شبکههای عصبی کانولوشنال از زمان معرفی AlexNet در سال 2012، معماری یادگیری ماشین غالب برای بینایی کامپیوتر بودهاند. اخیراً، با الهام از تکامل ترانسفورماتورها در پردازش زبان طبیعی، مکانیسمهای توجه به طور برجسته در مدلهای بینایی گنجانده شدهاند. این روشهای توجه، برخی از بخشهای داده ورودی را تقویت میکنند در حالی که بخشهای دیگر را به حداقل میرسانند تا شبکه بتواند بر بخشهای کوچک اما مهم داده تمرکز کند. Vision Transformer (ViT) چشم انداز جدیدی از طرح های مدل برای بینایی کامپیوتر ایجاد کرده است که کاملاً عاری از پیچش است. ViT وصله های تصویر را به عنوان دنباله ای از کلمات در نظر می گیرد و یک رمزگذار Transformer را در بالا اعمال می کند. زمانی که ViT روی مجموعه داده های به اندازه کافی بزرگ آموزش داده می شود، عملکرد قانع کننده ای را در تشخیص تصویر نشان می دهد.
در حالی که پیچیدگی و توجه هر دو برای عملکرد خوب کافی هستند، هیچ یک از آنها ضروری نیستند. به عنوان مثال، MLP-Mixer یک پرسپترون چند لایه ساده (MLP) را برای ترکیب وصلههای تصویر در تمام مکانهای فضایی استفاده میکند، که منجر به یک معماری تمام MLP میشود. این یک جایگزین رقابتی برای مدلهای بینایی پیشرفته از نظر مبادله بین دقت و محاسبات مورد نیاز برای آموزش و استنتاج است. با این حال، هر دو مدل ViT و MLP برای مقیاس بندی به وضوح ورودی بالاتر تلاش می کنند زیرا پیچیدگی محاسباتی با توجه به اندازه تصویر به طور درجه دوم افزایش می یابد.
امروز یک رویکرد چند محوری جدید ارائه میکنیم که ساده و مؤثر است، مدلهای ViT و MLP اصلی را بهبود میبخشد، میتواند بهتر با وظایف پیشبینی با وضوح بالا و متراکم سازگار شود و به طور طبیعی میتواند با اندازههای ورودی مختلف با انعطافپذیری بالا و پیچیدگی کم سازگار شود. . بر اساس این رویکرد، ما دو مدل ستون فقرات برای وظایف بینایی سطح بالا و سطح پایین ساختهایم. ما اولین مورد را در “MaxViT: Multi-Axis Vision Transformer” که در ECCV 2022 ارائه می شود، توصیف می کنیم و نشان می دهیم که به طور قابل توجهی وضعیت هنر را برای کارهای سطح بالا، مانند طبقه بندی تصویر، تشخیص اشیا، تقسیم بندی، ارزیابی کیفیت بهبود می بخشد. ، و نسل. دومی که در “MAXIM: Multi-Axis MLP for Image Processing” در CVPR 2022 ارائه شده است، مبتنی بر معماری UNet-مانند است و عملکرد رقابتی را در کارهای تصویربرداری سطح پایین از جمله حذف نویز، محو کردن، مه زدایی، خارج کردن هوا، و کم نور به دست می آورد. افزایش نور برای تسهیل تحقیقات بیشتر در مورد مدلهای ترانسفورماتور و MLP کارآمد، کد و مدلها را برای MaxViT و MAXIM منبع باز کردهایم.
 |
| نمایشی از رفع تاری تصویر با استفاده از فریم به فریم MAXIM. |
بررسی اجمالی
رویکرد جدید ما مبتنی بر توجه چند محوری است، که توجه تمام اندازه (هر پیکسل به تمام پیکسلها توجه میکند) مورد استفاده در ViT را به دو شکل پراکنده – محلی و (پراکنده) جهانی تجزیه میکند. همانطور که در شکل زیر نشان داده شده است، توجه چند محوری شامل یک پشته متوالی از توجه بلوک و توجه شبکه است. توجه بلوک در پنجرههای غیر همپوشانی (تکههای کوچک در نقشههای ویژگی میانی) برای ثبت الگوهای محلی کار میکند، در حالی که توجه شبکه روی یک شبکه یکنواخت پراکنده برای تعاملات دوربرد (جهانی) کار میکند. اندازه پنجره توجهات شبکه و بلوک را می توان به طور کامل به عنوان فراپارامترها کنترل کرد تا از پیچیدگی محاسباتی خطی به اندازه ورودی اطمینان حاصل شود.
