غیرقابل تصور رایج شد: قطع شدن ابر. قطع ابر به این معنی است که خدمات ضروری مانند ذخیره سازی، ظرفیت محاسباتی یا میان افزار در یک مرکز داده ابری یا کل منطقه در دسترس نیستند. امروزه با برنامههای کاربردی و کاربردی در فضای ابری، چنین قطعهایی بیش از صفحات وب و فروشگاههای آنلاین که با مشتری روبرو هستند، تأثیر میگذارند. همه برنامهها از دسترس خارج میشوند و کل شرکت متوقف میشود. کارمندان نمی توانند کار کنند، چه در امور مالی، منابع انسانی، فروش، تولید، خدمات مشتری یا تدارکات.
بعلاوه، قطع برق نه تنها ممکن است موقتی باشد. در صورت سوختن یک مرکز داده، سرورها و تمام داده های آنها برای همیشه از بین می روند. بنابراین، CIOها، CISOها و هیئت مدیره باید تصمیم بگیرند که کدام خطرات را بپذیرند و در برنامه ریزی تداوم کسب و کار و بازیابی فاجعه به کدام یک رسیدگی کنند.
مدیریت تداوم کسبوکار سنتی (BCM) چالشهای موجود در حوزه فیزیکی را پوشش میدهد: عدم حضور اکثریت نیروی کار (بهعنوان مثال به دلیل یک بیماری همهگیر) یا سیل و آتشسوزی که ساختمانهای اداری و مراکز داده را ویران میکند. قطع شدن فضای ابری یک سناریوی جدید است – و رسیدگی به آنها مستلزم درک عمیق فنی و الگوهای طراحی است که در معماری سازمانی سازمان تعبیه شده است.
قطعی در ابر عمومی
در صورت قطع، طراحی BCM قطع ابر باید از در دسترس بودن موارد زیر اطمینان حاصل کند:
- منابعی مانند ذخیره سازی و محاسبه و
- داده ها و برنامه های کاربردی
یک ویژگی خاص ابرها (علاوه بر برنامه های کاربردی SaaS) این است که منطق تجاری و داده ها را به شکل زیر تشکیل می دهند:
- حجم کار زیرساخت به عنوان سرویس (IaaS) با ماشین های مجازی و
- حجم کاری پلتفرم به عنوان سرویس (نه تنها) ذخیره سازی شی یا پایگاه داده به عنوان سرویس را پوشش می دهد.
ابرهای عمومی ویژگی هایی را برای زنده ماندن از قطعی های گسترده تر ارائه می دهند. با این حال، بخشهای فناوری اطلاعات و مدیران ریسک باید مکانیسمها را درک کنند و برای قطعیهای بالقوه ابر عمومی آماده شوند. در ادامه، مفاهیم منتخب Microsoft Azure را بررسی خواهیم کرد، اگرچه ابرهای دیگر، مانند GCP یا AWS، بسیار مشابه هستند.
Azure بین خدمات همیشه روشن منطقه ای، منطقه ای و جهانی تفاوت قائل می شود (شکل 1). یک سرویس منطقه ای در یک مرکز داده اجرا می شود – و نمادین ترین خدمات منطقه ای ماشین های مجازی Azure هستند. اگر شما چنین VM را سفارش دهید، Azure شروع می کند و دقیقاً یکی را به شما اختصاص می دهد. بنابراین، اگر این مرکز داده از کار بیفتد، VM شما از کار می افتد. هیچ اضافه کاری وجود ندارد.

کلاس های خدمات ابری – دیدگاه انعطاف پذیری
خدمات منطقه ای دسته اول خدمات با مقداری افزونگی هستند. بسیاری از سرویس های Azure برای ذخیره داده ها یا پایگاه داده به عنوان یک سرویس ارائه شده در Azure متعلق به این کلاس هستند. آنها (به طور اضافی) در چندین منطقه در یک منطقه اجرا می شوند. به عنوان مثال منطقه لاجوردی زوریخ از سه منطقه در نزدیکی شهر زوریخ تشکیل شده است. رویدادهای محلی مانند سقوط هواپیما به یک مرکز داده خدمات منطقه ای را از بین نمی برد. بنابراین، خدمات منطقه ای می تواند ارائه دهد محدود انعطاف پذیری با این حال، خدمات منطقه ای محافظت در برابر حوادث در مقیاس بزرگ، مانند قطعی برق چند روزه در سراسر سوئیس ارائه نمی دهد.
