
@jstephanژان ایو “JY” استفان
JY مدیرعامل و بنیانگذار مکانیک داده است. پیش از این او در Databricks پیشگام تیم Spark infra تیم بود
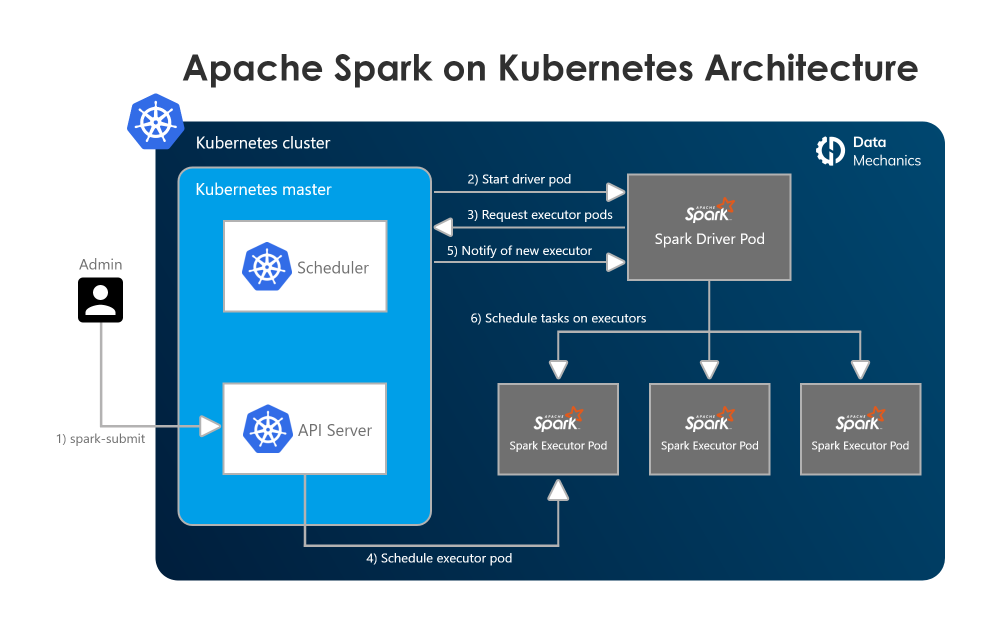
در اوایل سال جاری در اجلاس Spark + AI ، ما از ارائه جلسه خود در مورد بهترین اقدامات و مشکلات اجرای Apache Spark در Kubernetes (K8s) لذت بردیم.
در این پست می خواهیم آن ارائه را گسترش دهیم و در مورد شما صحبت کنیم:
- کوبرنتس چیست؟
- چرا Spark را روی Kubernetes اجرا کنیم؟
- شروع کار با Spark on Kubernetes
- بهینه سازی عملکرد و هزینه
- نظارت بر برنامه های Spark شما در Kubernetes
- آینده Spark on Kubernetes
اگر قبلاً با k8s آشنایی دارید و چرا Spark on Kubernetes برای شما مناسب است ، در صورت تمایل از بخشهای اول استفاده نکنید و مستقیماً وارد گوشت پست شوید!
Kubernetes (k8s) چیست؟
Kubernetes (همچنین با نام Kube یا k8s شناخته می شود) یک سیستم ارکستراسیون کانتینر منبع باز است که در ابتدا در گوگل توسعه یافته است و منبع آن در سال 2014 تهیه شده و توسط بنیاد رایانش ابری Cloud نگهداری می شود. Kubernetes برای خودکار سازی ، مقیاس گذاری و مدیریت برنامه های محتوی استفاده می شود – معمولاً محفظه های Docker.
این ویژگی بسیاری از ویژگی های مهم برای ثبات ، امنیت ، عملکرد و مقیاس پذیری را ارائه می دهد ، مانند:
- مقیاس پذیری افقی
- جمع آوری خودکار و بازگشت
- تعادل بار
- اسرار و مدیریت پیکربندی
- …و بسیاری از…