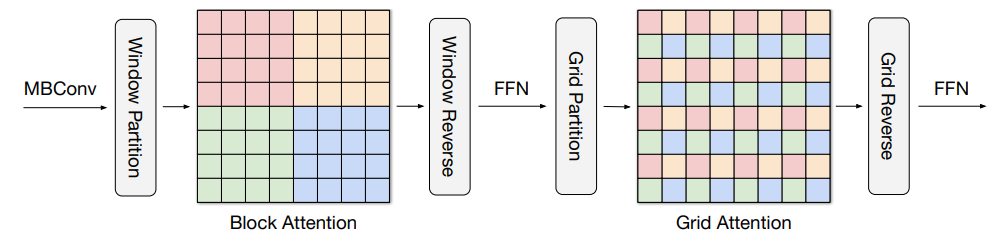 |
| توجه چند محوری پیشنهادی، توجه جهانی مسدود شده و گشاد شده را بهطور متوالی به دنبال یک FFN، تنها با پیچیدگی خطی، هدایت میکند. پیکسل ها در رنگ های مشابه با هم حضور دارند. |
چنین توجه کم پیچیدگی می تواند به طور قابل توجهی کاربرد گسترده خود را برای بسیاری از وظایف بینایی، به ویژه برای پیش بینی های بصری با وضوح بالا، بهبود بخشد، و عمومیت بیشتری را نسبت به توجه اصلی مورد استفاده در ViT نشان می دهد. ما دو نمونه اصلی از این رویکرد توجه چند محوره می سازیم – MaxViT و MAXIM، به ترتیب برای کارهای سطح بالا و سطح پایین.
MaxViT
در MaxViT، ابتدا یک بلوک MaxViT منفرد (نشان داده شده در زیر) با الحاق MBConv (پیشنهاد شده توسط EfficientNet، V2) با توجه چند محوره ایجاد می کنیم. این بلوک واحد می تواند اطلاعات بصری محلی و جهانی را بدون توجه به وضوح ورودی رمزگذاری کند. سپس به سادگی بلوکهای مکرر متشکل از توجه و پیچیدگیها را در یک معماری سلسله مراتبی (شبیه به ResNet، CoAtNet) روی هم قرار میدهیم و معماری MaxViT ما را بهدست میآوریم. نکته قابل توجه، MaxViT از رویکردهای سلسله مراتبی قبلی متمایز است زیرا می تواند در سراسر شبکه، حتی در مراحل اولیه با وضوح بالا، “دیدن” را در سراسر شبکه ببیند و ظرفیت مدل قوی تری را در وظایف مختلف نشان دهد.
 |
| متا معماری MaxViT. |
حداکثر
ستون فقرات دوم ما، MAXIM، یک معماری UNet-مانند عمومی است که برای کارهای سطح پایین پیشبینی تصویر به تصویر طراحی شده است. MAXIM طرحهای موازی رویکردهای محلی و جهانی را با استفاده از شبکه پرسپترون چند لایه دروازهای (gMLP) بررسی میکند (MLP وصله-اختلاط با مکانیزم دروازه). یکی دیگر از مشارکت های MAXIM بلوک متقاطع است که می تواند برای اعمال تعامل بین دو سیگنال ورودی مختلف استفاده شود. این بلوک می تواند به عنوان یک جایگزین کارآمد برای ماژول توجه متقابل عمل کند، زیرا فقط از اپراتورهای ارزان قیمت MLP دروازه ای برای تعامل با ورودی های مختلف بدون تکیه بر توجه متقابل سنگین محاسباتی استفاده می کند. علاوه بر این، تمام اجزای پیشنهادی از جمله MLP دروازهدار و بلوکهای دروازهای متقاطع در MAXIM از پیچیدگی خطی نسبت به اندازه تصویر برخوردار هستند و در هنگام پردازش تصاویر با وضوح بالا کارآمدتر میشوند.
نتایج
ما اثربخشی MaxViT را در طیف وسیعی از وظایف بینایی نشان میدهیم. در طبقهبندی تصاویر، MaxViT به نتایج پیشرفتهای در تنظیمات مختلف دست مییابد: تنها با آموزش ImageNet-1K، MaxViT به 86.5% دقت بالای 1 دست مییابد. با ImageNet-21K (14M تصویر، 21k کلاس)، MaxViT به دقت 88.7% top-1 دست می یابد. و با پیشآموزش JFT (300 میلیون تصویر، 18 هزار کلاس)، بزرگترین مدل MaxViT-XL ما به دقت بالای 89.5٪ با پارامترهای 475M دست مییابد.