خدمات جهانی و همیشه روشن مانند DNS یا Azure Active Directory در لیگ دیگری بازی می کنند. Azure در دسترس بودن آنها را تضمین می کند، مهم نیست که در جهان چه اتفاقی می افتد. مشتریان نیازی به برنامه ریزی و آماده سازی برای بازیابی بلایا در صورت قطع شدن ابر جهانی ندارند. فقط یک نکته وجود دارد: خدمات بسیار کمی متعلق به این کلاس است. اکثر آنها فقط منطقه ای یا حتی منطقه ای هستند، به ویژه خدمات مربوط به اجرای کد برنامه و مدیریت داده ها.
آماده شدن برای قطع شدن ابر به معنای متعادل کردن هزینهها برای افزایش انعطافپذیری با احتمال و تأثیر قطعی است. آیا به یک سرویس منطقه ای یا جهانی نیاز دارید – یا یک سرویس منطقه ای (به علاوه مقداری پشتیبان در جای دیگر) کافی است (شکل 2)؟ و آیا تمامی خدمات مورد نیاز و مورد استفاده پاسخگوی این نیازها هستند؟ اگر برنامه باید به کار خود ادامه دهد حتی اگر یک فاجعه منطقه ای وجود داشته باشد، یک برنامه One-VM یک مشکل قابل تشخیص است. این سناریویی است که در آن سرویس SLA و توضیحات سرویس نیازهای تجاری را برآورده نمی کند.

تضمین تاب آوری
افزایش تاب آوری
انعطاف پذیری در مواجهه با خاموشی ابر بسیار مهم است. وقتی یک سرویس نیازهای انعطاف پذیری را برآورده نمی کند، الگوی ساده است: سرویس را در منطقه یا منطقه دیگری کپی کنید. اگر برنامهای که روی یک ماشین مجازی اجرا میشود باید زمانی که مرکز داده میسوزد ادامه دهد، به یک ماشین مجازی در مرکز داده دوم کمی دورتر نیاز دارید. اگر قطع برق منطقه ای در اطراف زوریخ نباید بر برنامه شما تأثیر بگذارد، یک VM در ژنو، فنلاند یا استرالیا اضافه کنید. فقط دو جزئیات را در نظر بگیرید: هزینه ها و مسیریابی مجدد.
داشتن ماشین های مجازی اضافی فقط برای مواقع اضطراری در یک مرکز داده دیگر زوریخ بدون امکان تغییر مسیر درخواست های دریافتی کمکی نمی کند. راه حل: متعادل کننده های بار، که سرویس های منطقه ای هستند که حتی اگر یک مرکز داده در اطراف زوریخ به طور کامل خراب شود، اجرا می شوند. یک سرویس متعادل کننده بار ترافیک را به سمت ماشین های مجازی در مرکز داده باقیمانده هدایت می کند، در صورتی که دستگاهی که VM اولیه دارد خراب باشد. اگر زمانی که کل منطقه از کار می افتد باید ترافیک را تغییر مسیر دهید، سرویس های همیشه روشن مانند DNS یا Azure Front Door انتخاب مناسبی هستند.
برای سهولت یا پیچیدهتر کردن مسائل، خدمات منطقهای منتخب دارای ویژگیهای افزونگی جغرافیایی هستند. به عنوان مثال، سرویس پایگاه داده Azure Cosmos میتواند از پشتیبانگیریها در مناطق مختلف نسخه پشتیبان تهیه کرده و از آنها بازیابی کند (شکل 3، A) – و حتی به مهندسان اجازه میدهد تا این سرویس را به صورت geo-deundant (B) پیکربندی کنند.
