1000 | 0 | 500 | 4.4 | ||||||||||
| TextOCR | 21778 | 3,124 | 3,232 | 32.1 | ||||||||||
| اینتل OCR | 19,1059 | 16731 | 0 | 10.0 | ||||||||||
| HierText | 8281 | 1,724 | 1634 | 103.8 |
| مقایسه چندین مجموعه داده OCR با مجموعه داده HierText. |
توزیع فضایی
همچنین متوجه شدیم که متن در مجموعه داده HierText نسبت به سایر مجموعههای داده OCR، از جمله TextOCR، Intel OCR، IC19 MLT، COCO-Text و IC19 LSVT، توزیع فضایی یکنواختتری دارد. این مجموعه دادههای قبلی معمولاً تصاویری با ترکیب خوب دارند، جایی که متن در وسط تصاویر قرار میگیرد و بنابراین شناسایی آسانتر است. برعکس، موجودیت های متن در HierText به طور گسترده در بین تصاویر توزیع شده اند. این گواه بر این است که تصاویر ما از حوزه های متنوع تری هستند. این ویژگی HierText را به طور منحصر به فردی در میان مجموعه داده های OCR عمومی چالش برانگیز می کند.
 |
| توزیع فضایی نمونه های متنی در مجموعه داده های مختلف. |
چالش HierText
چالش HierText نشان دهنده یک کار جدید و با چالش های منحصر به فرد برای مدل های OCR است. ما از محققان دعوت می کنیم تا در این چالش شرکت کنند و امسال در ICDAR 2023 در سن خوزه، کالیفرنیا به ما بپیوندند. ما امیدواریم که این رقابت باعث جلب توجه جامعه تحقیقاتی به مدلهای OCR با بازنمایی اطلاعات غنی شود که برای کارهای جدید پاییندستی مفید هستند.
سپاسگزاریها
مشارکت کنندگان اصلی این پروژه عبارتند از: Shangbang Long، Siyang Qin، Dmitry Panteleev، Alessandro Bissacco، Yasuhisa Fujii و Michalis Raptis. آشوک پوپات و جیک واکر توصیه های ارزشمندی ارائه کردند. همچنین از دیموستنیس کاراتزاس و سرگی روبلز از دانشگاه خودمختار بارسلون برای کمک به ما در راه اندازی وب سایت مسابقه تشکر می کنیم.