 |
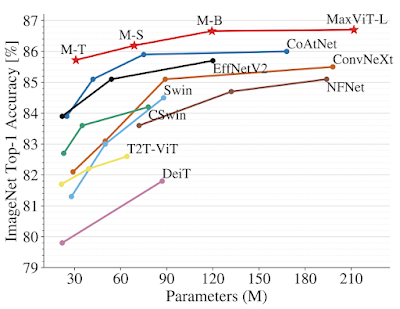 |
| مقایسه عملکرد MaxViT با مدل های پیشرفته در ImageNet-1K. بالا: دقت در مقابل مقیاس عملکرد FLOPs با وضوح تصویر 224×224. پایین: منحنی مقیاس بندی دقت در مقابل پارامترها تحت تنظیمات تنظیم دقیق ImageNet-1K. |
برای وظایف پایین دست، MaxViT به عنوان ستون فقرات عملکرد مطلوبی را در طیف گسترده ای از وظایف ارائه می دهد. برای تشخیص اشیاء و تقسیمبندی در مجموعه داده COCO، ستون فقرات MaxViT به 53.4 AP دست مییابد که از سایر مدلهای سطح پایه بهتر عمل میکند در حالی که تنها به حدود 60 درصد هزینه محاسباتی نیاز دارد. برای ارزیابی زیبایی شناسی تصویر، مدل MaxViT مدل پیشرفته MUSIQ را تا 3.5 درصد از نظر همبستگی خطی با نمرات نظر انسان ارتقا می دهد. بلوک سازنده مستقل MaxViT همچنین عملکرد مؤثری را در تولید تصویر نشان میدهد و امتیازات FID و IS بهتری را در کار تولید بدون قید و شرط ImageNet-1K با تعداد پارامترهای بسیار کمتری نسبت به مدل پیشرفته HiT به دست میآورد.
ستون فقرات MAXIM مانند UNet، که برای کارهای پردازش تصویر سفارشی شده است، همچنین نتایج پیشرفتهای را در 15 از 20 مجموعه داده آزمایش شده، از جمله حذف نویز، محو کردن، تخلیه، مهزدایی، و بهبود در نور کم نشان داده است، در حالی که به موارد کمتری نیاز دارد. یا تعداد پارامترها و FLOPهای قابل مقایسه نسبت به مدلهای رقابتی. تصاویر بازیابی شده توسط MAXIM جزئیات بازیابی شده بیشتری را با مصنوعات بصری کمتر نشان می دهند.
 |
| نتایج بصری MAXIM برای از بین بردن تاری تصویر، خروج از خط و بهبود در نور کم. |
خلاصه
کارهای اخیر در دو یا چند سال اخیر نشان داده است که ConvNets و Vision Transformers می توانند عملکرد مشابهی داشته باشند. کار ما طراحی یکپارچه ای را ارائه می دهد که از بهترین های هر دو جهان بهره می برد – پیچیدگی کارآمد و توجه کم – و نشان می دهد که یک مدل ساخته شده در بالا، یعنی MaxViT، می تواند عملکردی پیشرفته در انواع وظایف بینایی داشته باشد. . مهمتر از آن، MaxViT به خوبی به اندازه داده های بسیار بزرگ مقیاس می شود. ما همچنین نشان میدهیم که یک طراحی چند محوری جایگزین با استفاده از عملگرهای MLP، MAXIM، به عملکرد پیشرفتهای در طیف وسیعی از وظایف بینایی سطح پایین دست مییابد.
حتی اگر ما مدلهای خود را در زمینه وظایف بینایی ارائه میکنیم، رویکرد چند محوری پیشنهادی میتواند به راحتی به مدلسازی زبان گسترش یابد تا وابستگیهای محلی و جهانی را در زمان خطی به تصویر بکشد. با انگیزه کار در اینجا، ما انتظار داریم که ارزش بررسی سایر اشکال توجه پراکنده در سیگنالهای با ابعاد بالاتر یا چندوجهی مانند ویدئوها، ابرهای نقطهای و مدلهای زبان بینایی را داشته باشد.
ما کدها و مدلهای MAXIM و MaxViT را منبع باز کردهایم تا تحقیقات آینده در مورد توجه کارآمد و مدلهای MLP را تسهیل کنیم.
قدردانی ها
مایلیم از نویسندگان همکارمان: حسین طالبی، هان ژانگ، فنگ یانگ، پیمان میلانفر و آلن بوویک تشکر کنیم. همچنین مایلیم از بحث و حمایت ارزشمند Xianzhi Du، Long Zhao، Wuyang Chen، Hanxiao Liu، قدردانی کنیم. زیهانگ دای، انوراگ آرناب، سونگ جوون چوی، جونجی که، مائوریسیو دلبراسیو، ایرنه ژو، اینفارن یو، هویون چانگ و سی لیو.