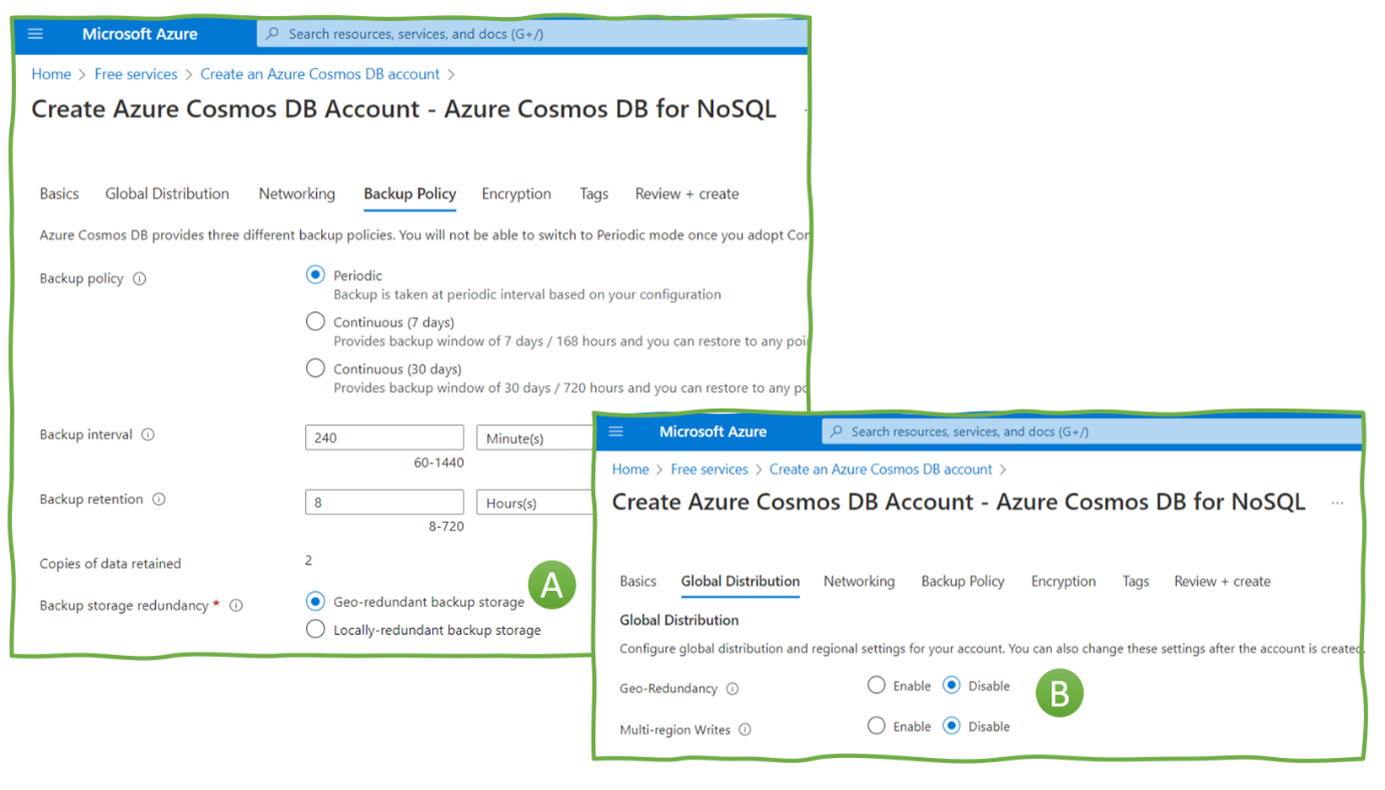
Azure Cosmos DB — ایجاد یک سرویس ابری منطقه ای جغرافیایی زائد
سودمند است که به دو بعد طراحی سیستم های شکست خورده نگاه کنیم: داده ها و ظرفیت منابع (شکل 4). گران ترین طراحی، ظرفیت کامل را برای اجرای عملیات روزانه در دو مرکز داده ایجاد می کند. نیمی از ماشین های مجازی شما (و سایر ظرفیت ها) عملیات روزانه را اجرا می کنند و نیمی دیگر بیکار است، امیدوارم برای همیشه. ظرفیت بیکار فقط برای یک مورد خرابی وجود دارد. به دلیل هزینه ها، شرکت ها چنین معماری هایی را فقط برای حیاتی ترین سیستم ها اجرا می کنند.
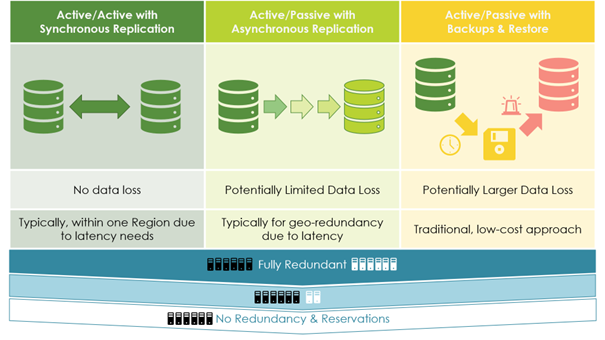
طراحی برای failover در قطع ابر – بعد تکرار و پشتیبان گیری و بعد افزونگی
حالت افراطی دیگر این است که هیچ ظرفیت شکستی را رزرو نکنید. به عبارت دیگر، بخش فناوری اطلاعات شرط میبندد که ارائهدهنده ابر ظرفیت کافی برای موقعیتهای فاجعهبار را دارد – در نتیجه این خطر را میپذیرد که ممکن است هیچ ظرفیتی در دسترس نباشد یا فقط در مراکز داده دوردست با تأخیر بالا در دسترس باشد. هنگامی که این رویکرد را دنبال می کنید، هرگز نباید یک واقعیت را فراموش کنید: یک قطع معمولی ابر هزاران مشتری را تحت تاثیر قرار می دهد. بعید است که ارائه دهندگان ابری ماشین های مجازی غیرفعال یا ظرفیت های خدماتی زیادی در مراکز داده دیگر در همان منطقه داشته باشند که هیچ کس به صورت روزانه به آن نیاز نداشته باشد (و هزینه آن را پرداخت نکند). و، گزینه های زیادی بین این دو حالت وجود دارد، یعنی داشتن منابع تکراری برای همه چیز یا نداشتن رزرو ظرفیت برای هر چیزی.
