



@آرتمگآرتم گوگین
مهندس داده ، معلم و نویسنده فنی.
Apache Hadoop مجموعه ای از برنامه های نرم افزاری منبع باز است که استفاده از شبکه ای از رایانه ها را برای حل مشکلات مربوط به حجم زیاد داده ها و محاسبات تسهیل می کند. © ویکی پدیا
بیایید بررسی کنیم که فضای ذخیره سازی دقیقاً در Hadoop چگونه کار می کند.
تصور کنید که ما باید تعداد زیادی اسناد را ذخیره کنیم ، مانند محاسبه همه کاربران منحصر به فرد و محاسبه کاربران نزدیک به داده های منبع ، محاسبات مربوط به آنها را انجام دهیم. برای تکمیل منظم این عملیات با Hadoop ، ابتدا باید داده ها را در سخت افزار خود ذخیره کنیم.
یک دستگاه
برای شروع ، بیایید ذخیره داده ها را با یک ماشین بدون Hadoop تصور کنیم:
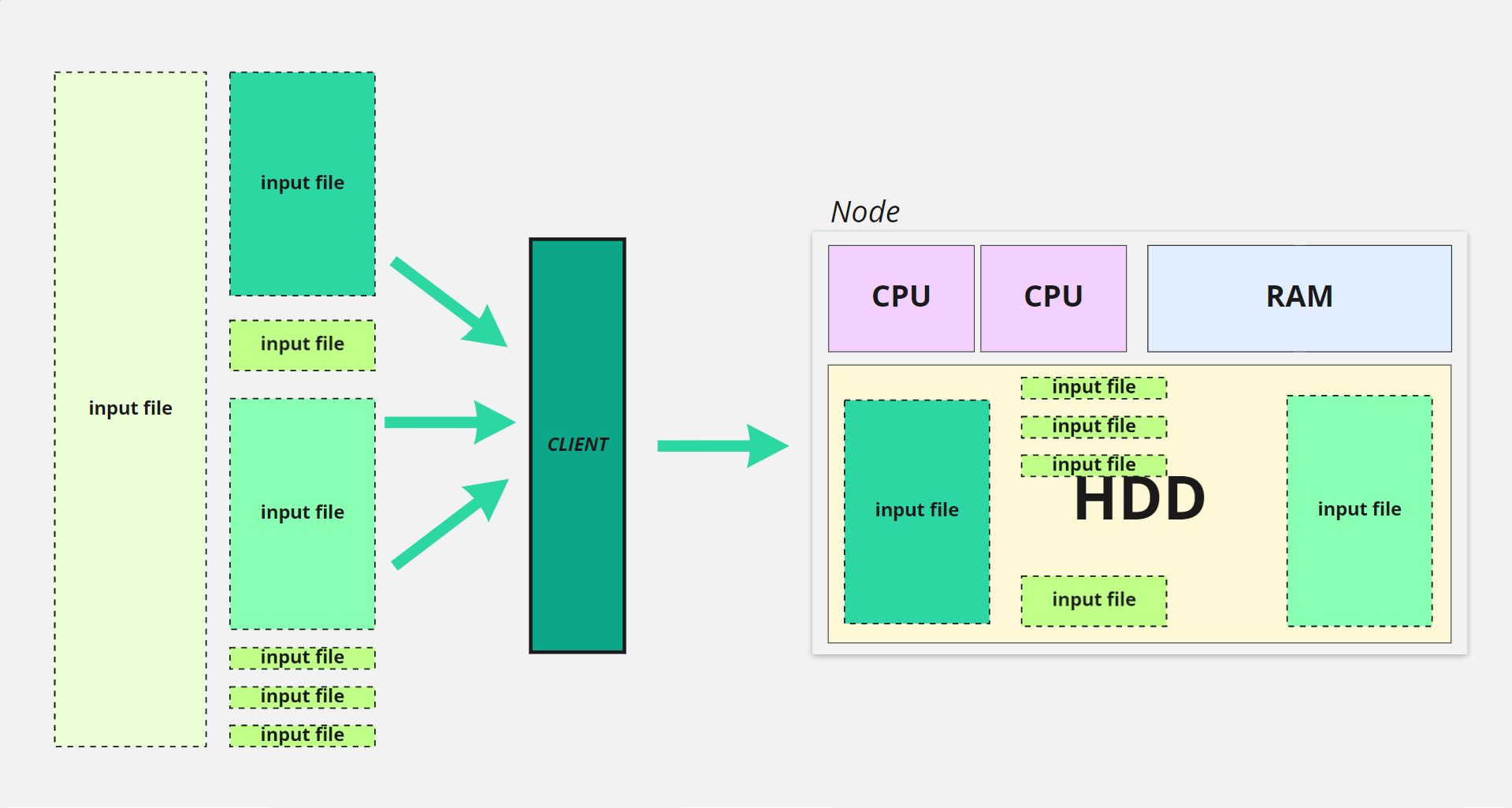
- ذخیره داده ها با یک ماشین
حال ، یک سناریو را تصور کنید که در آن ما باید تعداد زیادی پرونده را مدیریت کنیم. تصور کنید که یک فایل می تواند حتی از HDD یک دستگاه بزرگتر باشد. برای این وضعیت ، ما می توانیم دستگاه خود را با افزودن HDD بیشتر ارتقا دهیم. انجام این کار منجر به موانع زیر می شود:
جا انداختن معیارهای عظیم دارایی در یک ماشین کاملاً هزینه بر است. اگر دستگاه ما به طور غیرمنتظره خراب شود ، دیگر نمی توانیم از پس داده های دیگری برآییم.
چندین ماشین
برای رسیدگی به این مسائل ، باید به سمت تقسیم محاسبات به چند ماشین برویم. برای رسیدن به این هدف ، 3 عدد اضافی اضافه می کنیم …