بعد دوم هنگام طراحی سیستم های failover، در دسترس بودن و به موقع بودن پشتیبان گیری ها و نسخه های مشابه است. دو الگوی اصلی همانندسازی «ناهمزمان» و «همگام» هستند. الگوی اخیر تمام کپی های داده را در مراکز داده مختلف قبل از تأیید موفقیت یک عملیات نوشتن به روز می کند. مزیت کپی همزمان این است که همه کپی های داده همیشه به روز هستند و برنامه ها می توانند در حالت آماده به کار و در مرکز داده دوم (فعال/فعال) فعال باشند.
خرابی مرکز داده باعث از دست رفتن داده یا اختلال در سرویس نمی شود. نقطه ضعف: از دست دادن توان بالقوه به دلیل تأخیر. کندترین مرکز داده میزان خروجی را تعیین می کند. بنابراین، کپیهای همزمان برای کپیهای داخل یک منطقه، به عنوان مثال، مراکز داده مختلف در اطراف زوریخ، معمول هستند، اما نه از زوریخ تا US-East-1 در ویرجینیا. برای دومی، تکرار ناهمزمان یک انتخاب معمولی است.
تکرار ناهمزمان به این معنی است که یک سرویس ابری (یا برنامه شما) بهروزرسانیها را در منطقه محلی انجام میدهد. برنامه در حالی ادامه می یابد که سرویس به روز رسانی ها را به منطقه دیگری در همان قاره یا قاره دیگر ارسال می کند. تأخیر انتشار به روز رسانی به عملکرد برنامه شما آسیبی نمی رساند. با این حال، تغییرات هنوز ارسال نشده در صورت قطعی از بین می روند. سومین، سنتیترین و ارزانترین گزینه، پیکربندی پشتیبانگیریهای دورهای به جای تنظیم تکرار است. در این آخرین سناریو، ابر یک نسخه پشتیبان، به عنوان مثال، هر 4 ساعت یا یک بار در روز انجام می دهد.
بنابراین، انتخابهای تکرار و افزونگی بر میزان موفقیت یک شرکت از قطع شدن مرکز داده ابری یا حتی یک قطع ابر منطقهای تأثیر میگذارد. در واقع، شرکت ها باید روشن کنند که کدام یک از این ریسک ها را می پذیرند و برای کدام یک آماده می شوند. چالش طراحی یک معماری بازیابی فاجعه سازگار در مورد دوم است. سرویسهای ابری با گزینههای افزونگی متفاوتی ارائه میشوند. معماران ابر باید جزئیات برنامه های کاربردی را که بر روی پنج یا ده سرویس ابری ساخته می شوند، حتی اگر همه از یک ارائه دهنده ابر باشند، بررسی کنند تا برای قطع شدن ابر آماده شوند. در پایان، هیئت مدیره انتظار دارد فناوری اطلاعات یکی از وعدههای اصلی بازاریابی ابری را ارائه دهد: عدم قطع سرویس در فضای ابری به لطف ویژگیهای ابری شگفتانگیز برای افزونگی، تکرار و پشتیبانگیری.
درباره نویسنده
 کلاوس هالر به عنوان یک معمار ارشد امنیت فناوری اطلاعات کار می کند. حوزه های تخصص او شامل ابرهای عمومی (Google Cloud Platform و Microsoft Azure) و نحوه ایمن سازی آنها، مدیریت پروژه و پروژه فنی، عملیات فناوری اطلاعات، مدیریت اطلاعات، تجزیه و تحلیل و هوش مصنوعی است. او همچنین نویسنده “مدیریت هوش مصنوعی در سازمان” است.
کلاوس هالر به عنوان یک معمار ارشد امنیت فناوری اطلاعات کار می کند. حوزه های تخصص او شامل ابرهای عمومی (Google Cloud Platform و Microsoft Azure) و نحوه ایمن سازی آنها، مدیریت پروژه و پروژه فنی، عملیات فناوری اطلاعات، مدیریت اطلاعات، تجزیه و تحلیل و هوش مصنوعی است. او همچنین نویسنده “مدیریت هوش مصنوعی در سازمان” است.